In today’s AI landscape, running powerful language models locally gives you privacy, cost savings, and full control over your data.
DeepSeek-R1 models have emerged as impressive open-source AI options that rival commercial alternatives. These models excel at reasoning, coding, and solving complex problems - all while running on your own hardware.
Summary
- Install Ollama
- Get a DeepSeek-R1 Model
# Choose the right size for your computer:
ollama pull deepseek-r1:1.5b # For basic computers (1.1GB)
ollama pull deepseek-r1:7b # For better performance (4.7GB)
- Run the Model
# Start using your AI model:
ollama run deepseek-r1:1.5b
# Or for better reasoning:
ollama run deepseek-r1:7b
- Share API Online with Pinggy (Optional)
ssh -p 443 -R0:localhost:11434 -t qr@free.pinggy.io "u:Host:localhost:11434"
Why Use DeepSeek-R1 Models Locally?
DeepSeek-R1 is a powerful family of AI models with performance similar to high-end commercial options. Running these models locally offers significant benefits:
- Keep your data private - Your prompts never leave your computer
- No usage fees or rate limits - Use the model as much as you want
- Work offline - No internet connection needed
- Choose the right size - From small models for basic computers to larger models for advanced tasks
Getting Started in 3 Simple Steps
Step 1: Install Ollama
Download the installer:
- Visit ollama.com/download
- Download the version for your operating system (Windows, macOS, or Linux)
- Follow the installation instructions
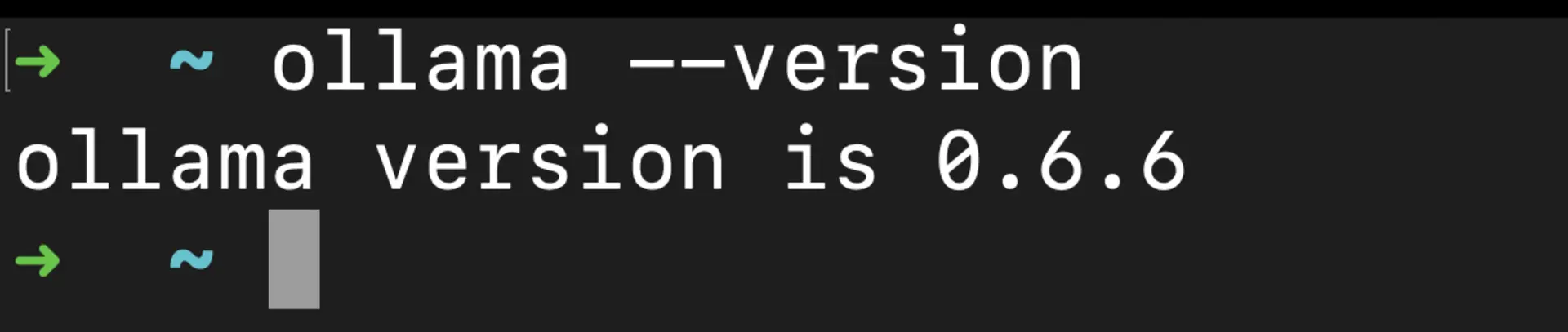
Verify installation:
ollama --version # Should show the current version number
Step 2: Download a DeepSeek-R1 Model
DeepSeek-R1 comes in different sizes to match your computer’s capabilities:
For basic computers (8GB RAM or less):
ollama pull deepseek-r1:1.5b

For mid-range computers (16GB RAM):
ollama pull deepseek-r1:7b
For powerful computers (32GB+ RAM):
ollama pull deepseek-r1:8b # 4.9GB
ollama pull deepseek-r1:14b # 9.0GB
Check your downloaded models:

Step 3: Start Using DeepSeek-R1
Now that you have the model downloaded, let’s start using it:
Run the model:
ollama run deepseek-r1:1.5b

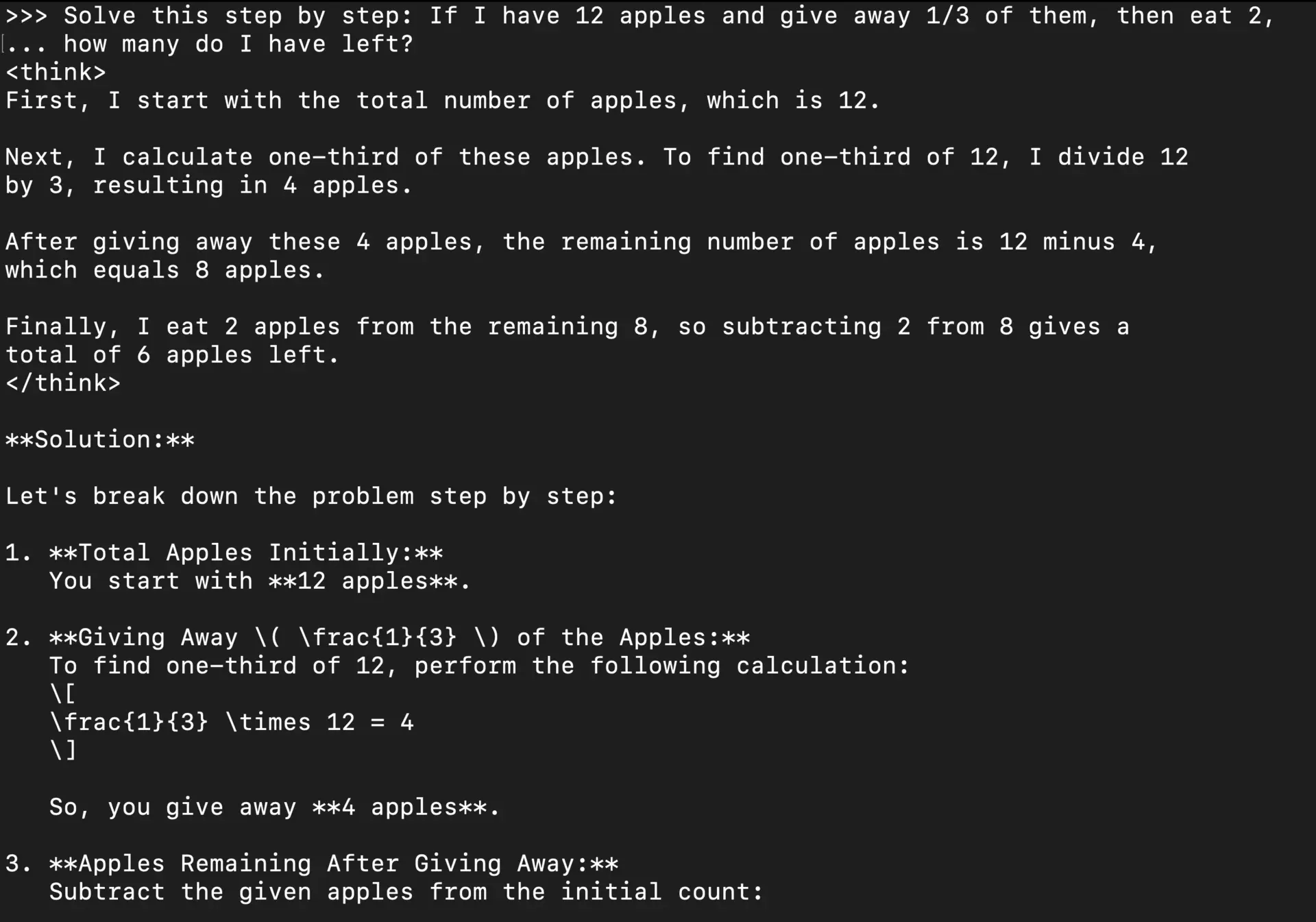
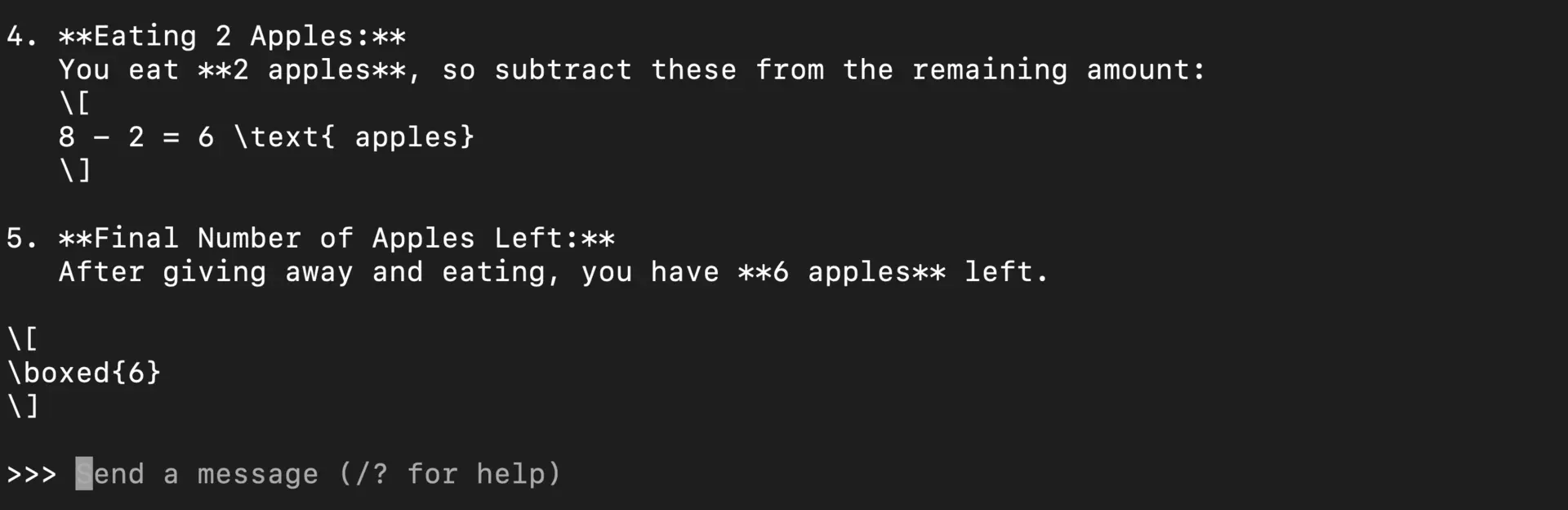
Try reasoning tasks:
You: Solve this step by step: If I have 12 apples and give away 1/3 of them, then eat 2, how many do I have left?
Using the API for Your Applications
You can also use DeepSeek-R1 in your applications through the Ollama API:
Make sure the server is running:
Send requests with curl:
curl --location 'http://localhost:11434/api/chat' \
