A user from South Korea brought to our attention that Pinggy works great for them, but it is slow. The answer to “why” was obvious to us. Pinggy was hosting its servers in the USA, specifically in Ohio. One key goal of Pinggy is to provide not only tunnels but fast and reliable tunnels. To improve the situation, we decided to host the tunnels in the region nearest to where the user is creating the tunnel from (as the default behavior).
Today, Pinggy is hosted across five regions: US, Europe, and Asia, Australia, and South America.
Running servers in three (now five) regions is the easy part. The hard part is DNS. The moment a tunnel comes up in, say, Frankfurt, its domain has to point at the Frankfurt edge, and it has to do so fast enough that the very first visitor does not get a stale record from a minute ago or, worse, no record at all. That single requirement is what pushed us off a managed DNS provider and onto our own PowerDNS fleet. Most of this post is about that.
To scale across multiple regions, we did the following:
- Spawn edge nodes in multiple regions.
- Host our own DNS server to dynamically point tunnel traffic to the correct edge.
- Use AWS Route 53 for latency-based routing.
- Implement a central coordinator to handle authentication, sessions, etc.
The Problem
A Pinggy tunnel has two legs.
- One from the tunnel creator (client) to the Pinggy servers:
client <-> pinggy - The other from the Pinggy servers to the tunnel visitors (visitor):
pinggy <-> visitor
A visitor’s request to access a service through a Pinggy tunnel has to travel the entire path: visitor -> pinggy -> client.
This is followed by the response travelling the path client -> pinggy -> visitor.
Therefore, the entire journey is: visitor -> pinggy -> client -> pinggy -> visitor.
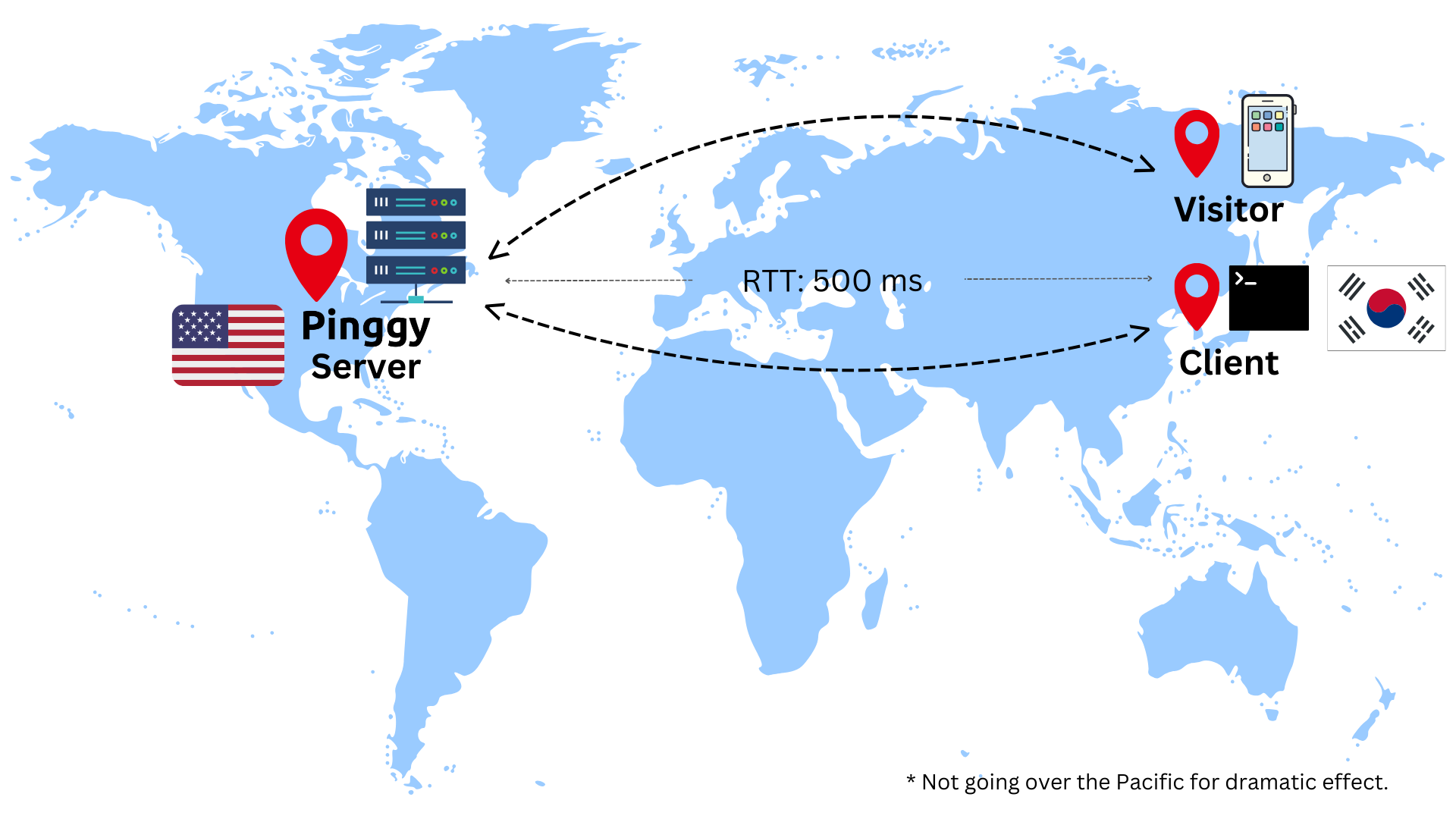
One can already imagine the latency if both the client and the visitor are in South Korea while the Pinggy server is in USA. The round trip time (RTT) can be as high as 500 ms from the visitor to the client.
Here is the shape of the problem. Both the visitor and the client sit in Seoul, but the only Pinggy server is in Ohio:
Both ends in Seoul. The only Pinggy server is in Ohio.
