The gap between proprietary and open source AI models for coding is narrowing fast. A year ago, self-hosting an LLM for development meant settling for significantly worse performance than cloud-based alternatives like GPT-5.4 or Claude. In 2026, the best open source models are closing in on proprietary leaders across independent benchmarks like Artificial Analysis and LiveBench, and some even outperform them on specific tasks like code generation and completion.
Whether you’re a solo developer who wants to keep code off third-party servers, a startup looking to cut API costs, or an enterprise with strict data compliance requirements, self-hosted open source LLMs have become a genuinely viable option for professional software development. In this guide, we’ll cover the best open source models you can self-host for coding, the tools to deploy them, and the hardware you need to get started.
Summary
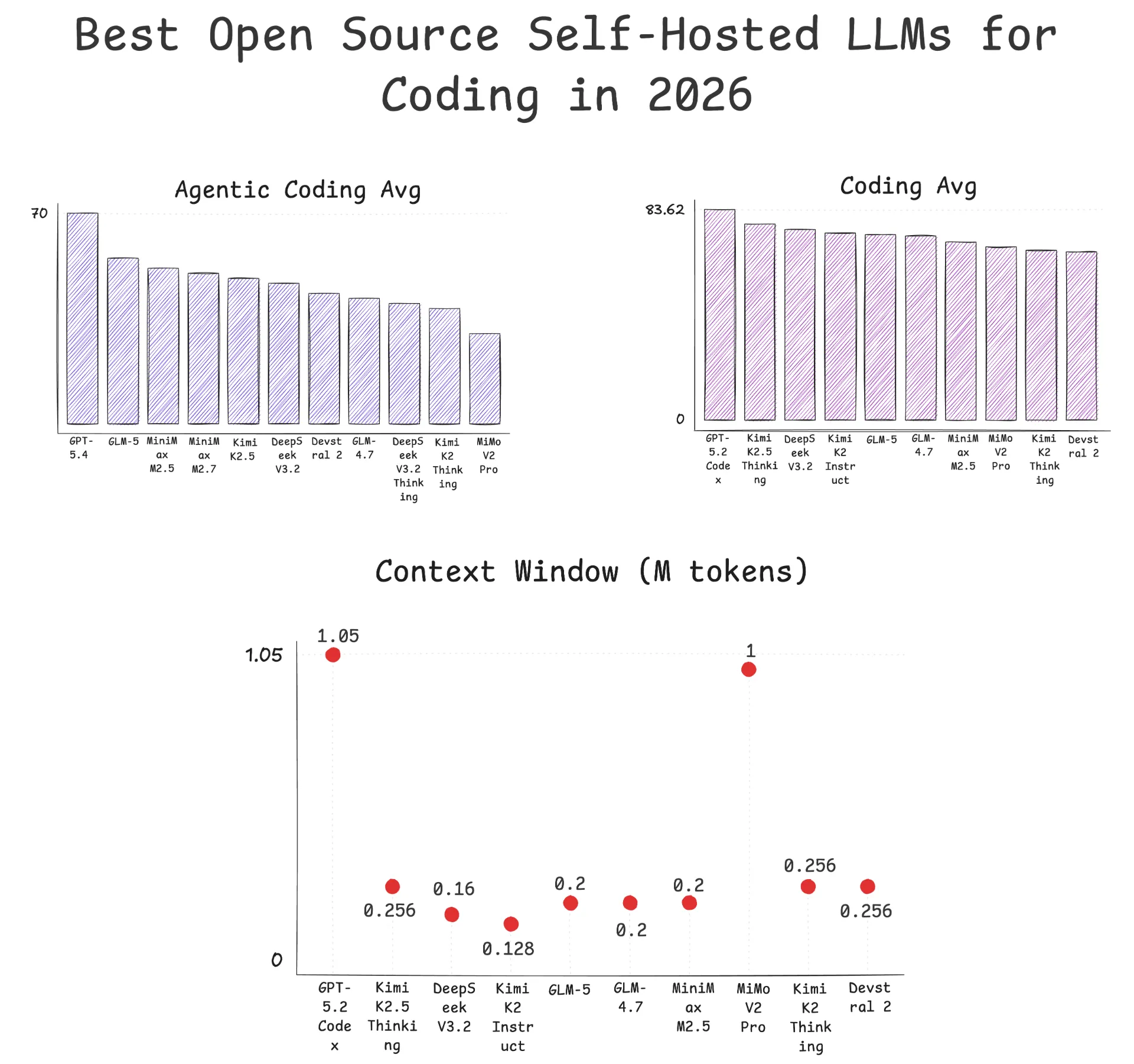
Top Open Source LLMs for Coding (Self-Hostable, ranked by LiveBench Agentic Coding Avg):
- Kimi K3 - LiveBench Coding 81.45, Agentic Coding 57.58 - Get Kimi K3
- GLM 5.2 - LiveBench Coding 79.65, Agentic Coding 51.92 - Get GLM-5.2
- DeepSeek V4 Pro - LiveBench Coding 69.99, Agentic Coding 42.63 - Get DeepSeek-V4-Pro
- MiniMax M3 - LiveBench Coding 68.20, Agentic Coding 40.66 - Get MiniMax M3
- Qwen 3.6 27B - LiveBench Coding 71.78, Agentic Coding 39.29 - Get Qwen 3.6 27B
Also worth self-hosting (not in LiveBench’s current rotation, scored on other benchmarks):
- DeepSeek-V4-Pro-Max - SWE-Bench Verified 80.6%, 1.6T/49B active - Get DeepSeek-V4-Pro-Max
- MiMo-V2.5-Pro - vendor SWE-Bench Verified 78.9% - Get MiMo-V2.5-Pro
- Devstral 2 - LiveBench Coding 66.79, Agentic Coding 43.33 - Get Devstral 2
Kimi K3 weights are out, but they need a cluster: Moonshot published the 2.8T MoE flagship on July 27, 2026. It’s the #1 open-weight model on LiveBench’s Coding Avg (81.45) and Agentic Coding Avg (57.58), but at ~1.4 TB of MXFP4 weights it does not fit any single 8-GPU node, and it ships under a bespoke license rather than MIT. If you want the best model that fits one server, that’s still GLM-5.2 - see the Kimi K3 section below.
Best Self-Hosting Tools:
Open Source vs Proprietary: How Close Is the Gap?
Before diving into individual models, it’s worth understanding where open source stands. We use Artificial Analysis as the primary lens here because it’s independent and covers the full June-July 2026 wave, including the just-released Kimi K3. Its Intelligence Index aggregates provider-reported and benchmark-derived signals into one number. We cross-check it against SWE-Bench Pro (coding-specific) and LiveBench (contamination-aware) further down. The snapshot below is July 2026.
