HackerRank Open-Sourced Its ATS. The Score Depends on the Roll of the Dice

HackerRank open-sourced the AI agent behind its resume screening, and within days someone had run the exact same PDF through it 100 times. The scores came back anywhere from 66 to 99, spread across the whole range rather than clustered near one value, on one resume, with nothing changed between runs.
That’s the kind of bug report that makes the rounds fast, and it did, HN thread and all. But the reproducibility problem is only half the story. A second, separate issue filed against the same repo shows you can quietly lift your score by padding a PDF with text nobody sees.
Summary
- HackerRank’s parent company, Interview Street, open-sourced hiring-agent in late June 2026, a Python CLI that scores resumes using an LLM plus GitHub signal.
- Running the identical resume PDF through it 100 times produced scores ranging from 66 to 99. At a hiring cutoff of 85, that same resume would fail roughly two-thirds of the time.
- The pipeline calls an LLM six separate times per resume. Checklist categories like technical skills stay stable; subjective calls like “does this project show production judgment” swing wildly.
- A filed security issue shows hidden, invisibly-colored text in a PDF can add fabricated Google/Meta internships and inflate a toy-project resume’s score from an expected negative into the 90s.
- 65% of the score comes from open-source activity and personal projects, which critics say rewards people with time for public side projects over engineers with decades of closed-source production work.
What’s Actually in the Repo
interviewstreet/hiring-agent is a Python 3.11 command-line tool, MIT-licensed, that had picked up thousands of stars within days of release. There’s no web server, no dashboard, no API. You run it against a PDF and it prints a score:
git clone https://github.com/interviewstreet/hiring-agent
cd hiring-agent
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
cp .env.example .env # set LLM_PROVIDER to ollama or gemini
python score.py /path/to/resume.pdf
You point it at either a local
Ollama model (gemma3:4b by default) or Google Gemini’s API. Under the hood it runs five stages:
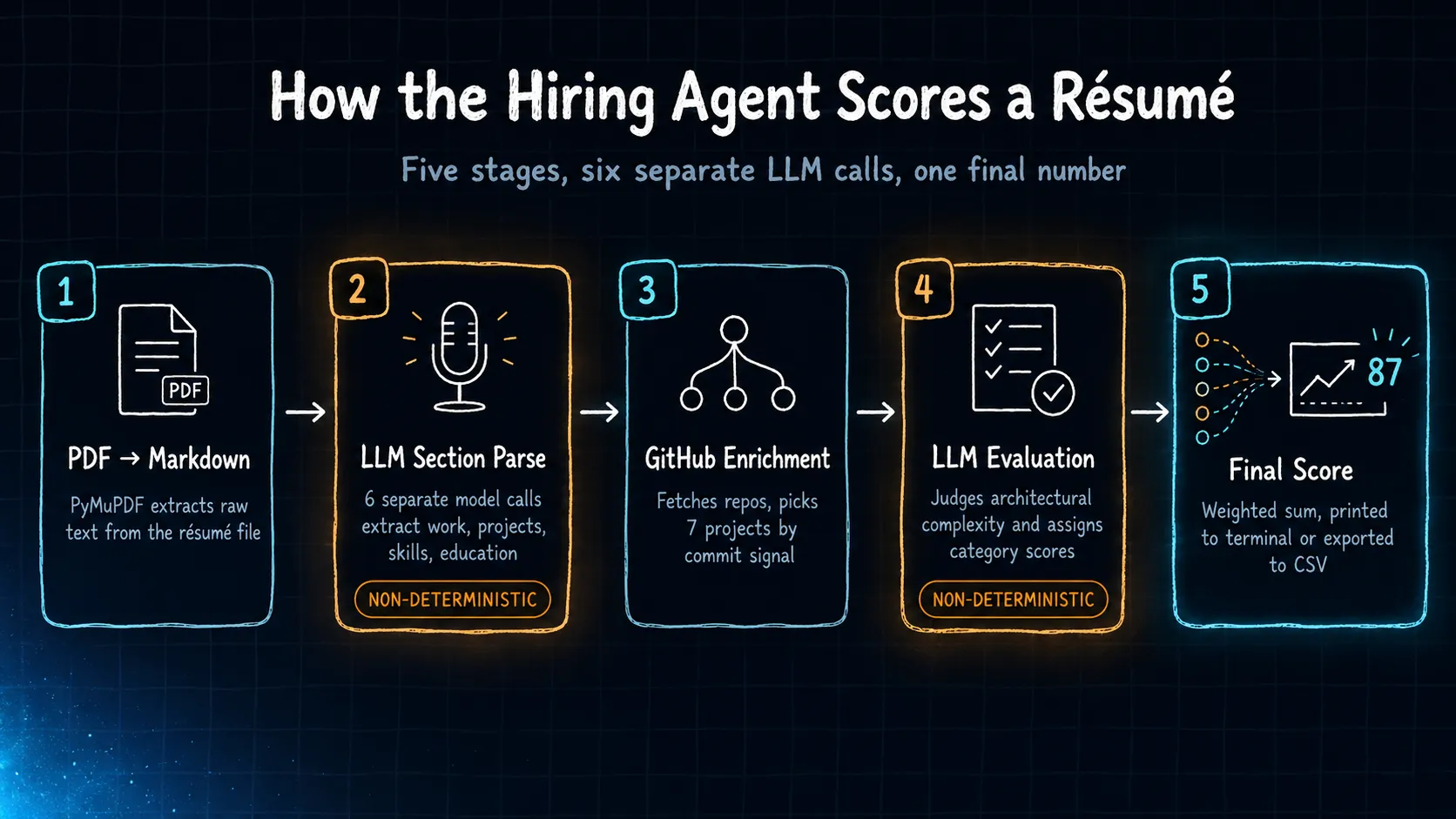
