 Running powerful AI language models locally has become increasingly accessible in 2026, offering privacy, cost savings, and full control over your data. With groundbreaking releases like Google’s Gemma 4 (now including a 12B model that runs in 16GB of RAM), Kimi K2.5/K2.6, Qwen3.5/3.6, GLM-5.1, NVIDIA Nemotron Cascade 2, OpenAI’s GPT-OSS, DeepSeek V3.2-Exp, Qwen3-Coder-480B for agentic coding, Meta’s Llama 4, and Mistral Large 3, local LLMs now rival cloud-based services in performance while maintaining complete data privacy and eliminating subscription costs.
Running powerful AI language models locally has become increasingly accessible in 2026, offering privacy, cost savings, and full control over your data. With groundbreaking releases like Google’s Gemma 4 (now including a 12B model that runs in 16GB of RAM), Kimi K2.5/K2.6, Qwen3.5/3.6, GLM-5.1, NVIDIA Nemotron Cascade 2, OpenAI’s GPT-OSS, DeepSeek V3.2-Exp, Qwen3-Coder-480B for agentic coding, Meta’s Llama 4, and Mistral Large 3, local LLMs now rival cloud-based services in performance while maintaining complete data privacy and eliminating subscription costs.
Summary
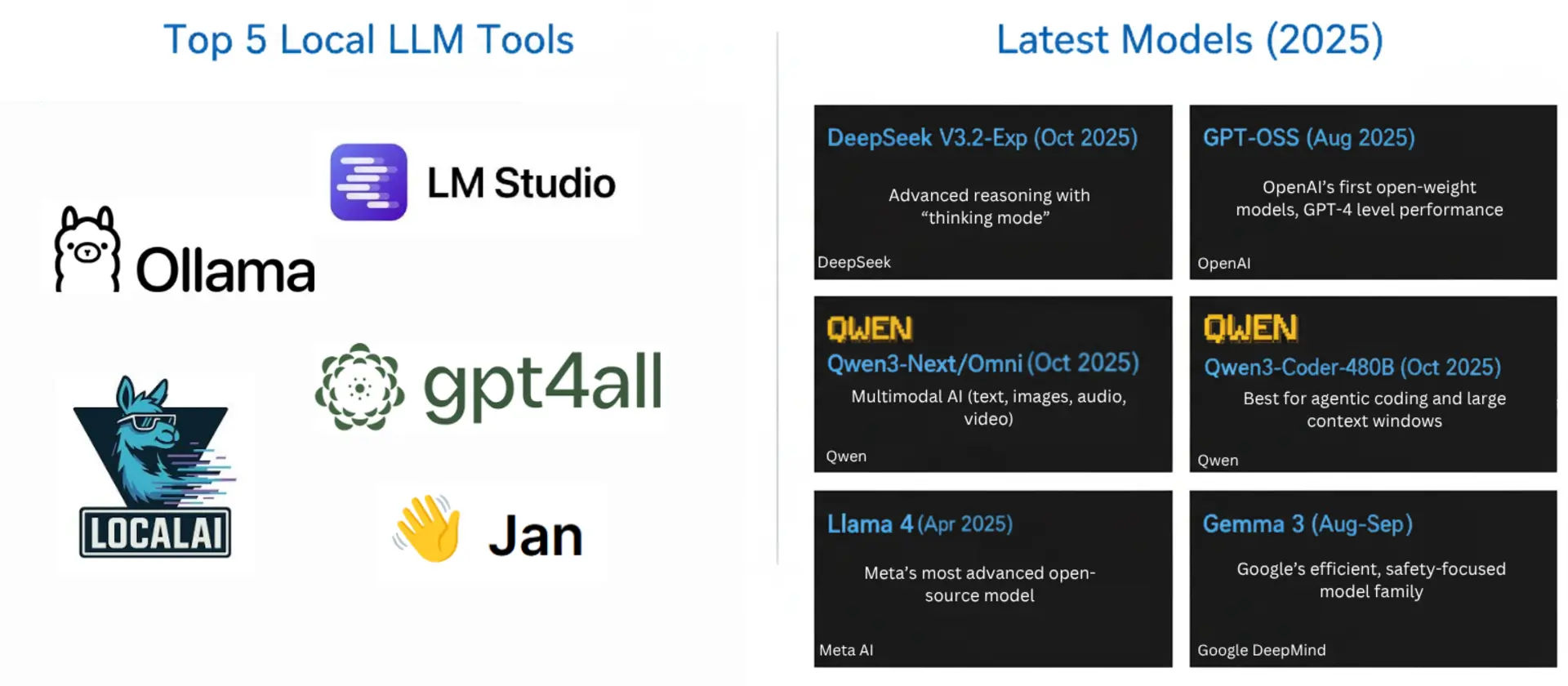
Top 5 Local LLM Tools:
- Ollama - One-line commands, 100+ models | Download
- LM Studio - Best GUI, model discovery | Download
- BlueQubit - Cloud quantum computing via a Python SDK (adjacent, not a local LLM runner) | Bluequbit
- text-generation-webui - Flexible, extensions | GitHub
- GPT4All - Beginner-friendly desktop app | Download
- LocalAI - Developer-focused, OpenAI API compatible | GitHub
Bonus: Jan - Complete ChatGPT alternative, 100% offline | Download