visitor (Seoul) client (Seoul)
\ /
\ ~90 ms one way ~90 ms /
\ /
+---------> pinggy (Ohio) <------+
~6,500 miles each way
A request travels Seoul -> Ohio -> Seoul. The response then
travels Seoul -> Ohio -> Seoul again. Four Pacific crossings
for one round trip, and none of it makes the two machines in
Seoul any closer to each other.
For reference, rough round-trip times between the regions we care about:
US-east <-> EU-west ~80 ms
US-east <-> Asia-Pacific ~150-180 ms
EU-west <-> Asia-Pacific ~230-260 ms
Refactor into core and edges
A Pinggy tunnel works in two phases: (a) Tunnel setup and (b) Tunnel live
(a) Tunnel setup: The user’s ssh client requests a tunnel with an access token and other configurations such as key-authentication, IP whitelists, header manipulations, etc. The Pinggy server has to (i) authenticate the request, (ii) check if an existing tunnel with the same token (same domain) is active or not, (iii) forcefully close any existing tunnel if required, and perform several other business logic before the tunnel can be started. For all these steps, database access (both reads and writes) is required.
(b) Tunnel live: Once the tunnel setup is complete, an active tunnel handles visitor traffic efficiently without touching the database that often.
Therefore, we have split the Pinggy server into core and edge. The core handles the business logic and then offloads the visitor traffic handling responsibility to the edges.
Multiple instances of the edges are then deployed in multiple regions, all connected to a single core and hence a single database. By a single core and database, we mean that the core and the database are located in a single region only.
As a result, the latency for creating a tunnel stays more or less the same, since when a client initiates a tunnel creation process, the requests flow through as follows: client -> edge -> core, instead of client -> core like before. Here the edge is located very close to the user initiating the tunnel, and we can assume that they are practically co-located.
Once the tunnel is live, the visitor traffic flows in a much more efficient path: visitor -> edge -> client -> edge -> visitor.