PyMuPDF converts the PDF to Markdown, then an LLM is called six separate times to pull structured data out of it, one call each for basics, work history, education, skills, projects, and awards. A GitHub enrichment step pulls the candidate’s profile and repos and picks out seven projects by commit signal. Then a second LLM pass evaluates everything against four categories, open_source, self_projects, production, and technical_skills, adds bonuses and deductions, and prints a final number. Optionally it appends to a CSV.
It’s a reasonable design for a “look, here’s exactly how we grade you” transparency play. The problem is what happens when you actually run it more than once.
Same PDF, Different Grade Every Time
That 100-run test, documented by Dan Kinsky on Dan Unparsed, is the cleanest demonstration of the issue: one resume file, unchanged, fed through the CLI over and over. First run: 90. Second: 74. Third: 88. Fourth: 83. By run 100, the full spread was 66 to 99, a 33-point band on a tool whose entire pitch is a single objective number.
Do the arithmetic on that. If a company sets its ATS cutoff at 85 (a completely normal thing to do with any scoring tool), the same candidate with the same resume clears the bar roughly 35% of the time and gets auto-rejected the other 65%. Nothing about the candidate changed between those runs. The dice did.
This isn’t unique to gemma3:4b or to local inference, either. A separate scoring run logged in the repo’s issue tracker shows six consecutive scores of 27, 34, 32, 34, 34, 30, at a lowered temperature setting meant to reduce randomness. Lower temperature narrows the spread. It doesn’t remove it.
Why Turning the Temperature Down Doesn’t Save You
The default temperature in hiring-agent is 0.1, low enough that you’d expect near-identical outputs run to run. It isn’t, and the reason is structural rather than a config bug.
Look at which categories are stable and which aren’t. technical_skills behaves like a checklist: the candidate either lists React and Postgres or they don’t, so that score barely moves between runs. self_projects and open_source require the model to make a judgment call, does this side project “demonstrate production-grade architecture” or is it “a tutorial clone with no real complexity”. That’s not a lookup, it’s an opinion, and LLMs don’t hold opinions steady across sampling runs even at low temperature, especially once you’re chaining six separate calls where small differences in an earlier extraction step cascade into the evaluation step.