Artificial Analysis Intelligence Index (July 2026, open weights)
| Model | Organization | Intelligence Index | Hardware requirement |
|---|---|---|---|
| Claude Fable 5 | Anthropic | 60 | Proprietary, no self-host |
| Kimi K3 | Moonshot AI | 57 | Multi-node cluster, 64+ accelerators (~1.4 TB at MXFP4) |
| GLM 5.2 | Z.AI | 51.1 | 4x H100/H200 80GB (~370 GB) |
| MiniMax M3 | MiniMax | 44.4 | 3-4x H100 80GB (~233 GB) |
| DeepSeek V4 Pro | DeepSeek | 44.3 | 8x H100/H200 80GB (~430 GB) |
| MiMo-V2.5-Pro | Xiaomi | 42.2 | 8x H100/H200 80GB (~550 GB) |
| Qwen3.6 35B-A3B | Alibaba | 32.0 | Single 24GB GPU or 32GB Mac (~20 GB) |
The Hardware requirement column is the approximate VRAM just for 4-bit weights (INT4/Q4, or MXFP4 in Kimi K3’s case) and the smallest 80GB-class multi-GPU box that fits them, from each model’s community and vendor deployment notes ( GLM-5.2, MiniMax M3, DeepSeek V4, Kimi K3). Three caveats: add headroom on top for the KV cache, which balloons at these models’ 1M context lengths; none of these run on a single consumer GPU; and Kimi K3 is in a different class entirely, since ~1.4 TB of weights does not fit the 640 GB of an 8x80GB node no matter how you shard it. If a single server is your ceiling, GLM-5.2 is the practical top end. If a laptop or a single consumer GPU is your budget, the practical models section below has the full list that fits - Devstral Small 2 (24B) and Qwen 3.6 27B run on a single RTX 4090 or a 32GB Mac. You can also trade GPUs for large CPU RAM with GGUF builds, at much lower speed.
On Artificial Analysis, the actual frontier leader is Anthropic’s Claude Fable 5 at 60 - the current #1 model on the whole index. Kimi K3 is close behind at 57, ahead of Claude Opus 4.8 (56), and since July 27 it is a model you can download - if you have a cluster to put it on. GLM-5.2 at 51.1 is the leader among models that fit a single node, ahead of the tight 42-44 cluster of MiniMax M3, DeepSeek V4 Pro, and MiMo-V2.5-Pro. Fable 5’s lead over the best open weights is now 3 points, not the chasm it was a year ago. On AA’s real-world agentic benchmark (GDPval-AA v2), GLM-5.2 scores 1524, effectively level with GPT-5.5 xHigh (1514). At the small end, Qwen3.6-35B-A3B trails at 32 but is one of the models you can actually run on a laptop, which is the subject of the next section. The two cross-checks further down tell the same story.