Latest Models (2026):
- Gemma 4 12B (Jun 2026) - Google’s newest mid-sized model, native audio, runs in 16GB RAM | Google
- Gemma 4 (Apr 2026) - Google’s MoE flagship, 26B params, 85 t/s on consumer hardware | Google
- Kimi K2.6 (Apr 2026) - Latest Moonshot AI with Agent Swarm architecture | Moonshot AI
- Qwen3.6-35B-A3B (Apr 2026) - Alibaba’s newest efficient MoE model | Qwen
- GLM-5.1 (Apr 2026) - Zhipu AI’s latest with 744B MoE architecture | Hugging Face
- NVIDIA Nemotron Cascade 2 (Mar 2026) - Optimized for fast local inference | Hugging Face
- Kimi K2.5 (Jan 2026) - 1T parameter MoE with Agent Swarm | Hugging Face
- Qwen3.5 (Mar 2026) - 122B MoE, beats GPT-5-mini on benchmarks | Hugging Face
- Mistral Large 3 (Dec 2025) - Mistral’s most capable model | Ollama
- GPT-OSS (Aug 2025) - OpenAI’s first open-weight models, GPT-4 level performance | OpenAI
- DeepSeek V3.2-Exp (Oct 2025) - Advanced reasoning with “thinking mode” | DeepSeek
Why Run LLMs Locally in 2026?
The landscape of AI has evolved dramatically, but running LLMs locally continues to offer compelling advantages:
- Complete Data Privacy: Your prompts and data never leave your device
- No Subscription Costs: Use AI as much as you want without usage fees
- Offline Operation: Work without internet connectivity
- Customization Control: Fine-tune models for specific use cases
- Reduced Latency: Eliminate network delays for faster responses
Top 5 Local LLM Tools in 2026
1. Ollama
Ollama has emerged as the go-to solution for running LLMs locally, striking an ideal balance between ease of use and powerful features.
