Google Research introduced TurboQuant on March 24, 2026, and Google launched Gemma 4 on April 2, 2026. Those announcements are not the same thing, but they point in the same direction: better compression, lower memory use, and stronger on-device AI. That matters because the biggest bottleneck for modern LLMs is no longer just model quality. It is whether the model can keep enough context in memory and respond fast enough to feel useful on real hardware.
If you are a developer, this is the difference between a model that looks impressive in a benchmark and one that actually ships in a phone, laptop, browser, or Raspberry Pi workflow. If you are a general user, it is the difference between “AI in the cloud” and “AI that works privately on your own device.”
Important note: Google has publicly described TurboQuant as a general compression method for KV caches and vector search, and it evaluated the approach on Gemma-family and Mistral-family models. Google has not publicly said that Gemma 4 is natively trained with TurboQuant as a built-in architecture feature. The connection is deployment efficiency: TurboQuant reduces long-context memory cost, while Gemma 4 and Google AI Edge make that kind of efficient local inference practical.
Summary
- TurboQuant: Google Research’s compression method for KV caches and high-dimensional vectors, designed to cut the memory cost of long-context inference. Google Research blog
- Why it matters: less KV memory means cheaper, faster inference and makes capable models easier to run on local hardware.
- Gemma 4 connection: Google has not said Gemma 4 is natively built on TurboQuant, but Gemma 4 is the kind of edge-focused model family that benefits from the same push toward efficient on-device AI. Gemma 4 model card
What Is TurboQuant?
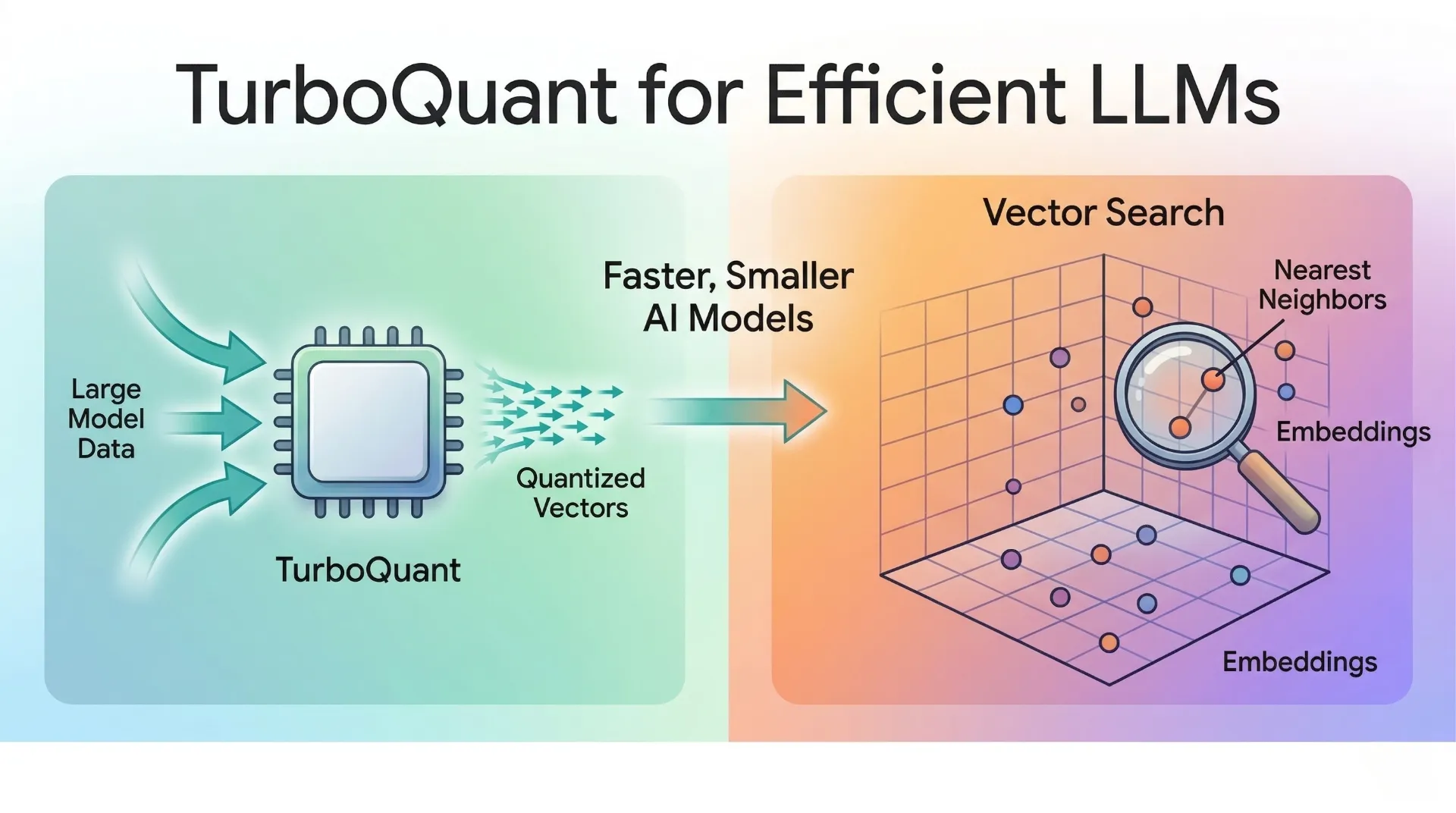
TurboQuant is a compression method from Google Research designed to make high-dimensional vectors much cheaper to store and process. In practice, the most relevant LLM use case is KV cache compression. The KV cache is the model’s short-term working memory during generation. It stores the key and value tensors that let the model avoid recomputing attention for every previously seen token.