Practical models you can actually self-host
Every model in the table above except Qwen3.6 needs a rack. If your “server” is the laptop you’re reading this on, the ceiling is Apple’s: the M5 Max MacBook Pro announced in March 2026 tops out at 128GB of unified memory at 614GB/s, and that has to hold the weights plus the KV cache. At 4-bit that puts the cutoff around 125B total parameters.
Here is everything that clears it, scored on the same Artificial Analysis Intelligence Index as the table above, so you can read these numbers directly against Kimi K3’s 57 and Claude Fable 5’s 60. Scores come from AA’s small (4B-40B) and medium (40B-150B) open-weights boards.
| Model | Total / active params | ~4-bit footprint | Intelligence Index |
|---|---|---|---|
| Qwen3.6 27B | 27.8B dense | ~17 GB | 37 |
| Qwen3.6 35B-A3B | 36B / 3B | ~20 GB | 32 |
| Qwen3.5 122B-A10B | 125B / 10B | ~70 GB | 32 |
| Mistral Medium 3.5 | 128B dense | ~72 GB | 30 |
| Gemma 4 31B | 30.7B dense | ~18 GB | 29 |
| Nemotron 3 Super 120B-A12B | 120.6B / 12.7B | ~68 GB | 25 |
| gpt-oss-120b (high) | 117B / 5.1B | ~63 GB | 24 |
| Qwen3-Coder-Next | 79.7B / 3B | ~45 GB | 21 |
The useful surprise here is that bigger does not win on a laptop. Qwen3.6 27B tops this table at 37 and AA ranks it #1 of 130 in its size class - it beats every 120B-class model that also fits, including Qwen3.5 122B-A10B (32), Mistral Medium 3.5 (30), Nemotron 3 Super (25), and gpt-oss-120b (24). It’s also the cheapest to run of the lot at ~17 GB, which leaves most of a 128GB machine free for KV cache at its 262K context. If you only take one recommendation from this section: pull the 27B, not the biggest thing that fits.
Two caveats. AA publishes reasoning and non-reasoning variants separately, and this table uses the reasoning score wherever one exists - Qwen3-Coder-Next and Mistral Medium 3.5 are scored non-reasoning only, so the bottom rows aren’t a strict like-for-like read. And the two Mistral models the rest of this guide covers score lower on this index than their SWE-bench numbers suggest: Devstral 2 sits at 19 and Devstral Small 2 at 17 (both non-reasoning), as does Nemotron-Cascade 2 30B-A3B at 18.
What does not fit: GLM-5.2. Unsloth’s 2-bit dynamic GGUF squeezes it from ~1.51 TB to ~239 GB, which needs a 256GB Mac Studio rather than any MacBook Pro, and 2-bit is a real quality cut on top. Kimi K3 is further out of reach again.
LiveBench (secondary cross-check, July 2026)
LiveBench refreshed its question set on June 25, 2026, part of its normal contamination-aware monthly rotation - absolute scores read lower across the board than in older snapshots, so rankings within a single snapshot are the meaningful comparison, not the raw numbers year over year. Two models covered later in this guide are missing from the table below: Devstral 2 dropped out of the current rotation, and MiMo-V2.5-Pro has never been covered. Kimi K3 and MiniMax M3 are newly added.
LiveBench Agentic Coding Average
| Model | Organization | Type | Agentic Coding Avg |
|---|---|---|---|
| GPT-5.6 Terra Max Effort | OpenAI | Proprietary | 67.98 |
| Kimi K3 | Moonshot AI | Open weights (bespoke license) | 57.58 |
| GLM 5.2 | Z.AI | Open Source | 51.92 |
| DeepSeek V4 Pro | DeepSeek | Open Source | 42.63 |
| MiniMax M3 | MiniMax | Open Source | 40.66 |
| Qwen 3.6 27B | Alibaba | Open Source | 39.29 |
GPT-5.6 Terra Max Effort leads the whole table at 67.98 - the actual current #1 on LiveBench’s Agentic Coding leaderboard. Kimi K3 is the top open-weight entry at 57.58, well clear of GLM-5.2, though still behind Terra Max, GPT-5.6 Sol Max (65.61), Muse Spark 1.1 xHigh (65.05), and Grok 4.5 (59.8). As of July 27 you can download K3’s weights, so this is now a self-hostable row - just not on hardware most teams have. GLM-5.2 remains the best score you can reach on a single node, at 51.92 Agentic Coding Avg and 79.65 Coding Avg, roughly 6 points of agentic score behind K3.
