Why LLM Benchmarks Need a Reset

Leaderboard culture makes LLM comparison look cleaner than it really is. A model gets a number, a ranking, and a reputation, and teams start treating that score as a shortcut for real capability. The problem is that large language models are not static software components. They are prompt-sensitive, update frequently, behave differently across languages and contexts, and can look impressive on narrow tests without being equally reliable in real workflows.
That is the core argument of this blog’s main source: McIntosh, T.R., Susnjak, T., Arachchilage, N., Liu, T., Xu, D., Watters, P. and Halgamuge, M.N., 2025. Inadequacies of large language model benchmarks in the era of generative artificial intelligence. IEEE Transactions on Artificial Intelligence. The paper studies 23 benchmark efforts and argues that static, exam-style benchmarking often fails to capture the complexity, risk profile, and real-world applicability of modern LLMs.
Summary
LLM benchmarks are still useful, but they work best as a first-pass screen, not as the full story of model quality.
Across 23 benchmark studies, the biggest recurring issues were response variability, the difficulty of separating genuine reasoning from benchmark optimization, inconsistent implementation, prompt sensitivity, evaluator diversity, and the mismatch between fixed answer keys and real human values.
Another core problem is standards fragmentation. Advanced AI still lacks universally accepted benchmarking norms, which helps explain why so many researcher-defined benchmarks are hard to compare cleanly.
The better replacement is a layered evaluation stack: benchmark screening, task-specific behavioral profiling, and regular audits after deployment. Read the paper: Inadequacies of Large Language Model Benchmarks in the Era of Generative Artificial Intelligence
A better way to judge benchmark quality
A more useful lens is functionality and integrity. Functionality asks whether a benchmark measures capabilities that matter in practice. Integrity asks whether the benchmark resists gaming, contamination, and superficial score inflation. A benchmark can look comprehensive on paper and still fail one or both of those tests.
One useful way to organize that problem is through a People, Process, Technology framework. LLM evaluation is not only a technical measurement problem. It is also a workflow problem and a human judgment problem. If you only look at raw task accuracy, you can miss brittle prompting, culturally narrow rubrics, or evaluation pipelines that are too fragile to reproduce consistently.
What today’s benchmark landscape still misses
Across the 23 benchmark efforts reviewed by McIntosh et al., the pattern is clear. The ecosystem includes broad evaluation suites such as MMLU, BIG-Bench, AGIEval, HELM, and PromptBench, alongside domain-focused or agent-style benchmarks such as HumanEval, LegalBench, MultiMedQA, ToolBench, AgentBench, APIBank, and HaluEval.
Many benchmark sets are heavily English-centric, some extend into Simplified Chinese, and many still assume a single correct answer even in culturally sensitive contexts. Real-world model use is often multi-turn and ongoing, while many benchmarks still grade only a first response or a fixed interaction pattern. At the time of this review, only a small minority of the surveyed benchmark studies were peer-reviewed, which also says something about how fast this space has moved relative to its evaluation standards.
There is also a broader governance problem. Unlike regulated industries with mature benchmarking norms, advanced AI still lacks universally accepted standards. That has encouraged a proliferation of researcher-defined benchmarks and even question-and-answer sets that are treated as benchmarks without enough reflection on their limitations.
