In today’s AI-driven world, deploying large language models (LLMs) like Meta’s Llama 3, Google’s Gemma, or Mistral locally offers unparalleled control over data privacy and customization. However, sharing these tools securely over the internet unlocks collaborative potential—whether you’re a developer showcasing a prototype, a researcher collaborating with peers, or a business integrating AI into customer-facing apps.
This comprehensive guide will walk you through exposing
Ollama’s API and
Open WebUI online using Pinggy, a powerful tunneling service. You’ll learn to turn your local AI setup into a globally accessible resource—no cloud servers or complex configurations required.
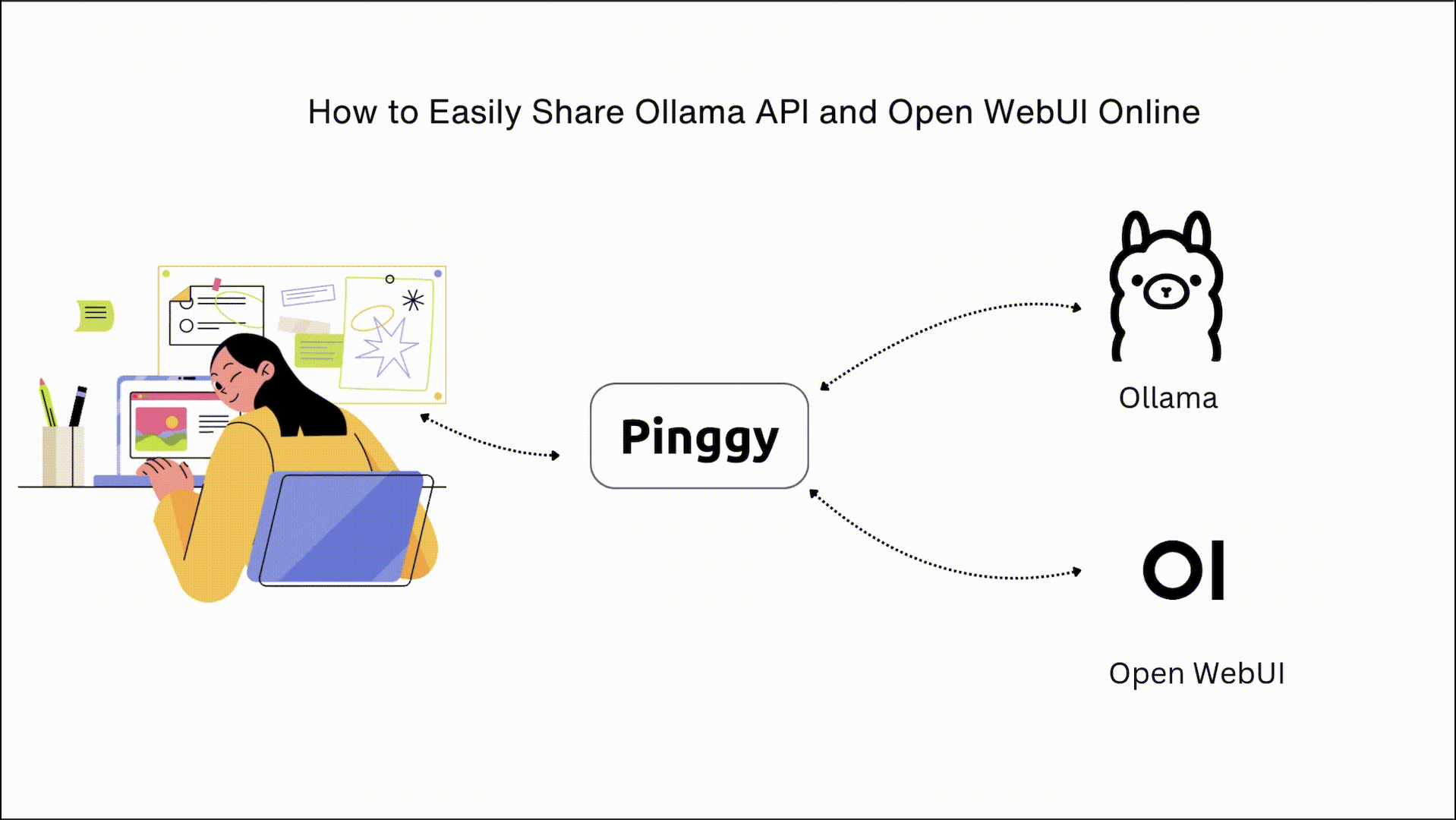
Summary
Install Ollama & Download a Model
Share Ollama API via Pinggy
- Create a secure tunnel for port 11434:
ssh -p 443 -R0:localhost:11434 -t qr@a.pinggy.io "u:Host:localhost:11434"
- Access API via Pinggy URL (e.g.,
https://abc123.pinggy.link).