We’ve written before about why this kind of instability is normal for LLM-based evaluation and not something you patch away with a lower temperature setting: why LLM benchmarks need a reset makes the same point about static benchmarks. hiring-agent is that argument playing out with someone’s actual job application on the line instead of a leaderboard number.
It Gets Worse: You Can Just Tell It What Score You Want
Reproducibility is the headline bug. There’s a second issue filed against the repo that’s arguably more serious: issue #273, “Hidden PDF text poisons resume extraction and inflates hiring scores.”
The attack is simple and doesn’t need any special tooling beyond a PDF editor. PyMuPDF extracts every character in a PDF regardless of whether a human can see it, including text colored to match the page background. Nothing downstream checks whether extracted text was actually visible. So a resume can carry an invisible block claiming a Google internship, a Meta internship, and Google Summer of Code participation, and the LLM sections parser treats it exactly like the visible bullet points.
The reporter’s proof of concept used a resume with nothing but a todo-app and a calculator project, the kind of thing you’d expect to score close to zero on production experience. With the hidden text added, production went from an expected ~0 to 25, open_source from ~5 to 28, and the effective total swung from negative territory to 91. As the issue puts it: score policy limits exist in the prompts, not enforced anywhere in code. If the model is told to weight fabricated credentials, it weights them.
This is the same class of problem as prompt injection against any LLM-backed pipeline that ingests untrusted documents, except here the untrusted document is a job applicant’s resume and the blast radius is who gets an interview.
The Weighting Argument Nobody’s Happy With
Set the bugs aside and there’s a design choice in the rubric itself that’s drawn plenty of criticism: open_source and self_projects together make up 65% of the score, leaving production experience and technical_skills to split the remaining 35%.
| Category | Weight | Run-to-run stability |
|---|---|---|
| Open source contributions | Part of 65% | Volatile, subjective judgment call |
| Self / personal projects | Part of 65% | Volatile, subjective judgment call |
| Production experience | Part of 35% | More stable, but still LLM-judged |
| Technical skills | Part of 35% | Stable, closer to a checklist |
The practical effect: an engineer with fifteen years of closed-source, unglamorous production work, banking systems, internal tooling, whatever never touches a public GitHub repo, is scored mostly on a category that structurally can’t reflect their actual experience. Meanwhile a candidate with a handful of polished weekend projects and an active GitHub profile clears most of the rubric before “production” is even weighed. That tradeoff might be defensible for a junior-hire pipeline built around portfolio signal. It’s a much harder sell as a general-purpose ATS filter, which is closer to how it’s being marketed.
The Upside of Open-Sourcing a Flawed Tool
Credit where it’s due: none of this would be visible if HackerRank had kept the scoring logic behind an API. Because the code is public, anyone can read the prompts, reproduce the bug, and file a PoC instead of speculating about what a black-box ATS might be doing to their application. Within days, forks like hackerrank-resume-ats and hosted tools built on the same rubric popped up, letting candidates check their own resume against the exact scoring logic before they submit it anywhere.
That’s the actual silver lining here, and it’s a fairly HN-flavored one: an AI system making consequential decisions about people is defensible in proportion to how inspectable it is. A closed ATS with the same bugs would just be a company quietly rejecting qualified candidates and calling it “the algorithm.” An open one gets audited by whoever’s curious enough to clone it and loop score.py a hundred times.
Conclusion
Two things are true at once here. First, if you’re building or buying an LLM-based screening tool, treat the score like a noisy estimate, not a ground truth, and never wire a hard numeric cutoff directly to it without accounting for the variance, the same resume clearing or failing a cutoff by chance is not a hypothetical, it’s measured behavior in this exact repo. Second, if you’re on the other side of that pipeline, it’s worth remembering that a document scored by an LLM is a document an LLM can be manipulated by. Prompt injection through invisible PDF text sounds like a novelty exploit until you realize it’s currently sitting in a repo with thousands of stars, scoring real applications.
HackerRank open-sourcing this was probably meant as a transparency win. It ended up being a pretty good public demonstration of why “AI decided” is not, on its own, an answer anyone should accept.