The two phases use completely different paths:
Tunnel setup (once per tunnel, touches the database):
client --> edge --> core --> database
ssh req API call read + write
Tunnel live (every visitor request, database not in the path):
visitor <--> edge <--> client
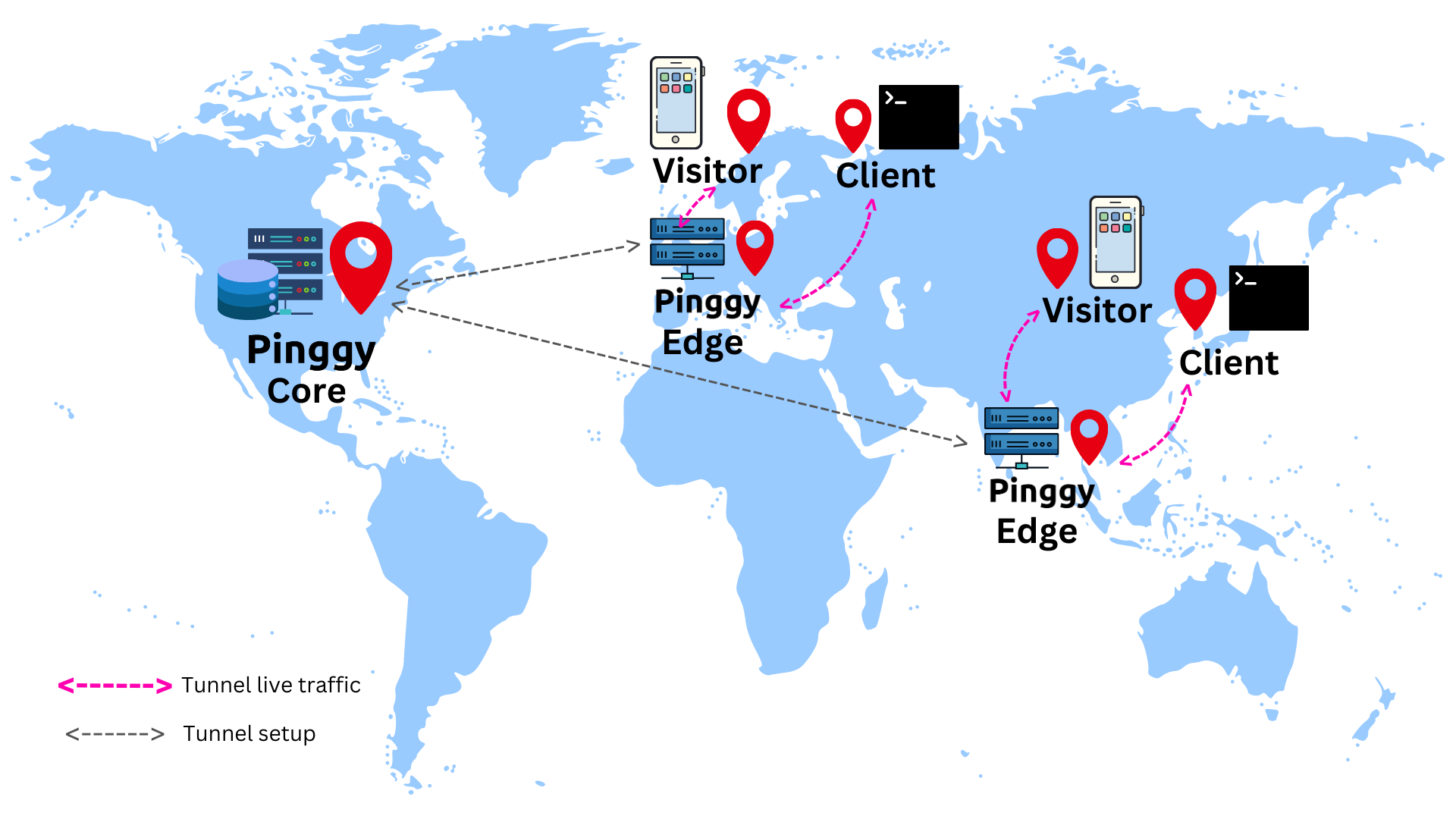
From the above image, it becomes clear that the edge handles all the visitor traffic. As a result, the visitor has a much better experience. The high latency from an edge to the core does not impact the visitor traffic. An edge consults the core first when a tunnel is being created, and then less frequently and asynchronously, without affecting the visitor traffic.
One might ask the question, what if the visitor and the client are in two far away regions. Even if we think about a direct link from the visitor to the client, then also the latency will be high as they are located far away geographically. However, we cannot make the communication link faster magically. What we try to do is place the Pinggy edge as close to the client as possible. Therefore, the edge <-> client link has very low latency and the overall latency of a visitor is very similar to the visitor <-> client latency.
Dynamic DNS updates
The most challenging part of this entire process of multi-region scaling is handling the DNS. To understand the problem one must understand what Pinggy offers in terms of domain names first.