Deploy Open WebUI
- Run via Docker:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main
Expose WebUI Online
- Tunnel port 3000:
ssh -p 443 -R0:localhost:3000 a.pinggy.io
- Share the generated URL for ChatGPT-like access to your LLMs.
Why Share Ollama and Open WebUI Online?
The Rise of Local AI Deployment
With growing concerns about data privacy and API costs, tools like Ollama and Open WebUI have become essential for running LLMs locally. However, limiting access to your local network restricts their utility. By sharing them online, you can:
- Collaborate remotely with team members or clients.
- Integrate AI into web/mobile apps via Ollama’s API.
- Demo projects without deploying to the cloud.
- Reduce latency by keeping inference local while enabling remote access.
Why Choose Pinggy for Tunneling?
Pinggy simplifies port forwarding by creating secure tunnels. Unlike alternatives like ngrok, it offers:
- Free HTTPS URLs with no signup required.
- No rate limits on the free tier.
- SSH-based security for encrypted connections.
Prerequisites for Sharing Ollama and Open WebUI
A. Install Ollama
- Download Ollama: Visit
ollama.com and choose your OS:
- Windows: Double-click the
.exe installer. - macOS/Linux: Run
curl -fsSL https://ollama.com/install.sh | sh
- Verify Installation:
ollama --version # Should return "ollama version 0.1.30" or higher

B. Download a Model
Ollama supports 100+ models. Start with a lightweight option:
 For multimodal capabilities (text + images), try
For multimodal capabilities (text + images), try llava or bakllava:
C. Install Open WebUI
Open WebUI provides a ChatGPT-like interface for Ollama. Install via Docker:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Access the UI at http://localhost:3000 and create an admin account.

Step-by-Step Guide to Sharing Ollama API
Start Ollama Locally
By default, Ollama runs on port 11434. Start the server:
ollama serve # Keep this terminal open
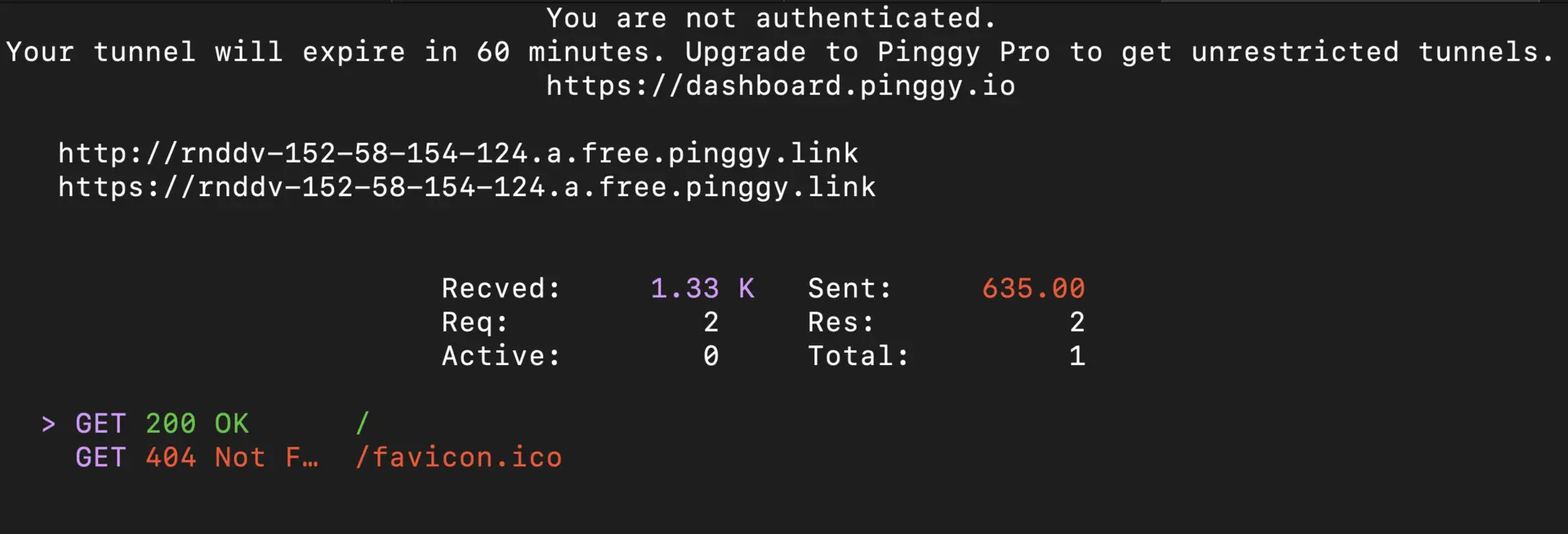
Create a Public URL with Pinggy
Use this SSH command to tunnel Ollama’s API:
ssh -p 443 -R0:localhost:11434 -t qr@a.pinggy.io "u:Host:localhost:11434"

Command Breakdown:
-p 443: Connects via HTTPS for firewall compatibility.-R0:localhost:11434: Forwards Ollama’s port to Pinggy.qr@a.pinggy.io: Pinggy’s tunneling endpoint.u:Host:localhost:11434: Maps the tunnel to your local port.