That cache grows with every new token in the conversation. As context windows become larger, KV memory becomes one of the main reasons large models feel expensive, slow, or impossible to run locally. TurboQuant exists to reduce that cost without breaking the attention mechanism that gives an LLM its long-context ability.
Google also positions TurboQuant as useful for vector search, not just LLM inference. That is important because the same core problem appears in both systems: large, high-dimensional vectors are powerful, but they are expensive to store, move, and compare.
The Math Behind TurboQuant, in Plain English
The cleanest official overview is the Google Research TurboQuant blog, but the short version is this: TurboQuant is really a two-stage compression pipeline.
First comes PolarQuant. Instead of treating a vector only in standard Cartesian coordinates, PolarQuant groups coordinates and rewrites them in terms of radius and angle. In plain terms, it turns “how far along each axis” into “how strong is this signal” plus “what direction is it pointing.” For a simple 2D pair, that intuition is the familiar conversion from (x, y) into a radius r and an angle theta. Google’s key insight is that this polar representation makes the vector easier to quantize with much less memory overhead than standard approaches.
Then comes QJL, short for Quantized Johnson-Lindenstrauss. After PolarQuant captures most of the signal, QJL compresses the remaining residual error into a very cheap one-bit sketch that still preserves the dot-product structure attention depends on. The Johnson-Lindenstrauss idea is mathematically famous because it lets you project high-dimensional data into a smaller representation while approximately preserving distances. TurboQuant uses that principle as a correction stage, so the model keeps the important geometry of the original vectors instead of accumulating biased attention errors.
That combination is the core trick. PolarQuant does most of the heavy compression. QJL cleans up the leftover error very cheaply. The result is that more of the bit budget goes toward real signal instead of housekeeping overhead.
How TurboQuant Makes an LLM Efficient
The reason TurboQuant matters for LLMs is not that it magically makes the base model weights smaller. Its immediate impact is on runtime memory, especially for long prompts and long conversations. When the KV cache gets compressed well, three good things happen at once.
The first is lower memory pressure. That means the same hardware can hold longer conversations or larger batch sizes before it runs out of room. The second is faster attention. If keys and values are smaller and easier to move through memory, the model spends less time waiting on bandwidth. The third is lower cost. In a server setting that means cheaper inference. In an edge setting it means smaller devices can handle workloads that previously required more RAM or more expensive accelerators.
That is why Google highlighted three numbers in its March 24, 2026 announcement: at least 6x KV memory reduction, 3-bit quantization without retraining, and up to 8x faster attention logit computation in its H100 experiments. Even if your exact gains depend on hardware and runtime, the direction is clear. Better KV compression is one of the most practical ways to make long-context LLMs feel lighter without throwing away model quality.
How Gemma 4 Fits Into This Story
Here the precise answer is a little nuanced, and it is worth getting right.
TurboQuant was announced first, on March 24, 2026, as a general compression method evaluated on open-source Gemma and Mistral models. Gemma 4 arrived on April 2, 2026, as a new open model family designed for strong reasoning, coding, function calling, multimodal understanding, and edge deployment. So when people connect the two, what they usually mean is not “Gemma 4 is secretly a TurboQuant model.” What they mean is that Gemma 4 is exactly the kind of model family that benefits from compression breakthroughs like TurboQuant.
That framing is important for developers. TurboQuant is a runtime and systems innovation. Gemma 4 is a model and product-stack innovation. Together they solve the same user-facing problem: how do you get a capable model to run locally with long enough context, low enough memory use, and fast enough latency to feel genuinely useful?
What Actually Makes Gemma 4 Efficient
Google’s Gemma 4 model card makes the efficiency story more concrete. Gemma 4 comes in four sizes: E2B, E4B, 26B A4B, and 31B. The small E2B and E4B models are explicitly optimized for local execution on phones and laptops. The 26B A4B model uses a Mixture of Experts design, so only about 3.8B parameters are active during inference even though the total model is much larger. That gives you much more model capacity than a plain 4B model at something closer to 4B-style runtime cost.