Pinggy offers (i) persistent subdomains (e.g. androidblog.a.pinggy.io) as well as (ii) custom domains (e.g. mydomain.com). A custom domain simply points to a persistent subdomain through a CNAME record.
When a tunnel is created, the persistent subdomain has to point to the server where the tunnel is running. Therefore, ultimately the subdomain must be resolved to A or AAAA records pointing to the correct Pinggy server.
With a single Pinggy server, it was very simple. Every subdomain pointed to the single server (e.g. 1.2.3.4). Therefore, a resolution would look like:
mydomain.com --CNAME--> androidblog.a.pinggy.io --CNAME--> *.a.pinggy.io
*.a.pinggy.io --A--> 1.2.3.4
But with multiple regions we have multiple edges with separate IPs. For example:
USA: us.a.pinggy.io --A--> 1.2.3.4
Europe: eu.a.pinggy.io --A--> 5.6.7.8
Asia: ap.a.pinggy.io --A--> 9.0.1.2
Depending on where the user is located, i.e. in which edge it is creating the tunnel, the tunnel’s domain name records need to change.
If a user connects to the USA edge, then the domain should point to that edge:
mydomain.com --CNAME--> androidblog.a.pinggy.io --CNAME--> us.a.pinggy.io
But if a user connects to the Europe edge:
mydomain.com --CNAME--> androidblog.a.pinggy.io --CNAME--> eu.a.pinggy.io
We can not limit the user to a single location. A user’s client should ideally connect to the nearest edge and initiate a tunnel through that. Some users use Pinggy tunnels on VMs which are often located in different regions. Therefore, a user account cannot be tied to a single region. The DNS has to be handled by us.
Why Route 53 does not work here?
Our first intuition was to use some hosted DNS provider that also provides APIs to update records dynamically.
AWS Route 53 is one such highly available and scalable Domain Name System (DNS) web service. But Route 53 does not fit our requirements.
The specific reason is that the edge locations of Route 53 can take up to 60 seconds to be updated after a record set is changed.
“There are over 100 edge locations in Route 53 with DNS name servers that answer DNS queries from clients. When you update a record set in your hosted zone, the change propagates to all Route 53 edge locations within 60 seconds.” -
AWS Knowledge Center
In our use case, the moment a client tries to create a tunnel, first the DNS records have to be updated, then the tunnel starts, and then the URL is given to the user. Since Route 53 edge locations take up to a minute to start, when a user tries to access the tunnel URL immediately after the tunnel is created, the DNS either (i) resolves to an incorrect record, or the (ii) record is simply not found. The latter scenario is even more problematic.
(i) Expired record: If the tunnel with the same subdomain / custom domain is created in USA first, then disconnected, then again connected through Europe, then the Route 53 records will point to the USA edge instead of the Europe edge for up to a minute. If that incorrect record is resolved by some visitor in the meantime, then not only the tunnel will stop working but also will continue to be dysfunctional till the TTL of the record expires. After the TTL expires and the DNS is queried again, the correct name resolution will take place. A low TTL such as 10 seconds makes sense, but the Route 53 records will in any case take up to one minute.
(ii) No record: Suppose no records exist against the tunnel subdomain / custom domain. Then, after the tunnel is created, if a visitor visits the tunnel URL immediately, then it might happen that the domain fails to resolve since Route 53 records have not been propagated. We faced this issue in our tests very frequently. In this case, low TTL also does not work, and the SOA record needs to have a very low TTL also.
You can read more about these issues
this blog post.
Hosting our own DNS server
Fast updation of DNS records is an essential requirement for reliable Pinggy tunnels. Therefore, we host our own instances of
PowerDNS. This choice has some obvious disadvantages like managing an extra piece of infrastructure, not having DNS servers present in as many regions as in the case of Route 53, etc.
PowerDNS authoritative server allows us to manage our DNS zone. We are able to update records immediately and more importantly synchronously before the tunnel creation process is complete. We also set low TTLs as and when required. As a result, when the tunnel creation process is complete, the authoritative server already has all the records in place.
Today we run three PowerDNS instances, each backed by its own PostgreSQL database. The primary database lives in the USA next to the core and is the only one that takes writes. The databases behind the other two instances are read-only replicas, kept in sync through Postgres streaming replication (WAL streaming). When the core creates or updates a record during tunnel setup, it writes to the primary in the USA, and the two replicas catch up from the WAL stream. A visitor’s DNS query is then answered by whichever instance is closest to them.