After running, you’ll see a public URL like https://abc123.pinggy.link.
Test and Integrate the Shared API
Verify access using curl or Verify using web browser:
curl https://abc123.pinggy.link/api/tags

To test the Ollama API using JavaScript, follow these simple steps:
- Clone the repository from GitHub:
RunOllamaApi.
- Open the project directory in your terminal.
- Install the required dependencies by running
npm install. - Execute the script with
node main.js to test the API.
Step-by-Step Guide to Sharing Open WebUI
Expose Open WebUI via Pinggy
Run this command to share port 3000:
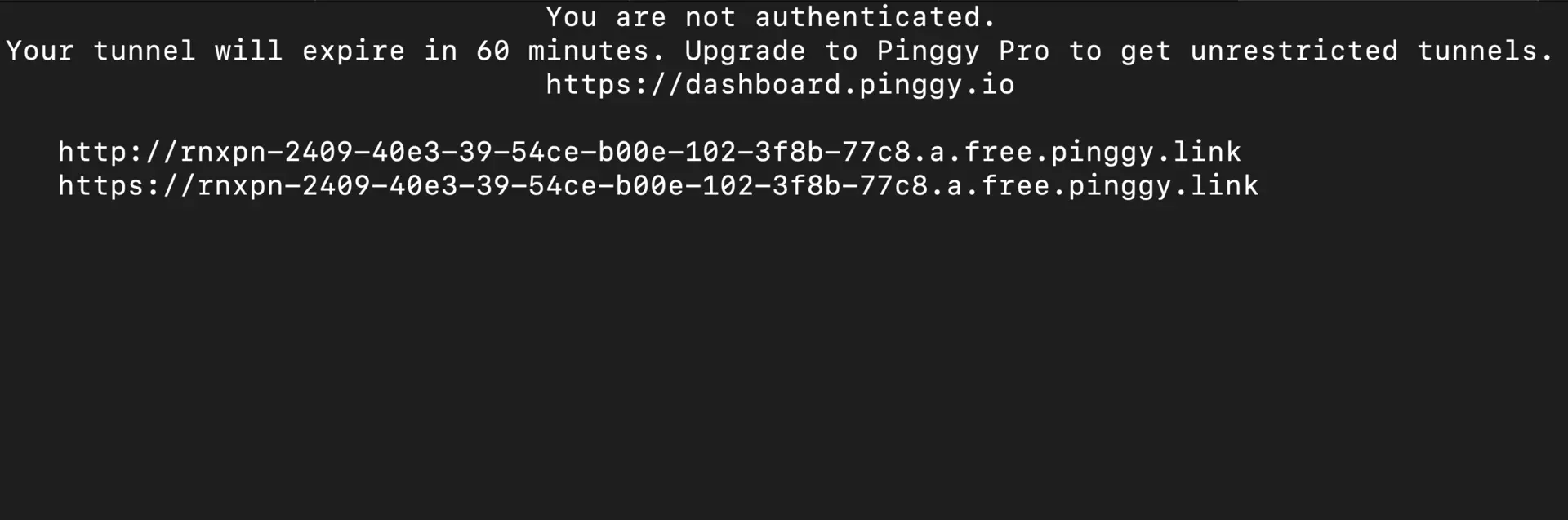
ssh -p 443 -R0:localhost:3000 a.pinggy.io
You’ll receive a URL like https://xyz456.pinggy.link.
Access the WebUI Remotely
- Open
https://xyz456.pinggy.link in a browser. - Log in with your Open WebUI credentials.