For the latest scores and full model list, visit the LiveBench leaderboard directly.
SWE-Bench Pro (coding-specific cross-check)
SWE-Bench Pro is the coding-specific benchmark that does cover the June releases, so it’s the best head-to-head on code tasks alone. GLM-5.2 tops the open-weight field here, with the June releases clustered just behind. Kimi K3 doesn’t appear in this table - Moonshot didn’t report a SWE-Bench Pro number for it, publishing Terminal-Bench 2.1, FrontierSWE, Program Bench, DeepSWE, and SWE Marathon instead (see the Kimi K3 section below).
| Model | Organization | Released | SWE-Bench Pro |
|---|---|---|---|
| GLM 5.2 | Z.AI | Jun 2026 | 62.1 |
| MiniMax M3 | MiniMax | Jun 1, 2026 | 59.0 |
| DeepSeek-V4-Pro-Max | DeepSeek | Apr 24, 2026 | 55.4 |
DeepSeek-V4-Pro-Max sits lower on SWE-Bench Pro but leads open weights on the older SWE-Bench Verified at 80.6% (tied with Gemini 3.1 Pro) and posts 93.5% on LiveCodeBench, so its ranking depends heavily on which benchmark you weight. Several of these are self-reported by the vendor; treat them as directional until LiveBench and other independent evaluations catch up.
Best Open Source LLMs for Coding
The ranking below is by LiveBench’s current Agentic Coding Average among models you can actually self-host. Kimi K3 takes the top slot on scores, but read its hardware and license notes before you plan around it - for most teams the real decision starts at GLM-5.2.
1. Kimi K3 (Moonshot AI) - Top Open-Weight Scores, Cluster Required
Moonshot AI announced Kimi K3 on July 16, 2026 and published the weights on Hugging Face on July 27, 2026, along with a technical report and three of the infrastructure tools used to train it. At 2.8 trillion total parameters it is the largest open-weight model released to date, and it hit the top of Hugging Face’s trending chart within half an hour of going live.
The architecture is a “Stable LatentMoE” design with 896 experts, 16 of which activate per token for 104B active parameters. It runs 93 layers (69 Kimi Delta Attention plus 24 Gated MLA), a 160K vocabulary, and a MoonViT-V2 vision encoder (401M) for native image understanding. Kimi Delta Attention and Attention Residuals support a full 1M-token context window, four times the 256K window of the K2 line. Moonshot credits its MoonEP communication library with a 2.5x gain in scaling efficiency over the previous generation.
Two things to check before you plan around it. First, hardware: the weights are natively MXFP4 (with MXFP8 activations) from quantization-aware training, which is already the compact form - about 1.4 TB resident, from a ~1.56 TB repository spread over 118 files. That does not fit the 640 GB in an 8x80GB H100 or H200 node, so there is no single-server deployment and no meaningful further quantization headroom. Moonshot recommends a supernode of 64 or more accelerators. Supported engines are vLLM, SGLang, and TokenSpeed.
Second, the license. K3 does not ship under the Modified MIT terms the K2 line used. It carries a bespoke Kimi K3 License (tagged license:other on Hugging Face) that permits download, self-hosting, fine-tuning, and quantization, and fully exempts internal use never exposed to third parties. But Model-as-a-Service operators whose group revenue exceeds $20M over any consecutive 12 months must sign a separate agreement with Moonshot before commercial use, and products above 100M monthly active users or $20M monthly revenue must prominently display “Kimi K3” in the UI. Fine for internal developer tooling; read it properly if you plan to resell inference.
On Moonshot’s own benchmarks, K3 posts 88.3 on Terminal-Bench 2.1, 81.2 on FrontierSWE, 77.8 on Program Bench, 67.5 on DeepSWE, and 42.0 on SWE Marathon. On LMArena’s Frontend Code Arena, K3 debuted at #1 with 1,679 points, ahead of Claude Fable 5 (1,631) and GPT-5.6 Sol (1,618). That said, across the wider set of published head-to-head benchmarks Fable 5 still wins more often than it loses to K3, so treat the Frontend Code Arena result as a genuine win on that specific task rather than overall superiority. LiveBench independently confirms the ranking, where it’s the #1 open-weight model on both Coding Avg (81.45) and Agentic Coding Avg (57.58) - though GPT-5.6 Terra Max Effort (67.98 Agentic) and other proprietary models still lead the overall leaderboard. If you would rather rent than run it, API pricing is $3 per million input tokens ($0.30 on a cache hit) and $15 per million output tokens.