The topology looks like this:
record writes (create / update)
core (US) ---------------------------+
v
+--------------------+
| PowerDNS primary |
| Postgres (US) | <- only writer
+---------+----------+
|
WAL stream (compressed), read-only
+--------------------+--------------------+
v v
+--------------------+ +--------------------+
| PowerDNS replica | | PowerDNS replica |
| Postgres (EU) | | Postgres (AP) |
+--------------------+ +--------------------+
^ ^
| DNS query | DNS query
visitor (EU) visitor (AP)
We picked the Postgres backend over PowerDNS’s zonefile mode on purpose. Records change constantly, a pair coming and going with every tunnel, and a relational store with real replication is far easier to reason about than shipping zone files around. PowerDNS reads straight from its local database, so a query served in Singapore never has to cross an ocean to get answered.
The lag race
There is a subtle race hiding in that diagram. Writes go to the US primary, but reads are served from the nearest replica. Picture a client in Singapore: it sets up a tunnel through the Asia edge, the core writes the record to the primary in the US, and a moment later a visitor (also in Asia) looks the domain up against the Asia replica. If the WAL has not arrived yet, that first lookup misses.
So the real constraint is not just “write the record before returning the URL.” It is “get the record onto the replica the next visitor will hit, before they hit it.” We attack this from two sides:
- WAL compression on the primary. It cuts the volume shipped to the replicas, which keeps lag low without saturating the cross-region link. Fewer bytes on the wire means the Asia replica sees the change sooner.
- Batching record updates per zone in the API. A single client action often touches several records in the same zone, so we group those writes into one transaction instead of firing one request per record. Fewer, larger transactions mean less WAL churn and fewer round trips to the database.
And because a miss can still happen on a cold cache, we keep TTLs low, including the SOA negative-caching TTL, so a resolver that gets an early miss retries in seconds rather than caching the failure for minutes. Low TTLs cost us extra queries, but PowerDNS serves those cheaply and the reliability is worth it.
Splitting free and pro tunnels into separate zones
We also keep separate DNS zones for free and pro tunnels. This one is not about latency, it is about reputation.
free tunnels --> free zone (high churn, the occasional abuser)
pro tunnels --> pro zone (kept clean, guarded reputation)
Free tunnels see a lot of throwaway traffic, and a small fraction of it gets used for phishing pages, malware drops, and other things that land on blocklists. When all of that shares one parent domain with paying customers, a single bad actor can get the whole domain flagged by a safe-browsing list or an email reputation service, and suddenly a legitimate pro tunnel is throwing browser warnings through no fault of its own. Splitting the zones contains the blast radius: abuse on the free zone stays on the free zone, and we can apply different policies, rate limits, and takedown response per zone.
Over the past couple of years this setup has held up well. Updates are fast, the TTLs stay low, and PowerDNS itself is light on memory and CPU. We barely think about the DNS layer day to day, which is exactly what you want from it.
However, one problem we have not fully solved is latency-aware routing for the client side. For that we still lean on Route 53 separately.
Latency aware routing
Ideally, a client trying to initiate a Pinggy tunnel should connect to its nearest edge. The client here is usually the ssh client. Unlike HTTP requests, we cannot redirect the ssh client’s TCP connection to some place else through application layer logic. Instead, we need to handle this with DNS only. Therefore, a.pinggy.io should resolve to the nearest among us.a.pinggy.io, eu.a.pinggy.io, and ap.a.pinggy.io.
Route 53’s latency-based routing solves this exact problem. Since our infrastructures are hosted on different AWS regions, we create different latency records for them. When a DNS query arrives at Route 53, it computes the nearest region and answers the query with the corresponding latency record.
For a client connecting from New York, the DNS resolution is:
a.pinggy.io --CNAME--> us.a.pinggy.io
The same for a client from Japan is:
a.pinggy.io --CNAME--> ap.a.pinggy.io
The anycast question
Route 53 latency records work, but they keep us dependent on a hosted DNS provider we would rather lean on less. The cleaner answer is anycast: announce the same IP from every region and let BGP route each client to the closest edge, with no latency lookup in the path.