Google also built Gemma 4 around a hybrid attention design that mixes local sliding-window attention with full global attention. On top of that, the model card calls out unified Keys and Values and Proportional RoPE (p-RoPE) in the global layers to reduce long-context memory cost. That is a different lever from TurboQuant, but it points in the same direction: make long contexts cheaper and more practical.
The small models add another useful idea: Per-Layer Embeddings (PLE). Instead of only scaling performance by stacking more layers or adding more active parameters, Gemma 4 E2B and E4B use large embedding tables that are cheap to look up and relatively efficient for on-device deployment. In plain English, Google is trading some parameter storage for lower active compute, which is often exactly the right move when targeting mobile hardware.
The runtime layer matters too. In Google’s AI Edge blog, the team says LiteRT-LM can run Gemma 4 E2B using under 1.5GB of memory on some devices by combining 2-bit and 4-bit weights with memory-mapped per-layer embeddings. That is the sort of systems work that turns “small open model” into “something that actually ships on a phone or IoT board.”
Gemma 4 on iPhone, Android, and Edge Devices
This is the part that changes the story from research to real product experience.
The Google AI Edge Gallery app now officially supports Gemma 4 and is available on both iPhone and Android. The app exposes a set of on-device features that make local AI feel more useful than a plain chat window: Agent Skills, Thinking Mode, Ask Image, Audio Scribe, Prompt Lab, and Mobile Actions.
For Android developers, Google also announced the AICore Developer Preview on April 2, 2026. Google says the code written for Gemma 4 today is meant to carry forward to Gemini Nano 4-enabled devices later this year. It also says the new on-device model is up to 4x faster than previous versions and uses up to 60% less battery on Android preview paths, which is exactly the type of progress that makes local assistants and agent workflows realistic on phones.
Beyond phones, the same Google AI Edge stack now targets desktop, browser, and IoT environments. Google specifically highlights LiteRT-LM deployment across Android, iOS, Web, desktop, Raspberry Pi 5, and Qualcomm Dragonwing IQ8 class edge hardware. In other words, Gemma 4 is no longer “local AI” in the narrow laptop-only sense. It is becoming a real edge model family.
Why Mobile Actions Matters More Than It Looks
The most important usability point in this whole story is not just that Gemma 4 can answer questions offline. It is that the on-device stack is starting to connect language understanding with actual device actions.
Google’s Mobile Actions guide explains that users can trigger tasks such as turning on the flashlight, showing a location on the map, opening Wi-Fi settings, creating a contact, sending an email, or creating a calendar event using natural language. The interesting technical detail is that this specific Mobile Actions experience is powered by a fine-tuned FunctionGemma 270M model, not by Gemma 4 alone.
That distinction is not a weakness. It is good system design. Gemma 4 handles the broader reasoning, chat, multimodal understanding, and agent workflows, while a smaller, specialized function-calling model handles device actions with tighter control. This is exactly how practical local AI should evolve: let the bigger model reason, and let the smaller tool model execute predictable actions.
It also explains why the current phone experience can feel “good enough” even when it is not trying to match the largest cloud models. A local model does not need to beat a frontier cloud model on every benchmark to be useful. If it can understand intent quickly, preserve privacy, and fire the right on-device tool call for flashlight, maps, reminders, or settings, the user experience improves immediately. Early community reactions in the recent Hacker News discussion around Gemma 4 on iPhone reflect exactly that trade-off: not the same as a giant cloud model, but already practical for private, lightweight daily actions.
How to Try Gemma 4 Today
If you want to test this stack without building a full app first, the simplest path is:
- Install Google AI Edge Gallery on your iPhone or Android device.
- Start with Gemma 4 E2B if you care most about latency, or Gemma 4 E4B if you want stronger reasoning.
- Try Thinking Mode, Ask Image, and Agent Skills to understand where Gemma 4 already feels useful on-device.
- Try Mobile Actions separately to see how specialized local function calling handles device controls like flashlight, maps, Wi-Fi, contacts, and calendar flows.
- If you are building a product, move to AICore on supported Android devices or LiteRT-LM for broader mobile, desktop, and edge deployment.
That progression makes sense because it mirrors Google’s own stack. First test the experience. Then evaluate the latency and memory trade-offs. Then decide whether you want a general reasoning model, a tool-specialized model, or both.
Conclusion
TurboQuant matters because it attacks one of the hardest parts of long-context LLM deployment: the cost of KV memory. Gemma 4 matters because it shows what happens when a modern open model family is built with deployment in mind from day one. Put those together, and you get a much clearer picture of where efficient AI is going.
The big change is not just “smaller models.” It is better systems around models: smarter compression, sparse activation, hybrid attention, quantized runtimes, and specialized tool-calling models working together. That is how you move from demo-grade local AI to useful edge AI.
And that is why Gemma 4 on iPhone, Android, and broader edge hardware is worth paying attention to. It is not just a model release. It is a sign that local, private, agentic AI is getting close to everyday practicality.