Key Specs - Kimi K3 (July 2026)
- Architecture: MoE (“Stable LatentMoE”), 2.8T total / 104B active parameters, 896 experts with 16 active per token, 93 layers (69 KDA + 24 Gated MLA)
- Context Window: 1M tokens (Kimi Delta Attention); native vision via MoonViT-V2
- License: Kimi K3 License (bespoke; self-hosting and fine-tuning allowed, revenue-triggered agreement for MaaS resale)
- Weight format: MXFP4 weights / MXFP8 activations from quantization-aware training, ~1.4 TB resident
- Terminal-Bench 2.1: 88.3 (self-reported by Moonshot AI)
- FrontierSWE: 81.2 (self-reported by Moonshot AI)
- SWE-Bench Pro: Not reported by Moonshot (they published Program Bench, DeepSWE, and SWE Marathon instead)
- Artificial Analysis Intelligence Index: 57 (independently scored, #1 open-weight in this guide; edges out Claude Opus 4.8’s 56, but trails Claude Fable 5’s 60)
- LiveBench Coding Avg: 81.45 (independently scored, #1 open-weight in this guide)
- LiveBench Agentic Coding Avg: 57.58 (independently scored, #1 open-weight in this guide; trails proprietary leader GPT-5.6 Terra Max Effort at 67.98)
- API pricing: $3/M input tokens ($0.30/M cache hit), $15/M output tokens
- Self-hosting: vLLM, SGLang, or TokenSpeed; multi-node cluster required (Moonshot suggests 64+ accelerators) - no single 8-GPU node fits it
2. GLM-5.2 (Z.AI) - Best Model That Fits One Server

GLM-5.2 (June 2026) from Z.AI is the most competitive coding model that actually fits a single multi-GPU server, and it’s MIT licensed with no revenue clauses attached. It runs a 1M-token context and was the first open-weight model to beat GPT-5.5 on SWE-Bench Pro. Unless you have a 64-GPU cluster for Kimi K3, this is the practical top of the self-hostable field.
What makes this family particularly noteworthy is its training infrastructure. The GLM-5 generation was trained on 100,000 Huawei Ascend 910B chips rather than NVIDIA GPUs - a significant milestone for non-NVIDIA AI hardware. Z.AI also introduced a novel reinforcement learning infrastructure called “Slime” that reduced hallucination rates from 90% to 34%, and GLM-5.2 adds anti-hack mechanisms in RL training specifically for coding agents.
GLM-5.2’s architecture introduces IndexShare, which reuses the sparse attention indexer across every four sparse attention layers - cutting per-token FLOPs by 2.9x at 1M context length without sacrificing quality. An improved MTP layer increases speculative decoding acceptance length by up to 20%. It also adds two selectable thinking modes: Max for maximum reasoning depth and High for a better latency/quality tradeoff.
On coding benchmarks, GLM-5.2 scores 79.65 Coding Avg and 51.92 Agentic Coding Avg on LiveBench - second only to Kimi K3 among open weights, and the highest you can reach without a cluster. On SWE-Bench Pro it posts 62.1 (above GPT-5.5’s 58.6), 81.0 on Terminal-Bench 2.1, 74.4 on FrontierSWE (vs Claude Opus 4.8’s 75.1 and GPT-5.5’s 72.6), and 76.8 on MCP-Atlas (vs GPT-5.5’s 75.3). Artificial Analysis agrees on the ordering: 51.1 on its Intelligence Index, ahead of MiniMax M3 and DeepSeek V4 Pro at 44 and behind only Kimi K3 at 57, plus 1524 on the real-world GDPval-AA v2 agentic benchmark, effectively level with GPT-5.5 xHigh.
Key Specs - GLM-5.2 (June 2026)
- Architecture: MoE, 753B total / 40B active parameters
- Context Window: 1M tokens
- License: MIT
- SWE-Bench Pro: 62.1 (self-reported by Z.AI; beats GPT-5.5 at 58.6)
- Terminal-Bench 2.1: 81.0 (self-reported by Z.AI)
- FrontierSWE: 74.4 (self-reported by Z.AI)
- MCP-Atlas: 76.8 (self-reported by Z.AI)
- LiveBench Coding Avg: 79.65
- LiveBench Agentic Coding Avg: 51.92 (highest of any single-node self-hostable model in this guide)
- Self-hosting: vLLM (v0.23.0+), SGLang (v0.5.13.post1+), KTransformers, Transformers; weights on Hugging Face and ModelScope; roughly 4x H100/H200 80GB for 4-bit weights
3. MiniMax M3 (MiniMax) - Best Long Context + Multimodal
MiniMax M3 shipped on June 1, 2026, combining frontier coding performance, a 1M-token context, and native multimodal input in a single architecture (weights followed within about ten days of the API launch). Its headline feature is MSA (MiniMax Sparse Attention), which partitions the KV cache into blocks so each block is read only once - MiniMax says this delivers more than 4x faster attention than Flash-Sparse-Attention style implementations and much faster prefill at long context. It’s reported at roughly 428B parameters, served through vLLM and SGLang.