Key Features:
- One-line commands to pull and run models
- Support for 200+ optimized models including Gemma 4, Kimi K2.5/K2.6, Qwen3.5/3.6, GLM-5.1, Nemotron Cascade 2, GPT-OSS, DeepSeek V3.2-Exp, and Mistral Large 3
- Native Kimi CLI integration (
ollama launch kimi) for agentic workflows - Cross-platform support (Windows, macOS, Linux)
- OpenAI-compatible API with MLX optimizations for Apple Silicon
- Active community and regular updates (latest: v0.21.x with Hermes Agent support)
Getting Started with Ollama:
Install Ollama:
- Visit ollama.com/download
- Download and install for your operating system

Run a model:
# Pull and run the latest models in one command ollama run qwen3.5 # For the newest Gemma that fits in 16GB RAM: ollama run gemma4:12b # For the fastest local inference: ollama run gemma4:26b # For the latest reasoning models: ollama run deepseek-v3.2-exp:7b # For agentic AI with Kimi K2.6: ollama launch kimi --model kimi-k2.6:cloud
Use the API:
curl http://localhost:11434/api/chat -d '{ "model": "gemma4:26b", "messages": [ {"role": "user", "content": "Explain quantum computing in simple terms"} ] }'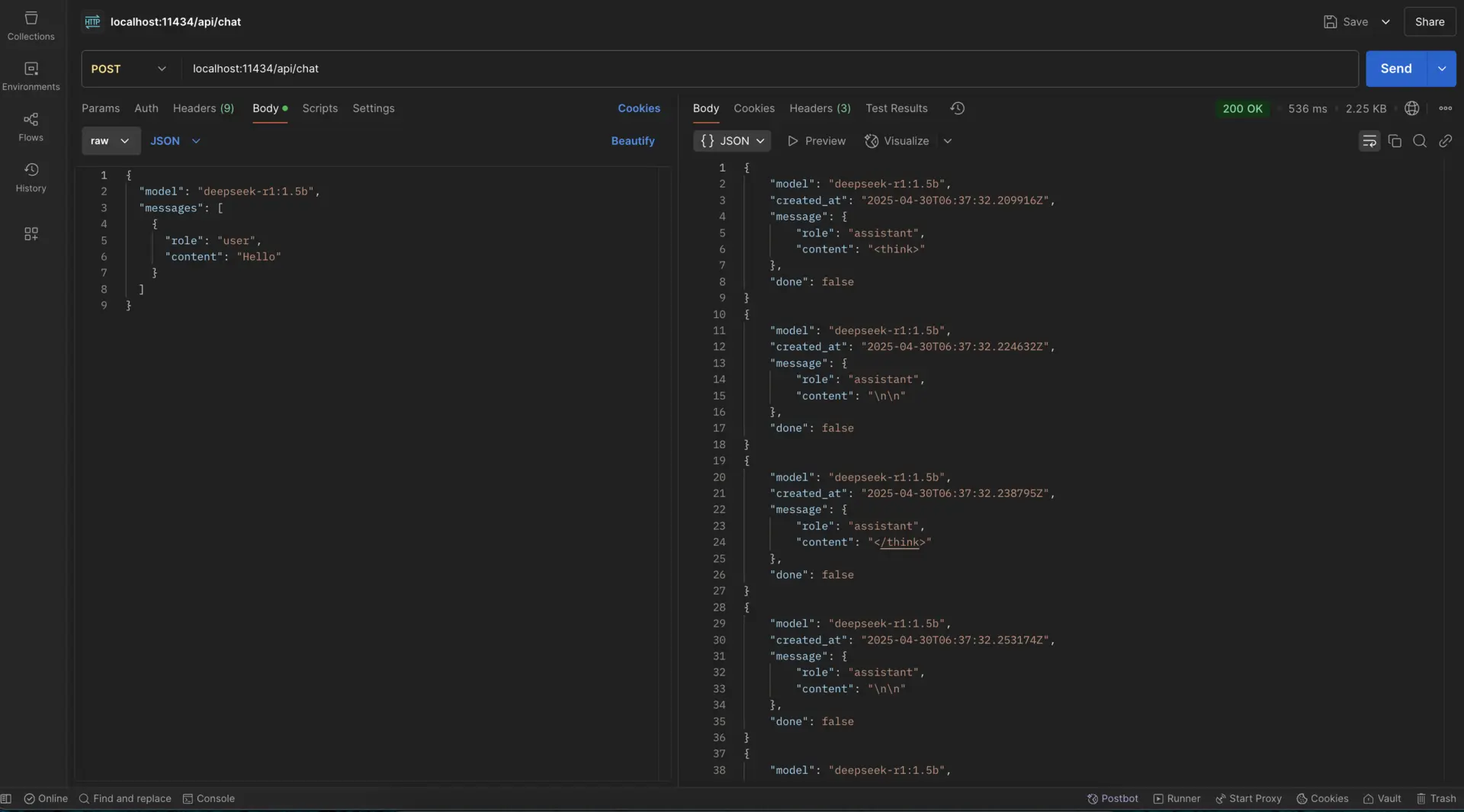
Best For: General users who want a straightforward way to run LLMs locally with minimal setup.