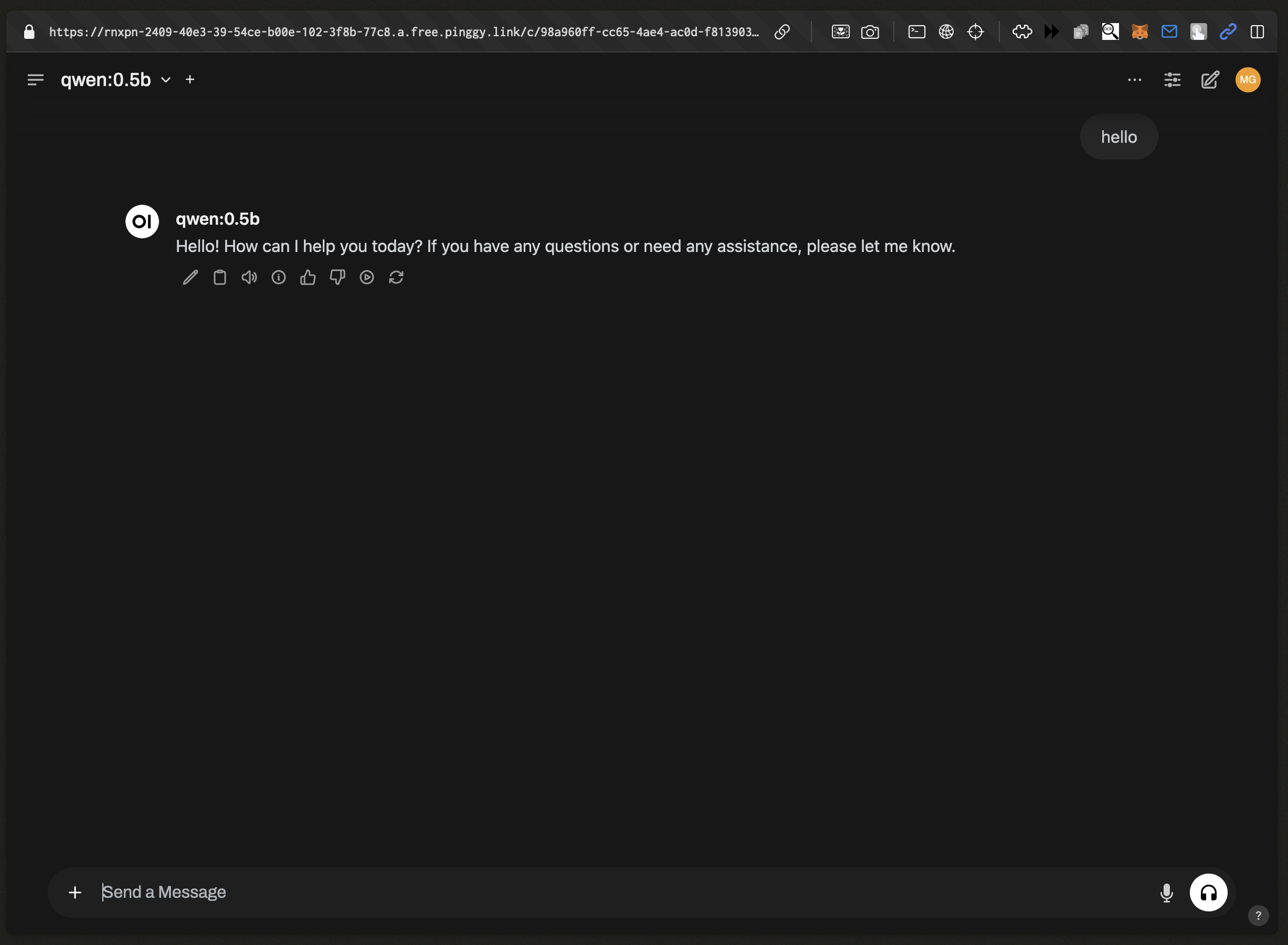
- Leverage features like:
- Chat with models (Llama 3, Mistral, etc.).
- Upload documents for RAG (Retrieval-Augmented Generation).
- Switch models via the top-right dropdown.
Advanced Configuration and Security Best Practices
Secure Your Deployment
You can also configure multiple username-password pairs for enhanced access control. For more details, refer to the official documentation.
Custom Domains and Performance Optimization
With Pinggy Pro (3 USD/month), you can set up a custom domain for your tunnels. This enhances branding and improves accessibility.
For a step-by-step guide on setting up a custom domain, refer to the Pinggy Custom Domain Documentation.
Real-World Use Cases for Remote AI Access
Collaborative Development
Distributed teams can:
- Share a single Ollama instance for code review and documentation generation.
- Train custom models collaboratively using Open WebUI’s RAG features.
Customer-Facing Applications
Expose Ollama’s API to power:
- AI chatbots for 24/7 customer support.
- Content generation tools for blogs, social media, or product descriptions.
Academic and Research Workflows
Researchers can securely share access to proprietary models with peers without exposing internal infrastructure.
Troubleshooting Common Issues
Connection Errors
- “Connection Refused”:
- Ensure Ollama is running:
ollama serve. - Check firewall settings for ports
11434 and 3000.
Model Loading Failures
- Verify model compatibility with your Ollama version.
- Free up RAM for larger models like
llama3:70b (requires 40+ GB).
Conclusion and Next Steps
By combining Ollama, Open WebUI, and Pinggy, you’ve created a secure, shareable AI platform without relying on cloud services. This setup is ideal for startups, researchers, or anyone prioritizing data control.