Vendor benchmarks report 59.0% SWE-Bench Pro, 66.0% Terminal-Bench 2.1, and 74.2% MCP-Atlas. On LiveBench it scores 68.20 Coding Avg and 40.66 Agentic Coding Avg - solidly mid-pack among self-hostable models, but it’s the only one in this guide combining that context length with native image input.
Key Specs
- Architecture: MoE, ~428B total parameters (MiniMax Sparse Attention)
- Context Window: 1M tokens, native multimodal input
- SWE-Bench Pro: 59.0% (self-reported by MiniMax)
- Terminal-Bench 2.1: 66.0% (self-reported by MiniMax)
- MCP-Atlas: 74.2% (self-reported by MiniMax)
- LiveBench Coding Avg: 68.20
- LiveBench Agentic Coding Avg: 40.66
- Self-hosting: vLLM or SGLang; roughly 3-4x H100 80GB (~233 GB) for 4-bit weights
4. DeepSeek V4 Pro / V4-Pro-Max (DeepSeek) - Best Cost-to-Quality
DeepSeek shipped DeepSeek-V4 on April 24, 2026 in two variants: V4-Pro (1.6T total / 49B active) and V4-Flash (284B total / 13B active), both 1M context, MIT-licensed. It’s still the current DeepSeek generation - the company has not announced a V5, and V4-Flash is the cheap workhorse of this guide.
The higher-effort V4-Pro-Max configuration leads open weights on SWE-Bench Verified at 80.6% (tied with Gemini 3.1 Pro) and posts 93.5% on LiveCodeBench, though on the stricter SWE-Bench Pro it lands at 55.4, behind GLM-5.2 and MiniMax M3. On LiveBench, V4-Pro scores 69.99 Coding Avg / 42.63 Agentic Coding Avg (V4-Flash trails at 69.23 / 37.63) - so V4-Flash gives up surprisingly little agentic coding quality for a fifth of the parameters, which is the real argument for this family.
Key Specs
- Architecture: MoE, 1.6T total / 49B active (V4-Pro); 284B total / 13B active (V4-Flash)
- Context Window: 1M tokens
- License: MIT
- SWE-Bench Verified: 80.6% (V4-Pro-Max, self-reported; tied for top open-weight)
- SWE-Bench Pro: 55.4 (V4-Pro-Max, self-reported)
- LiveCodeBench: 93.5% (V4-Pro-Max, self-reported)
- LiveBench Coding Avg: 69.99 (V4-Pro); 69.23 (V4-Flash)
- LiveBench Agentic Coding Avg: 42.63 (V4-Pro); 37.63 (V4-Flash)
- Self-hosting: V4-Pro needs roughly 8x H100/H200 80GB for 4-bit weights; V4-Flash is far lighter at 284B total
5. Devstral 2 (Mistral AI) - Best for Vibe CLI Workflows
Devstral 2 from Mistral AI is a 123 billion parameter model specifically designed for agentic software engineering. Released in December 2025, it scores 72.2% on SWE-bench Verified with a 256K context window and, on its last LiveBench snapshot, 66.79 Coding Avg / 43.33 Agentic Coding Avg. Mistral describes it as 7x more cost-efficient than Claude Sonnet, and at 123B dense it is an order of magnitude smaller than the trillion-scale MoE models above while staying competitive on benchmarks. It’s the oldest model in this list, so treat it as a size/efficiency pick rather than a frontier one.
What makes the Devstral family compelling for self-hosting is the smaller sibling, Devstral Small 2 (24B parameters), which scores an impressive 68% on SWE-bench Verified. That’s remarkable for a model that runs on a single RTX 4090 or a Mac with 32GB of RAM. It also supports image inputs and comes with Apache 2.0 licensing, making it one of the most permissive options available. Mistral also offers Vibe CLI, an open source terminal coding assistant powered by Devstral, giving you a ready-made development workflow out of the box.