--header 'Content-Type: application/json' \
--data '{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "user",
"content": "Hello"
}
]
}'
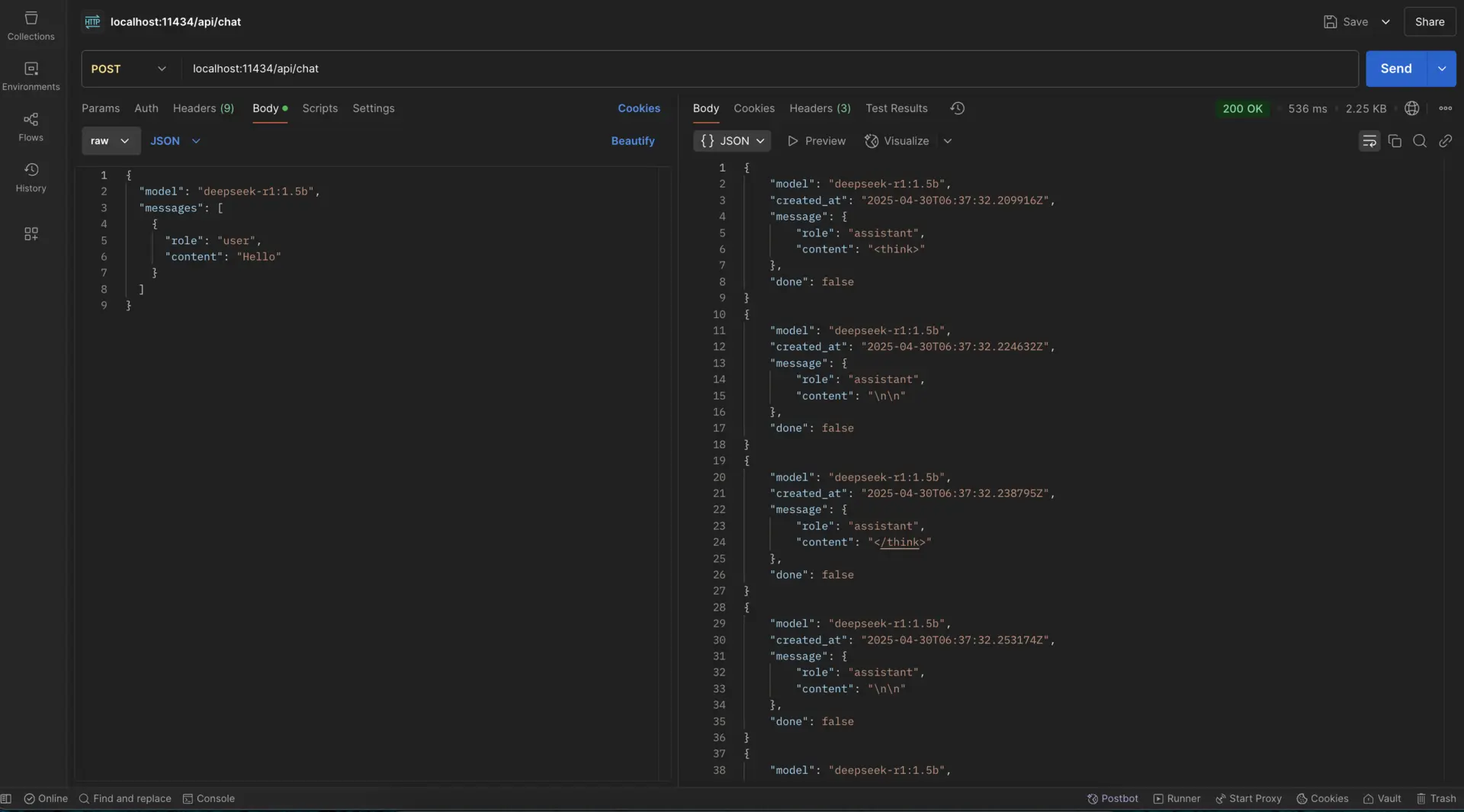
- To test the Ollama API using JavaScript, follow these simple steps:
- Clone the repository from GitHub:
RunOllamaApi.
- Open the project directory in your terminal.
- Install the required dependencies by running
npm install. - Execute the script with
node main.js to test the API.
Using DeepSeek through a GUI with Open WebUI
Instead of interacting with DeepSeek through the command line, you can use Open WebUI - a user-friendly ChatGPT-like interface for Ollama models:
Install Open WebUI via Docker:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Access the UI at http://localhost:3000 in your browser and create an admin account on first use.
