The AI world in 2025 looks completely different from just two years ago. What started as an American-dominated field has evolved into a genuine three-way competition between the United States, China, and Europe. Each region has developed its own approach to AI, and honestly, it’s made the whole space way more interesting.
The US still leads in breakthrough research and commercial applications, but China has been moving fast with cost-effective models that perform surprisingly well. Meanwhile, Europe has been playing the long game with privacy-focused solutions and the regulatory framework that’s starting to influence how everyone builds AI.
What’s really cool is that this competition isn’t just about bigger models anymore. It’s about different philosophies of AI development, and each region’s strengths are pushing the others to innovate in ways they might not have otherwise.
Summary
The global AI race has three distinct leaders, each with their own strengths:
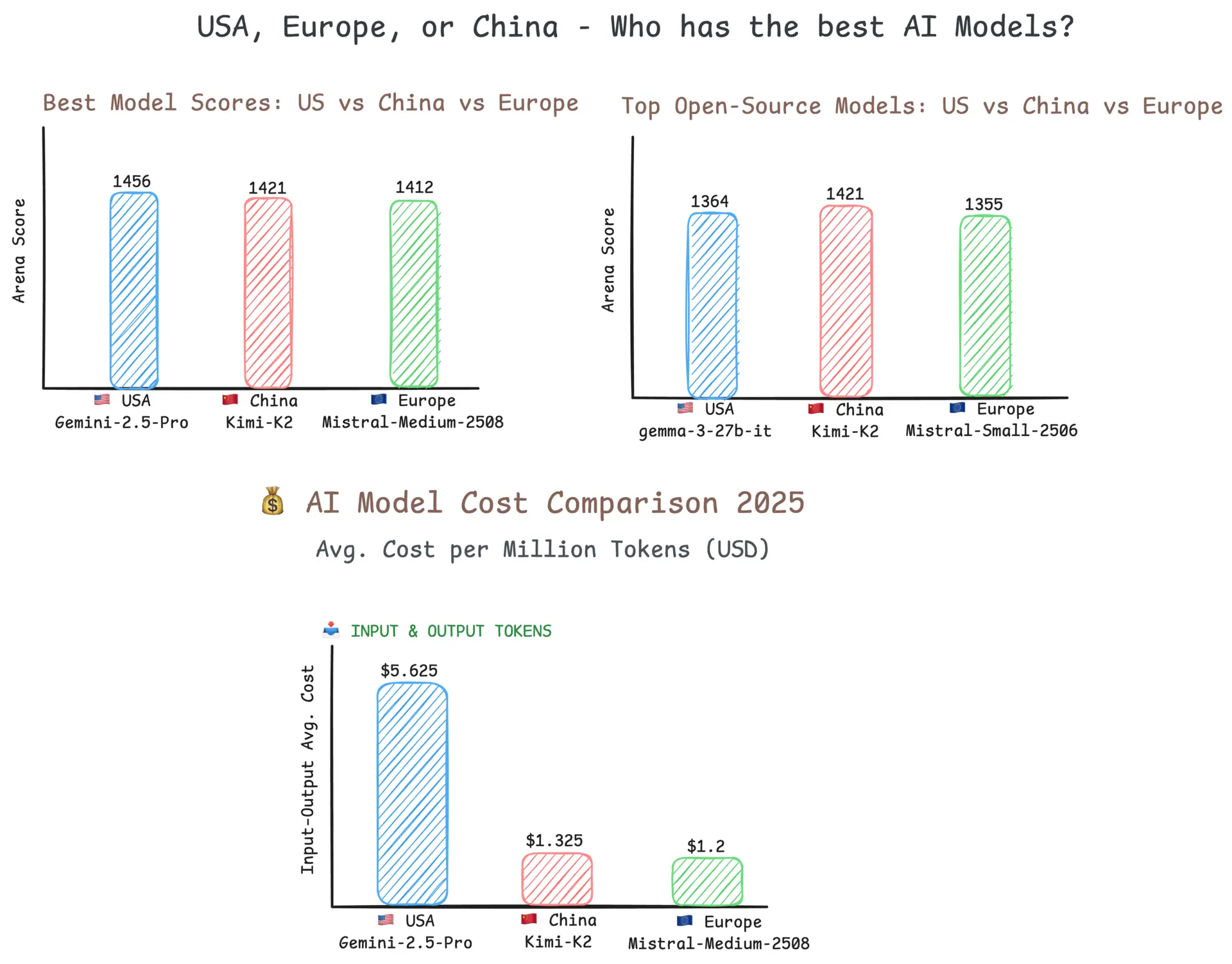
USA dominates with breakthrough models like Gemini 2.5 Pro (1456 Arena score), GPT-5-high (1447), and Claude 4 Sonnet (1447) leading performance benchmarks.