Where the shortcomings clustered
| Domain | Recurring inadequacies across benchmark studies | Prevalence | Why it matters |
|---|---|---|---|
| Technology | Response variability, reasoning vs technical optimization, and the tension between helpfulness and harmlessness. | 22/23, 22/23, 19/23 | A strong score can still hide brittle behavior, prompt sensitivity, or benchmark gaming. |
| Process | Inconsistent implementation, slow test iteration time, and prompt engineering challenges. | 18/23, 18/23, 14/23 | If the evaluation workflow is hard to reproduce, fair comparison becomes much harder. |
| People | Diversity in human curators and evaluators, plus cultural, social, political, religious, and ideological norms. | 19/23, 18/23 | A single answer key may not reflect the users, jurisdictions, or cultures a model will actually serve. |
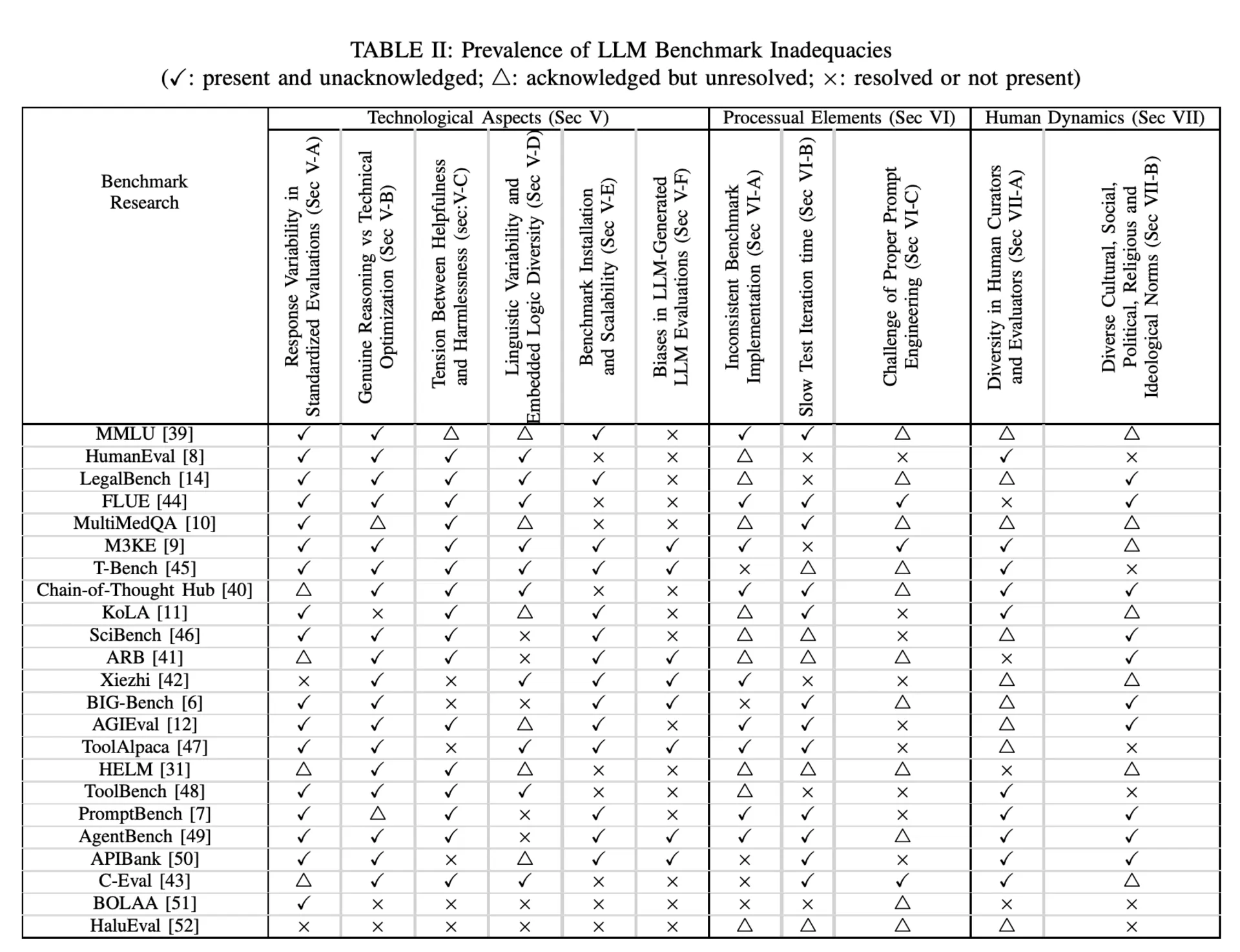
Where current LLM benchmarks break down
Static tests underestimate dynamic behavior
Many benchmark formats are too static for systems that are increasingly used in conversations, agent loops, and tool-driven workflows. Multiple choice questions and single-shot tasks are easy to score, but they are a poor match for the way people actually use modern assistants. Real usage involves follow-up questions, clarifications, retries, changing context, and tradeoffs between speed, safety, and usefulness.
This is why benchmark scores can feel more decisive than they deserve. They reduce a living interaction system into a controlled exam. That is useful for screening, but it is not a faithful simulation of production behavior. If you are comparing models for real work, including self-hosted coding LLMs, you need evaluation scenarios that look more like workflows and less like school tests.
High scores can reward optimization more than understanding
Benchmarks often struggle to separate genuine reasoning from technical optimization. A model can score well because it has seen benchmark-like data, learned a narrow response pattern, or been tuned around familiar evaluation structure. That does not automatically mean the model understands the task in a durable, transferable way.