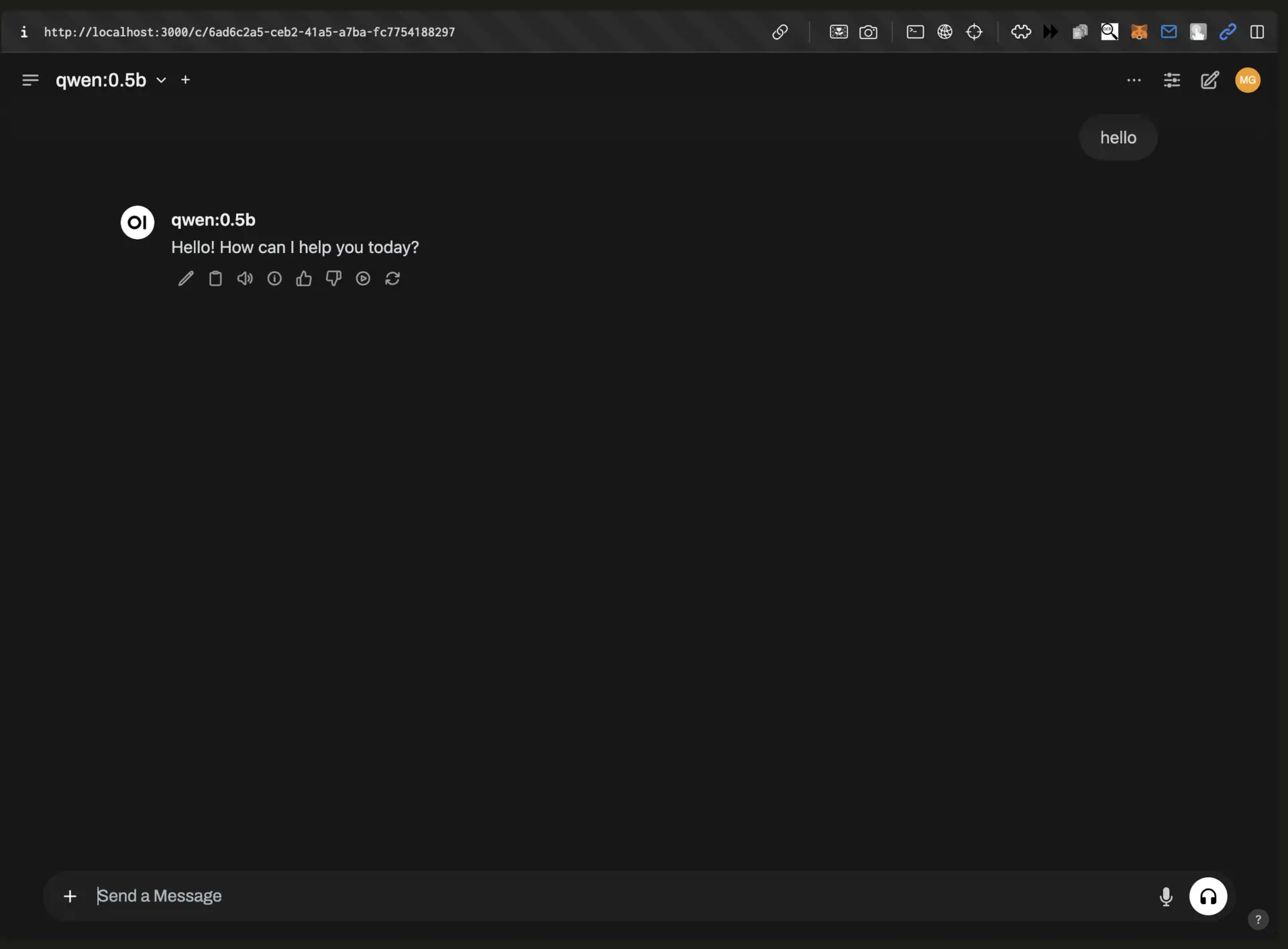
Chat with DeepSeek models:
- Select your DeepSeek model from the dropdown menu in the top-right corner
- Start chatting in a clean, modern interface
- Upload documents for analysis
- Organize conversations in folders
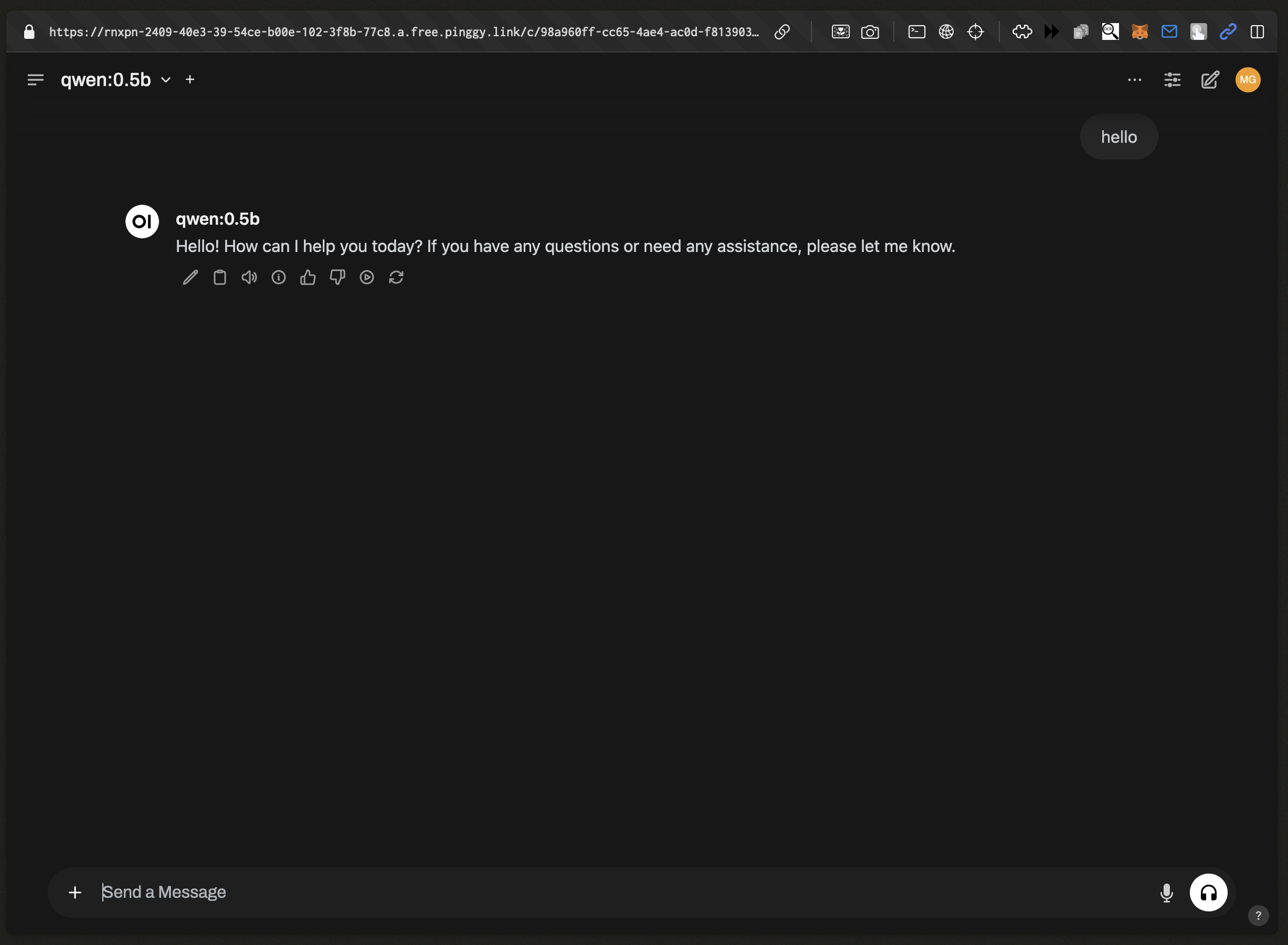
Open WebUI provides several advantages:
- Multi-modal support for image inputs
- Conversation history management
- Preset prompts and system prompts
- Shareable chat URLs
- Mobile-friendly interface
To learn more about Open WebUI, including advanced features, check out our guide on How to Easily Share Ollama API and Open WebUI Online.
Sharing Your Model Online (Optional)
If you want to share your DeepSeek-R1 model with others or access it remotely, you can use Pinggy:
- Start the Ollama server:
ollama serve # Keep this terminal open

Create a public tunnel:
ssh -p 443 -R0:localhost:11434 -t qr@free.pinggy.io "u:Host:localhost:11434"
Command Breakdown:
-p 443: Connects via HTTPS for firewall compatibility.-R0:localhost:11434: Forwards Ollama’s port to Pinggy.qr@free.pinggy.io: Pinggy’s tunneling endpoint.u:Host:localhost:11434: Maps the tunnel to your local port.

After running, you’ll see a public URL like https://abc123.pinggy.link.