Key Specs (Devstral 2)
- Parameters: 123B
- Context Window: 256K tokens
- License: Modified MIT
- LiveBench Coding Avg: 66.79 (last scored before dropping off LiveBench’s active rotation)
- LiveBench Agentic Coding Avg: 43.33 (last scored before dropping off LiveBench’s active rotation)
- SWE-bench Verified: 72.2% (self-reported by Mistral AI)
- Self-hosting: Multi-GPU recommended for full model
Key Specs (Devstral Small 2)
- Parameters: 24B
- Context Window: 128K tokens
- License: Apache 2.0
- SWE-bench Verified: 68.0% (self-reported by Mistral AI)
- Self-hosting: Single RTX 4090 or Mac with 32GB RAM
6. MiMo-V2.5-Pro (Xiaomi) - 78.9% SWE-Bench, 68.4% TerminalBench

MiMo-V2.5-Pro is Xiaomi’s latest open-weight model, released on April 22, 2026. It’s a 1.02T total parameter MoE model with 42B active parameters and a 1M token context window - broadly comparable in scale to DeepSeek-V4 Pro. Weights are on Hugging Face and ModelScope under the MIT license.
MiMo-V2.5-Pro isn’t on LiveBench, so a direct side-by-side comparison with the other models in this guide isn’t possible. On vendor-reported benchmarks, it posts 78.9% on SWE-Bench Verified and 68.4% on TerminalBench 2.0, just behind GLM-5.2’s 81.0 on the newer TerminalBench 2.1. These are self-reported numbers from Xiaomi; treat them as directional until independent evaluations confirm them. Artificial Analysis does score it independently, at 42.2 on the Intelligence Index.
The architecture uses a hybrid attention design that interleaves local sliding window attention with global attention at a 6:1 ratio, which Xiaomi says cuts KV-cache memory usage by roughly 7x compared to full attention at long contexts. Three lightweight Multi-Token Prediction modules enable a 3x inference speedup. For self-hosting, SGLang is the recommended inference engine; the model requires a significant multi-GPU setup similar to other ~1T MoE models in this guide. Xiaomi pitches it at agentic and software engineering work, with support for workflows involving more than 1,000 sequential tool calls.
Key Specs
- Architecture: MoE, 1.02T total / 42B active parameters
- Context Window: 1M tokens
- License: MIT
- SWE-Bench Verified: 78.9% ( self-reported by Xiaomi)
- TerminalBench 2.0: 68.4% ( self-reported by Xiaomi)
- LiveBench: Not covered
- Self-hosting: SGLang or vLLM; multi-GPU setup required (similar footprint to DeepSeek V4 Pro)
7. Qwen 3.6 / Qwen3-Coder-Next (Alibaba) - Best on a Single GPU
The general-purpose Qwen 3.6 line (a 27B dense variant and the 35B-A3B MoE, both Apache 2.0, both released April 2026) is what shows up in this guide’s LiveBench and Quick Decision tables: 71.78 Coding Avg / 39.29 Agentic Coding Avg for the 27B, which makes it the best self-hostable option that fits a single consumer GPU. Nothing else in this guide comes close on that constraint.
On the coding-specialized side, Qwen3-Coder-Next (80B total, 3B active) combines hybrid attention with MoE and scores 70.6% on SWE-bench Verified from only 3B active parameters - the best efficiency-per-active-parameter story here. Alibaba also provides Qwen Code, an open source terminal coding agent optimized for the Qwen models, so you get a working agent workflow without wiring one up yourself.
Key Specs
- Architecture: Dense 27B or MoE 35B-A3B (Qwen 3.6); MoE 80B total / 3B active (Qwen3-Coder-Next)
- License: Apache 2.0
- SWE-bench Verified: 70.6% (Qwen3-Coder-Next, self-reported by Alibaba)
- LiveBench Coding Avg: 71.78 (Qwen 3.6 27B)
- LiveBench Agentic Coding Avg: 39.29 (Qwen 3.6 27B)
- Self-hosting: Qwen 3.6 27B runs on a single 24GB GPU or a 32GB Mac via Ollama; Qwen3-Coder-Next needs more headroom despite its 3B active count
8. StarCoder 2 (BigCode / Hugging Face) - Most Auditable Training Data
StarCoder 2 is a collaboration between Hugging Face and ServiceNow under the BigCode project. Available in 3B, 7B, and 15B sizes, it was trained on 3.3 to 4.3 trillion tokens from The Stack v2, covering 619 programming languages. It uses Grouped Query Attention with a 16K context window.
StarCoder 2’s standout quality is its data transparency. Every training data source is documented with Software Heritage Identifiers (SWHIDs), making it the most auditable coding model available. This matters for enterprises concerned about IP and licensing compliance. The 15B model matches or outperforms CodeLlama 34B (a model twice its size), demonstrating strong efficiency.
While it doesn’t compete with the larger MoE models on raw benchmarks, StarCoder 2 remains an excellent choice for teams that need a lightweight, well-documented coding model they can run on modest hardware.