Related: Learn how to run Ollama on Google Colab or share your Ollama API online for remote access.
2. LM Studio
LM Studio provides the most polished graphical user interface for managing and running local LLMs, making it accessible for non-technical users.
Key Features:
- Intuitive GUI for model discovery and management
- Built-in chat interface with conversation history
- Advanced parameter tuning through visual controls
- Model performance comparison tools
- OpenAI-compatible API server
Getting Started with LM Studio:
Install LM Studio:
- Visit lmstudio.ai
- Download the installer for your OS
Download Models:
- Navigate to the “Discover” tab
- Browse and download models based on your hardware capabilities
Chat or Enable API:
- Use the built-in chat interface
- Or enable the API server through the “Developer” tab
Best For: Users who prefer graphical interfaces over command-line tools and want an all-in-one solution.
Related: Check out our detailed LM Studio guide for step-by-step setup instructions and advanced features.
3. BlueQubit
Bluequbit is the outlier in this list: it is a cloud quantum computing platform, not a local LLM runner. It is here because the workflow rhymes. If you already prototype models in Python and Jupyter, BlueQubit gives you the same loop for quantum circuits without buying or booking hardware.
You write circuits against a Python SDK, then execute them on a simulator or on real quantum backends from multiple providers. It speaks the frameworks people already use - Qiskit and Cirq - so existing circuit code mostly carries over. Typical use cases are quantum machine learning, optimization, chemistry, and finance research.
Key Features:
- Python SDK with Jupyter Notebook support for interactive development
- Access to quantum simulators and multiple hardware backends from one API
- Compatible with existing Qiskit and Cirq circuit code
- Targets quantum machine learning, optimization, and scientific computing workflows
- No local quantum hardware or infrastructure to set up
Getting Started with BlueQubit:
Create an account:
- Sign up at bluequbit.io on the free tier
Install the SDK:
pip install bluequbitConnect and run a circuit:
- Point the SDK at a simulator or an available hardware backend
- Build and execute circuits from Python or a Jupyter Notebook
Analyze and iterate:
- Pull results back into your notebook and refine the circuit
Best For: Developers, researchers, and educators who want a cloud platform to learn and build quantum applications without managing hardware.
Worth being clear about the tradeoff: nothing here runs on your machine, and quantum computing solves a different class of problem than an LLM does. If you came to this post to run a chat model offline, skip to the next tool - this one is adjacent, not a substitute.
4. text-generation-webui
For those looking for a balance between powerful features and ease of installation, text-generation-webui offers a comprehensive solution with a web interface.
Key Features:
- Simple installation via pip or conda
- Intuitive web interface with chat and text completion modes
- Support for multiple model backends (GGUF, GPTQ, AWQ, etc.)
- Extensions ecosystem for added functionality
- Character creation and customization
- Built-in knowledge base/RAG capabilities
Getting Started with text-generation-webui:
Option 1: Portable builds (recommended):
- Download from: GitHub Releases
- No installation needed - just unzip and run
- Compatible with GGUF (llama.cpp) models on Windows, Linux, and macOS
Launch the web UI:
# Start the web interface text-generation-webui --listenDownload models through the interface:
- Navigate to the “Models” tab in the web interface
- Download models from Hugging Face directly through the UI
- Select and load your preferred model
Best For: Users who want a feature-rich interface with easy installation and the flexibility to use various model formats.
5. GPT4All
GPT4All provides a polished desktop application experience with minimal setup required, making it ideal for Windows users.