China competes with efficient alternatives including DeepSeek-V3 (1419 Arena score),
Qwen3-Coder (1382), and GLM-4.5 (1410) offering cost-effective performance.
Europe focuses on ethical AI with Mistral Medium 2508 (1310 Arena score), Falcon 180b Chat (1149), and regulatory leadership through the AI Act.
Image generation sees USA leading with DALL-E 3 and Midjourney v6.1, China advancing with Kling AI, and Europe contributing through Stability AI.
Video generation features USA’s Sora and Runway Gen-3, China’s Kling Video, and Europe’s Stable Video Diffusion.
How the Global AI Race Actually Works in 2025
The AI competition has gotten way more nuanced than just “who has the biggest model.” Each region has basically developed its own personality when it comes to AI development, and it shows in everything from their model architectures to their business strategies.
America is still the innovation powerhouse, throwing massive resources at breakthrough research and pushing the absolute limits of what AI can do. Companies like OpenAI, Anthropic, and Google are in this constant race to build the next game-changing model, and they’re not afraid to spend big to get there.
China took a different approach entirely. Instead of trying to out-spend the Americans, they focused on efficiency and rapid iteration. Chinese companies can take a research paper published on Monday and have a working implementation by Friday. This speed has let them close the performance gap while keeping costs way lower.
Europe decided to play the long game with regulation and ethics. While American and Chinese companies were racing to build the most powerful models, Europe was quietly building the framework that everyone else would eventually have to follow. The AI Act isn’t just European law anymore – it’s becoming the global standard for responsible AI development.
USA: Still the Innovation Leader
The American AI scene in 2025 is basically what you’d expect from Silicon Valley on steroids. These companies have ridiculous amounts of funding, access to the best talent, and a culture that rewards pushing boundaries even when it seems impossible.
The Big Three American Models
Arena scores given out by LMArena use the Elo rating system from chess, where real users vote between anonymous AI models in head-to-head battles. Higher scores mean the model wins more often against competitors.
| Model | Company | Arena Score | Key Strength | Best Use Case |
|---|
| Gemini 2.5 Pro | Google | 1456 | Multimodal integration | Complex reasoning with images/code |
| GPT-5-high | OpenAI | 1447 | Advanced reasoning | Mathematical problem-solving |
| Claude 4 Sonnet | Anthropic | 1447 | Safety & reliability | Professional coding tasks |
| GPT-4o o3 | OpenAI | 1444 | Multimodal excellence | Creative applications |
OpenAI’s GPT-5 is probably the most impressive technical achievement here. The o3 architecture they’re using has completely changed how we think about AI reasoning. Instead of just pattern matching, it actually seems to work through problems step by step, kind of like how a human would approach a complex math problem.
Claude 4 Sonnet took a different approach and focused on being the most reliable model you can actually trust in production. Anthropic spent a ton of time on constitutional AI training, which basically means the model has been taught to follow instructions precisely while avoiding anything harmful. That 64.93% success rate on SWE-bench coding tasks isn’t just impressive – it’s actually usable for real development work.