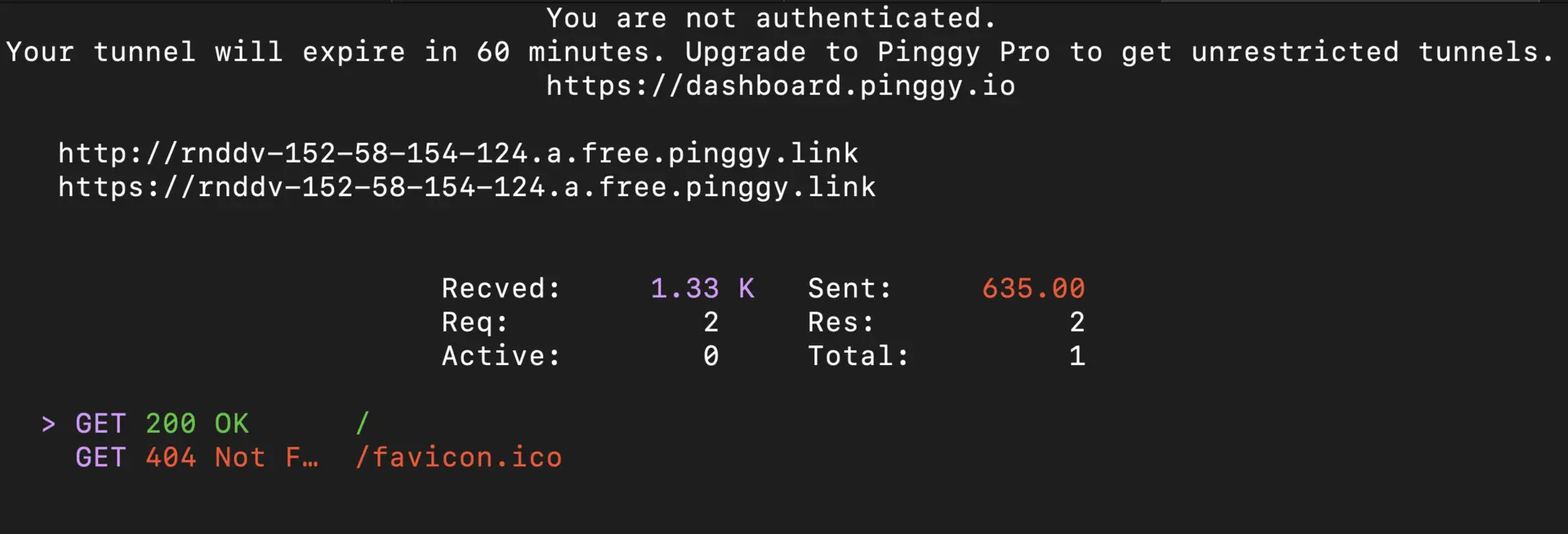
Test and Integrate the Shared API
Verify access using curl or Verify using web browser:
curl https://abc123.pinggy.link/api/tags

Note: For a detailed guide on sharing Ollama models online, check out How to Easily Share Ollama API and Open WebUI Online.
Here are some tips to get the best performance from DeepSeek-R1:
Use quantized models for less memory usage:
# Example: q4_K_M is a 4-bit quantized version that uses less memory
ollama run deepseek-r1:1.5b-q4_K_M
Adjust model parameters for better responses:
ollama run deepseek-r1:1.5b --temperature 0.7 --top_p 0.9
Troubleshooting
Model won’t load?
- Try a smaller model:
ollama pull deepseek-r1:1.5b - Make sure you have enough free RAM
Slow responses?
- Use a quantized model variant
- Try a smaller context size:
ollama run deepseek-r1:1.5b --num_ctx 1024
API connection issues?
- Verify Ollama is running:
ollama serve
About DeepSeek-R1 Models
DeepSeek-R1 models are licensed under MIT, which means you can:
- Use them commercially
- Modify and create derivative works
- Build applications with them
The models come in different sizes based on the original architecture:
- Qwen-based models: 1.5b, 7b, 14b, 32b
- Llama-based models: 8b, 70b
Conclusion
Running DeepSeek-R1 locally with Ollama gives you a powerful AI assistant right on your computer. No cloud accounts, API fees, or privacy concerns - just incredible AI capabilities at your fingertips.
Get started today:
ollama pull deepseek-r1:1.5b && ollama run deepseek-r1:1.5b
For more information, check out the
DeepSeek documentation and the Ollama GitHub repository.