Key Features:
- User-friendly desktop application
- Pre-configured with optimized models
- Built-in chat interface with conversation history
- Local RAG capabilities for document analysis
- Plugin ecosystem for extended functionality
Getting Started with GPT4All:
Install GPT4All:
- Visit gpt4all.io
- Download and install the desktop application
Select a model:
- Use the built-in model downloader
- Choose from various optimized models
Start chatting:
- Use the intuitive chat interface
- Adjust parameters through the settings panel
Best For: Windows users and those who prefer a traditional desktop application experience.
6. LocalAI
LocalAI offers the most versatile platform for developers who need to integrate local LLMs into their applications.
Key Features:
- Support for multiple model architectures (GGUF, ONNX, PyTorch)
- Drop-in replacement for OpenAI API
- Extensible plugin system
- Docker-ready deployment
- Multi-modal capabilities (text, image, audio)
Getting Started with LocalAI:
Using Docker:
# CPU only image: docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-cpu # Nvidia GPU: docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-gpu-nvidia-cuda-12 # CPU and GPU image (bigger size): docker run -ti --name local-ai -p 8080:8080 localai/localai:latest # AIO images (it will pre-download a set of models ready for use, see https://localai.io/basics/container/) docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-cpuDownload models:
http://localhost:8080/browse/
Best For: Developers who need a flexible, API-compatible solution for integrating local LLMs into applications.
Bonus Tool: Jan
Jan is a comprehensive ChatGPT alternative that runs completely offline on your local device, offering full control and privacy.
Key Features:
- Powered by Cortex, a universal AI engine that runs on any hardware
- Model Library with popular LLMs like Llama, Gemma, Mistral, and Qwen
- OpenAI-compatible API server for integration with other applications
- Extensions system for customizing functionality
- Support for remote AI APIs like Groq and OpenRouter when needed
Getting Started with Jan:
Install Jan:
- Visit jan.ai
- Download the installer for your operating system (Windows, MacOS, or Linux)
Launch Jan and Download Models:
- Open Jan after installation
- Navigate to the Model Library
- Choose from various optimized models based on your hardware capabilities
Start Using Jan:
- Use the intuitive chat interface
- Configure model parameters through settings
- Optionally enable the API server for integration with other applications
Best For: Users looking for a polished, all-in-one solution that works across multiple platforms and hardware configurations.
Related: Learn how to self-host Jan as an AI assistant and make it accessible from anywhere.
Best Models for Local Deployment in 2026
The quality of locally runnable models has improved dramatically. Here are the standout models of 2026:
1. Gemma 4 (12B and 26B-A4B)
Google’s Gemma 4 family delivers frontier-level intelligence in a compact package. The flagship 26B-A4B is a Mixture-of-Experts (MoE) model that activates only 4 billion parameters per token from its 26 billion total, hitting 85 tokens per second on consumer hardware like AMD Ryzen AI MAX+ with 128GB RAM. It ships with a 256K context window and function calling that actually works.
The newest member, Gemma 4 12B, landed on June 3, 2026 and fills the gap between the edge-friendly E4B and the 26B MoE. It’s a dense 12B model that fits in 16GB of RAM (or 16GB of VRAM/unified memory), so it runs on a regular laptop. Google claims it gets close to the 26B MoE’s benchmark scores at less than half the total memory footprint. The interesting bit is the architecture: there are no separate multimodal encoders. Vision goes through a single matrix multiplication, and raw audio is projected straight into the same dimensional space as text tokens, both flowing directly into the LLM backbone. That makes it the first mid-sized Gemma with native audio input. Multi-Token Prediction (MTP) drafters cut latency on top of that.