In practical terms, that means a model can look excellent on a leaderboard and still disappoint when the task shifts slightly, when the prompt format changes, or when the work moves from canned questions to open-ended production tasks. For developers, this is the difference between a model that demos well and a model that keeps working after deployment.
Tiny prompt and format changes can move the score
Prompt engineering is not just an optimization technique. It is also a benchmarking problem. If small wording changes, formatting shifts, or evaluation scaffolding alter the result, then the benchmark may be measuring prompt compatibility as much as model capability.
That is not a theoretical concern. Superficial input variations can shift accuracy by approximately 5%. When a leaderboard is decided by narrow margins, that kind of instability matters. It also explains why two teams can evaluate the same model and walk away with different conclusions.
Benchmark quality is also a dataset quality problem
Benchmark questions and answers can also age badly. As technology and society evolve, benchmark content can become outdated, and prior work has already found mislabeled or unanswerable examples in MMLU. That is an important reminder that benchmark integrity depends not only on the model and the scoring method, but also on whether the underlying dataset is still correct and maintainable.
Letting LLMs grade LLMs can create circularity
Another issue is circularity. When LLMs are used to generate benchmark items or evaluate other LLMs, they can amplify the evaluator model’s own biases and preferred reasoning patterns. That weakens independence and can allow models to score well through pattern familiarity rather than genuine understanding, which is why a more balanced approach still needs human expertise in the loop.
English-first evaluation can overstate generality
Another recurring weakness is linguistic and cultural narrowness. Many benchmarks are still dominated by English, with some coverage in Simplified Chinese, but far less attention to multilingual reasoning and embedded cultural logic. Predominantly English-centric benchmarks can overlook reasoning patterns embedded within languages and wrongly assume a uniform cognitive framework.
This becomes even more serious in domains like law, medicine, education, or public communication. Standardized answers or rubrics can fail to represent the pluralistic nature of human beliefs and values, especially across different jurisdictions, religions, and cultures. That is one reason a universal benchmark standard is much harder than it sounds.
What should replace leaderboard-only evaluation?
Benchmarks are not useless. They are just being asked to do too much. A better framing is to use them as an initial screen, not as the final verdict. One useful comparison is a hiring pipeline: benchmarks help with first-pass filtering, behavioral profiling works like a deeper interview, and regular audits play the role of post-hire review.
That is a practical way to think about model evaluation. Use a benchmark to narrow the field. Then run task-specific behavioral tests that examine adaptability, consistency, safety judgment, and performance across the actual workflows you care about. After deployment, keep auditing, because models change, prompts drift, and user behavior keeps evolving. If you want a deeper model-architecture refresher while thinking about those tradeoffs, our explainer on Mixture of Experts in LLMs is a useful companion.
How to evaluate an LLM beyond leaderboard scores
Start with a benchmark that matches the job. A coding assistant should not be chosen mainly from a general knowledge exam, and a legal or medical workflow should not depend on a generic chatbot leaderboard.
Add workflow-shaped tests. Include multi-turn conversations, tool use, ambiguous instructions, and recovery from partial failures. That gives you a better view of how the model behaves under real operating conditions.
Stress test prompt sensitivity. Re-run a small set of tasks with slightly different phrasing or formatting. If performance changes too much, the system is not robust enough yet.
Use human review where judgment matters. For subjective, high-risk, or culturally sensitive outputs, evaluator training and evaluator diversity matter just as much as raw benchmark design.
Run audits after deployment. This is the step most teams skip. Vendor updates, prompt template changes, and new user behavior can all shift model performance after the original evaluation is done.
Conclusion
The core takeaway is not that benchmarks should disappear. It is that static benchmark scores are too narrow to carry the full burden of model evaluation in the generative AI era. If you treat them as the whole truth, you risk confusing polished exam performance with actual reliability.
A better approach is layered and context-specific. Start with benchmarks, but do not stop there. Add behavioral profiling, human review, multilingual and cultural edge cases, dataset maintenance, and regular audits. That is a much better fit for real applications, whether you are comparing model providers, building agent workflows, or choosing between open-source AI chat platforms and more specialized systems.
This article draws primarily on the work of McIntosh, Susnjak, Arachchilage, Liu, Xu, Watters, and Halgamuge in IEEE Transactions on Artificial Intelligence on the inadequacies of LLM benchmarks.