Key Specs
- Sizes: 3B, 7B, 15B
- Context Window: 16K tokens
- License: OpenRAIL (fully transparent training data)
- Self-hosting: Runs on consumer hardware via Ollama; 3B variant works on laptops
Honorable Mentions
Several other open source models deserve recognition for specific strengths:
- IBM Granite Code - Available from 350M to 34B parameters under Apache 2.0, trained on 116 programming languages with license-permissible data. Granite 4.0 introduces hybrid Mamba-2/transformer architecture using 70% less memory. Best choice for enterprise compliance.
- NVIDIA Nemotron-Cascade 2 - A 30B MoE with only 3B active parameters that achieves Gold Medal-level performance on competitive programming benchmarks (IMO, IOI, ICPC) with 20x fewer parameters than comparable models. Remarkable efficiency.

- Yi-Coder - From 01.AI, available in 1.5B and 9B sizes with 128K context and Apache 2.0 license. Yi-Coder 9B scores 85.4% on HumanEval, on par with DeepSeek Coder 33B at a fraction of the size.
How to Use These Models with a Coding Agent
If you want a Claude Code or Aider-style workflow with self-hosted models, one of the easiest setups is OpenCode + Ollama. This combination gives you a local coding agent with a simple terminal workflow and no cloud dependency.
Easiest Setup: OpenCode + Ollama
If you’re using Ollama’s built-in Applications flow, the setup is even simpler. The current Qwen 3.6 Ollama page lists a direct OpenCode launch command.
Step 1: Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
Step 2: Install OpenCode
curl -fsSL https://opencode.ai/install | bash
Step 3: Launch OpenCode directly through Ollama Applications
ollama launch opencode --model qwen3.6:35b-a3b
Step 4: Open your project and start working
Once OpenCode starts, point it at your repository and use it like any other terminal coding agent for explaining code, refactoring files, writing tests, or implementing features.
If you want a smaller local footprint, Ollama also provides smaller Qwen 3.6 variants (for example 27B-class options). Check the live Ollama model page for currently available tags.
Why This Setup Works Well
- Fastest setup path because Ollama can launch OpenCode directly as an application
- Runs fully local with no separate model gateway to configure
- Easy to scale up or down by swapping the Ollama model tag based on your hardware
How to Self-Host These Models Locally
Once you’ve picked a model, you need the right tools and hardware to run it. We’ve covered this extensively in our previous guides:
- How to Self-Host Any LLM - Step by Step Guide - A complete walkthrough covering installation, model download, quantization, GPU setup, and connecting to your development tools.
- Top 5 Local LLM Tools and Models - A detailed comparison of Ollama, vLLM, llama.cpp, LM Studio, and other self-hosting tools with hardware requirements and performance benchmarks.
Quick Decision Guide
| Your Need | Recommended Model | Why |
|---|---|---|
| Best raw benchmark score (cluster required) | Kimi K3 | Tops LiveBench among open-weight models at 81.45 Coding Avg and 57.58 Agentic Coding Avg, but needs 64+ accelerators and a bespoke license |
| Best overall coding on one server | GLM-5.2 | Highest single-node scores on LiveBench (79.65 Coding, 51.92 Agentic), MIT licensed, fits ~4x H100 |
| Best on consumer hardware | Qwen 3.6 27B or Devstral Small 2 | Solid coding scores with much smaller deployment footprint than trillion-scale models |
| Best tiny model (<10B) | Yi-Coder 9B or StarCoder2-3B | Runs on laptops, punches above weight |
| Best for agentic workflows | GLM-5.2 | Top single-node agentic coding score plus long-horizon execution and anti-hack RL training for coding agents |
| Best long context + multimodal | MiniMax M3 | 1M-token context and native image input in one open-weight model |
| Best for enterprise compliance | IBM Granite Code | Apache 2.0, ethics-vetted training data |
| Best efficiency per parameter | Qwen3.6-35B-A3B | Strong coding-agent scores from only 3B active parameters |
Conclusion
Kimi K3 now holds the top open-weight scores on every independent benchmark we checked, and since July 27, 2026 its weights are public - but at ~1.4 TB it needs a multi-node cluster and ships under a bespoke license with a revenue trigger, so for most teams it’s an API model that happens to be downloadable. GLM-5.2 is the one to actually deploy: best scores of anything that fits a single server, MIT licensed, roughly 4x H100.
For most developers: start with Qwen 3.6 27B or Devstral Small 2 on local hardware, move to GLM-5.2 when you have a GPU server and want top-tier agentic work, and reach for Kimi K3 only if you have the cluster or are happy calling the API. Self-hosted open source models are production-ready for coding, and with the best open weights now 3 points off the top of the Artificial Analysis index, the gap with proprietary models keeps shrinking.