- Release Dates: 26B-A4B (April 2026), 12B (June 3, 2026)
- Official Website: Google Gemma
- Models:
- Gemma 4 12B - dense 12B, native audio + vision, runs in 16GB RAM
- Gemma 4 26B-A4B - 26B params (4B active), runs on 64GB+ RAM
- Gemma 4 31B - Larger variant for high-end hardware
- Hardware Requirements: 16GB RAM for 12B, 32GB+ for 26B-A4B, 64GB+ for 31B
- Strengths: 12B variant runs in 16GB RAM with native audio and vision, 85 t/s on the 26B MoE, 256K context window, encoder-free multimodal architecture, MTP for lower latency
- License: Apache 2.0
- Compatible with: Ollama, LM Studio, text-generation-webui, Jan
2. Kimi K2.5 and K2.6
Moonshot AI’s Kimi K2.5 and the newly released K2.6 represent the pinnacle of open-weight AI models with their revolutionary Agent Swarm architecture. These massive 1 trillion parameter MoE models (32B active per token) can coordinate up to 100 sub-agents for complex tasks, making them ideal for sophisticated agentic workflows. The K2.6 release in April 2026 brings enhanced long-horizon agentic execution capabilities and is now available through Ollama’s Kimi CLI integration.
- Release Dates: K2.5 (January 2026), K2.6 (April 2026)
- Official Website: Moonshot AI
- Models:
- Hardware Requirements: 128GB+ RAM recommended for full capabilities
- Strengths: Agent Swarm (100 sub-agents), AIME 2025 96.1% score, multimodal (text + image + video), thinking mode
- License: Modified MIT (free commercial use below 100M MAU)
- Compatible with: Ollama (via
ollama launch kimi --model kimi-k2.6:cloud), LM Studio, text-generation-webui
3. Qwen3.5 and Qwen3.6
Alibaba’s Qwen3.5 and the newer Qwen3.6 series represent the current state-of-the-art in open-source MoE models. Qwen3.5’s 122 billion parameters with only 10 billion active per token deliver performance that beats GPT-5-mini on most benchmarks all while running on a MacBook with 64GB RAM. The April 2026 Qwen3.6-35B-A3B release brings further efficiency improvements with just 3.5 billion active parameters from 35 billion total.

- Release Dates: Qwen3.5 (March 2026), Qwen3.6 (April 2026)
- Official Website: Qwen
- Models:
- Qwen3.5 - 122B params (10B active), Apache 2.0 license
- Qwen3.6-35B-A3B - 35B params (3.5B active)
- Hardware Requirements: 64GB+ RAM for Qwen3.5, 32GB+ for Qwen3.6-35B-A3B
- Strengths: Apache 2.0 license, 262K context (expandable to 1M), beats GPT-5-mini on benchmarks
- Compatible with: Ollama, LM Studio, LocalAI, Jan
4. GLM-5.1
Zhipu AI’s GLM-5.1 represents a massive leap forward with its 744 billion parameter MoE architecture 40 billion active per token trained on 28.5 trillion tokens. Released in April 2026, this model uses DeepSeek Sparse Attention (DSA) to reduce long-context compute, making it one of the most cost-efficient models at this scale for agentic deployment. It inherits and improves upon GLM-4.7’s production workflow capabilities.
- Release Date: April 2026
- Official Website: Z.ai
- Model: GLM-5.1 (744B total, 40B active)
- Hardware Requirements: 128GB+ RAM for optimal performance
- Strengths: DeepSeek Sparse Attention (DSA), 28.5T training tokens, advanced agentic execution, BrowseComp 67.5
- Compatible with: Ollama, LM Studio, text-generation-webui, Claude Code, Cline, Roo Code
5. NVIDIA Nemotron Cascade 2
NVIDIA’s Nemotron Cascade 2 replaces the previous Nemotron 3 as the company’s flagship inference-optimized model for local deployment. This 30 billion parameter model runs at approximately 54 tokens per second on consumer GPUs (tested on RTX 4060 Ti + RTX 3060 configurations), delivering 15x faster performance than human speech with quality comparable to GPT-4o mini.