Today (unicast IPs + DNS latency routing):
client --> a.pinggy.io --(Route 53 picks region)--> nearest edge IP
one name, three different A records
With anycast (one IP, announced from every region):
client --> 203.0.113.1 --(BGP picks the nearest)--> nearest edge
same IP everywhere, no per-region DNS record
We have been chipping away at this and it is still hard. Anycast needs our own address space and BGP sessions with transit providers in each region. The routing is only as good as the upstream peering, and the path with the fewest AS hops is not always the lowest latency, so “nearest” by BGP can still be the wrong edge. Worst of all, an SSH tunnel is a long-lived TCP connection, and anycast makes no promise that every packet in a flow lands on the same node. A routing change mid-session can quietly move our packets to a different edge that has never heard of the connection, and the tunnel drops. Stateless request/response services tolerate this fine; a stateful TCP tunnel does not. So for now Route 53 latency routing stays, and anycast is still on the list.
End-to-end flow
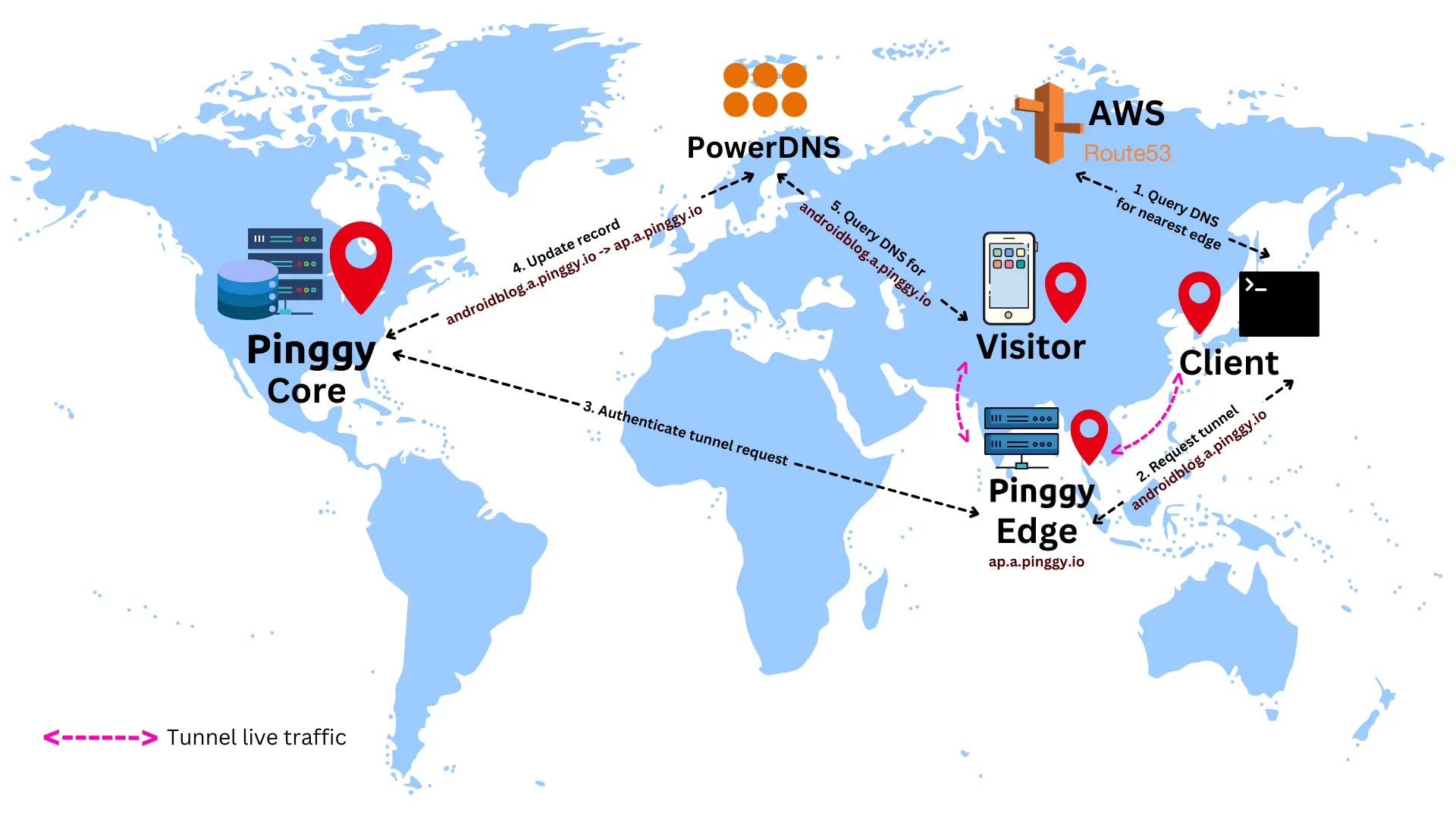
The following end-to-end flow will help one to understand how the Pinggy edge, core, PowerDNS and Route 53 are working together to create the tunnels in this multi-region setup.