Google’s Gemini 2.5 Pro is currently sitting at the top of the leaderboard, and honestly, it makes sense. Google has been doing machine learning longer than almost anyone, and they have access to more data and compute than most countries. The multimodal capabilities are where it really shines – you can throw text, images, and code at it, and it just handles everything seamlessly.
China: The Efficiency Masters
China’s approach to AI has been fascinating to watch. Instead of trying to beat American companies at their own game, they’ve basically redefined what success looks like. Chinese AI companies have figured out how to build models that perform almost as well as the American giants while using way less compute and costing a fraction of the price.
Top Chinese Language Models
| Model | Company | Arena Score | Parameters | Key Innovation |
|---|
| DeepSeek-V3 | DeepSeek | 1419 | 671B (MoE) | Cost efficiency |
| GLM-4.5 | Zhipu AI | 1410 | 355B | Multilingual focus |
| Qwen3-Coder | Alibaba | 1382 | 480B (MoE) | Open-source excellence |
| Baichuan3 | Baichuan | N/A | 130B | Enterprise solutions |
Qwen3-Coder is probably the most impressive thing to come out of China this year. Alibaba basically took everything they learned from building cloud infrastructure and applied it to AI model architecture. With an arena score of 1375, it’s competitive with many premium models while being completely open-source under Apache 2.0 – you can literally download 480 billion parameters worth of cutting-edge AI and use it however you want.
DeepSeek-V3 is where things get really interesting from an engineering perspective. With an arena score of 1380, it’s performing at near-GPT-4 levels while requiring about 10 times less compute for inference. That’s not just impressive – it’s game-changing for anyone who wants to run AI at scale without burning through their entire budget.
The speed at which Chinese companies iterate is honestly kind of intimidating if you’re competing with them. While American companies spend months perfecting a model before release, Chinese companies will push updates weekly based on user feedback and new research. It creates this incredibly dynamic environment where models are constantly improving.
Europe: Playing the Long Game
Europe’s approach to AI has been completely different from both the US and China. Instead of racing to build the biggest or fastest models, they’ve focused on building the framework that everyone else will eventually have to follow. It’s a smart strategy that’s starting to pay off in ways that aren’t always obvious from benchmark scores.
European AI Models and Initiatives
| Model/Initiative | Organization | Arena Score | Country | Focus Area |
|---|
| Mistral Medium 2508 | Mistral AI | 1310 | France | Privacy-first enterprise |
| Falcon 180b Chat | TII | 1149 | UAE/Europe | Open-source leadership |
| BLOOM | BigScience | N/A | Multi-European | Multilingual research |
| AI Act | European Union | N/A | EU-wide | Regulatory framework |
Mistral AI is probably the best example of the European approach. With an arena score of 1310, they’re not trying to build the absolute best model – they’re building the best model that you can actually trust with your sensitive data. For European companies that can’t legally send data to US or Chinese servers, Mistral provides a genuinely competitive alternative that keeps everything within European borders.
The AI Act is where Europe’s long-term thinking really shows. While everyone else was focused on building better models, Europe was building the legal framework that defines how AI can be used. Now that the Act is in effect, companies worldwide are having to redesign their AI systems to comply with European standards, even if they’re not based in Europe.
BLOOM represents something unique in the AI world – a truly collaborative, multilingual model built by researchers from across Europe. It’s not the most powerful model out there, but it demonstrates how European values of collaboration and openness can create something that no single company could build alone.
Image Generation: Regional Creative Powerhouses
Each region has developed distinct approaches to AI image generation, reflecting their tech hubs and cultural priorities.