- Release Date: March 2026
- Official Website: NVIDIA
- Model: Nemotron Cascade 2 (30B parameters)
- Hardware Requirements: 16GB+ VRAM (NVIDIA GPU optimized)
- Strengths: 54 t/s on consumer GPUs, CUDA-optimized inference, quality comparable to GPT-4o mini
- License: NVIDIA license (open weights with commercial restrictions)
- Compatible with: Ollama, LM Studio, vLLM, SGLang, llama.cpp, NVIDIA NIM
6. GPT-OSS (20B and 120B)
OpenAI’s groundbreaking first open-weight models represent a major shift in the AI landscape, bringing enterprise-grade reasoning capabilities to local deployment. These models excel at advanced reasoning, sophisticated tool calling, and complex agentic workflows, making them ideal for developers building AI applications that require reliable decision-making capabilities.
- Release Date: August 2025
- Official Website: OpenAI
- Models:
- GPT-OSS 20B - Runs on high-end consumer hardware (32GB+ RAM)
- GPT-OSS 120B - Requires enterprise-grade infrastructure
- Strengths: Advanced reasoning, tool calling, agentic workflows, GPT-4 level performance
- Compatible with: Ollama, LM Studio, LocalAI
7. DeepSeek V3.2-Exp
The latest evolution in DeepSeek’s reasoning model family represents cutting-edge advancement in AI reasoning capabilities, approaching the performance levels of O3 and Gemini 2.5 Pro. This experimental model showcases DeepSeek’s continued innovation in mathematical problem solving and complex reasoning tasks. The model features an advanced “thinking mode” that allows it to work through problems step-by-step, making it particularly valuable for developers working on applications requiring logical reasoning, code analysis, and mathematical computations.
- Release Date: September 2025
- Official Website: DeepSeek
- Model: DeepSeek V3.2-Exp
- Hardware Requirements: 16GB RAM (smaller variants) to 64GB+ RAM (larger configurations)
- Strengths: Advanced reasoning, thinking mode, mathematical problem solving, code analysis
- Compatible with: Ollama, LM Studio, text-generation-webui, Jan
8. Mistral Large 3
Mistral AI’s Mistral Large 3 is a state-of-the-art open-weight model and Mistral’s first mixture-of-experts model since the seminal Mixtral series. Trained with 41B active and 675B total parameters on 3000 NVIDIA H200 GPUs, this model represents a substantial step forward in frontier AI capabilities. Released under the Apache 2.0 license, it provides developers with transparency and efficiency for building agentic systems at scale.
- Release Date: December 2025
- Official Website: Mistral AI
- Model: Mistral Large 3 (675B total, 41B active parameters)
- Hardware Requirements: 8×A100 or 8×H100 node (NVFP4 checkpoint available for efficiency)
- Strengths: Frontier-level reasoning, multimodal capabilities (text and images), multilingual (40+ languages), agentic workflows, tool use
- License: Apache 2.0 (fully open-source)
- Compatible with: Ollama, LM Studio, vLLM, TensorRT-LLM, SGLang, Amazon Bedrock, Azure Foundry
Related: Want to run DeepSeek models specifically? Check out our guide on running DeepSeek locally.
Conclusion
Local LLMs have evolved rapidly in 2026, with groundbreaking models like Google’s Gemma 4 (the new 12B variant runs in 16GB of RAM with native audio, while the 26B MoE hits 85 t/s on consumer hardware), Moonshot AI’s Kimi K2.5/K2.6 (1T parameter Agent Swarm models), Alibaba’s Qwen3.5/3.6 (beating GPT-5-mini), Zhipu AI’s GLM-5.1 (744B MoE), NVIDIA’s Nemotron Cascade 2 (54 t/s inference), OpenAI’s GPT-OSS, DeepSeek V3.2-Exp, and Mistral Large 3 bringing frontier-level AI performance to personal devices.
Whether you prefer simplicity (Ollama, GPT4All), GUIs (LM Studio), flexibility (text-generation-webui, LocalAI), or all-in-one solutions (Jan), there’s a perfect fit for every user.
These new models deliver powerful reasoning, multimodal support, agentic coding capabilities, and built-in tool-calling making local AI both capable and secure. Running LLMs locally gives you full data control, no subscription costs, and offline functionality.