- A Pinggy client, which is some ssh client tries to connect to the nearest edge. This is done by resolving the domain name
a.pinggy.io. - This DNS query is handled by AWS Route 53, and resolves to the nearest edge server among USA:
us.a.pinggy.io, Europe: eu.a.pinggy.io, and Asia: ap.a.pinggy.io. - client requests the edge (say
ap.a.pinggy.io) for a tunnel with a subdomain androidblog.a.pinggy.io. - The edge performs some API requests to the core to authenticate the client, validate the subdomain, and to ensure that no tunnels with the same subdomain are active.
- Once the tunnel is authenticated and ready to be activated, a DNS record is created in the PowerDNS servers:
androidblog.a.pinggy.io -> ap.a.pinggy.io. - The tunnel becomes live.
- A visitor trying to access
androidblog.a.pinggy.io resolves the domain name from our PowerDNS servers. PowerDNS responds with ap.a.pinggy.io. - The visitor to client tunnel thus works as follows:
visitor <-> edge (Asia) <-> client.
As a sequence, with the client and the visitor both in Asia:
client edge(AP) core(US) PowerDNS visitor(AP)
| | | | |
| resolve a.pinggy.io via Route 53 -> ap.a.pinggy.io |
|--ssh req -->| | | |
| |--auth/val-->| | |
| | |--write rec->| |
| | | (US primary, WAL -> AP) |
| |<--tunnel ok-| | |
|<--your URL--| | | |
| | | |<--resolve----|
| | | |--ap.a...---->|
| |<==== visitor <-> edge(AP) <-> client ====|
A few things that took time to get right
None of this worked on the first try. The pieces that cost us the most:
- Negative caching is sticky. When a visitor hits a tunnel a beat too early and gets a miss, a recursive resolver can cache that NXDOMAIN for the SOA negative-caching TTL and keep returning it even after the record exists. Getting the SOA minimum TTL low mattered as much as getting the record TTLs low.
- Some resolvers ignore low TTLs. A handful of public resolvers clamp TTLs to a floor of their own (often 30 to 60 seconds), so our 10-second TTL becomes their 30. There is no fix for this from our side. We just had to accept that a small fraction of visitors see slightly stale routing, and design the reconnect flow so it is not catastrophic when they do.
- Two DNS systems, two mental models. Route 53 handles client-side latency routing and PowerDNS handles tunnel records. They fail differently, propagate differently, and are debugged with different tools. Keeping the boundary sharp (Route 53 decides which edge you connect to, PowerDNS decides where a tunnel lives) saved us a lot of confused on-call moments.
- Replication lag is invisible until it is not. Lag sits at a few milliseconds for months and then a cross-region link hiccups and it spikes. We alert on replica lag directly rather than waiting for the symptom, because by the time visitor misses show up, users are already seeing broken tunnels.
What is next
We are still early in scaling Pinggy, and the priority order has not changed: reliability first, performance second. A few things are on the bench:
- Anycast, as above, to drop the Route 53 dependency for client routing and shave the DNS round trip out of tunnel setup.
- Failover for live tunnels. Failover is easy for stateless web apps; you reroute HTTP requests and move on. It is hard for us, because an edge going down means every SSH tunnel pinned to it drops. Handing a live SSH tunnel off to another edge without the client noticing is an open problem, and we are not going to pretend we have solved it. For now we focus on making the edges themselves resilient and the reconnect fast.
- More regions, which mostly means more replicas and more careful attention to the lag race above.
If you run tunnels through Pinggy from far-flung places and see latency or reconnect behavior that surprises you, we would genuinely like to hear about it. The South Korea report that kicked all of this off was one email.