Global Image Generation Leaders
| Model | City/Region | Company | Specialty |
|---|
| DALL-E 3 | San Francisco, USA | OpenAI | Photorealistic images |
| Midjourney v6.1 | San Francisco, USA | Midjourney | Artistic creativity |
| Flux.1 Pro | Freiburg, Germany | Black Forest Labs | Text rendering |
| Kling AI | Beijing, China | Kuaishou | Cultural content |
| CogView | Beijing, China | Tsinghua/Zhipu | Chinese text integration |
| Stable Diffusion 3 | London, UK | Stability AI | Open-source flexibility |
San Francisco dominates the premium image generation market with DALL-E 3 setting the photorealism standard and Midjourney becoming the creative professional’s favorite. Beijing’s models excel at cultural context and Chinese text integration, while London’s Stability AI democratized image generation through open-source accessibility.
The quality gap has narrowed significantly, but regional strengths remain distinct. American models lead in overall quality, Chinese models offer cost-effective cultural relevance, and European models provide customizable open-source foundations.
Video Generation: City-Based Innovation Hubs
Video generation showcases how different tech cities approach AI innovation, with each bringing unique strengths to this cutting-edge field.
Global Video Generation Leaders
| Model | City/Region | Company | Max Length | Innovation |
|---|
| Sora | San Francisco, USA | OpenAI | 60 seconds | Physics simulation |
| Runway Gen-3 | New York, USA | Runway ML | 10 seconds | Professional tools |
| Kling Video | Beijing, China | Kuaishou | 120 seconds | Extended duration |
| Vidu AI | Shanghai, China | Shengshu Technology | 16 seconds | Rapid processing |
| Stable Video Diffusion | London, UK | Stability AI | 4 seconds | Open-source base |
| Pika Labs | Palo Alto, USA | Pika | 4 seconds | User accessibility |
San Francisco’s Sora revolutionized the field with physics-aware 60-second videos, while New York’s Runway focuses on professional creative tools. Beijing’s Kling Video actually beats Sora on duration with 120-second clips, and Shanghai’s Vidu emphasizes rapid generation speeds. London provides the open-source foundation that enables global innovation.
The regional approaches are clear: American cities prioritize breakthrough capabilities, Chinese cities focus on practical improvements like longer videos and faster processing, while European cities contribute open-source foundations for widespread adoption.
The Benchmark Reality Check
Let’s talk numbers, because while all this regional analysis is interesting, performance benchmarks tell the real story of where each region stands.
| Metric | USA | China | Europe | Winner |
|---|
| Chatbot Arena (Top Model) | 1456 (Gemini 2.5 Pro) | 1380 (DeepSeek-V3) | 1310 (Mistral Large 2) | 🇺🇸 USA |
| SWE-bench Coding | ~64% | <60% | <60% | 🇺🇸 USA |
| Cost per 1M tokens | $10-30 | $2-8 | $10-20 | 🇨🇳 China |
| Inference Speed | Medium | Fast | Medium | 🇨🇳 China |
| Privacy Compliance | Medium | Low | High | 🇪🇺 Europe |
The US still leads in raw performance metrics, with top models like Gemini 2.5 Pro (1456) and GPT-5-high (1447) setting the arena score benchmark. But the gap is narrowing fast – Chinese models like DeepSeek-V3 (1380) are getting close enough that the performance difference might not matter for many use cases.
Where China really shines is cost efficiency. Chinese models often deliver 80-90% of the performance of American models at 20-30% of the cost. For businesses that need to process large volumes of text or run AI at scale, that cost difference can be the deciding factor.
Europe’s strength shows up in areas that are harder to benchmark but increasingly important. Privacy compliance, data sovereignty, and ethical AI practices don’t show up in performance scores, but they’re becoming crucial for enterprise adoption, especially in regulated industries.
Conclusion
The global AI race in 2025 has created a diverse ecosystem where each region excels at different things. The USA leads in breakthrough performance, China dominates cost-effective scaling, and Europe sets the standard for ethical AI development. This competition benefits everyone by ensuring there’s genuinely a right tool for every job.
For readers who want to explore different AI tools categorized by use case whether for coding, images, or business applications resources like
this directory of AI tools can be a good starting point.