
AI video generation has transformed from a novelty into a production-ready tool in 2026. What began as blurry, seconds-long clips with obvious artifacts has evolved into cinematic-quality footage with realistic physics, coherent motion, and synchronized audio. Whether you’re a filmmaker exploring new creative possibilities, a marketer scaling content production, or a developer building video-powered applications, today’s AI video models offer capabilities that were unimaginable just two years ago.
The most significant developments this year include native 4K output, videos extending to 20+ seconds, synchronized audio generation, and dramatically improved physics simulation. Models now understand cause-and-effect relationships, maintain character consistency across scenes, and produce motion that feels natural rather than AI-generated. The gap between AI-generated and traditionally produced video continues to narrow.
In this guide, we’ll explore the best video generation AI models in 2026, covering both proprietary platforms and open-source alternatives, to help you find the right tool for your creative and professional needs.
Comparison Table for AI Video Generation Models
| AI Model | Best For | Pricing | Key Strength |
|---|
| Sora 2 | Cinematic quality & physics | ChatGPT Plus ($20/mo) | Realistic physics & synchronized audio |
| Google Veo 3.1 | 4K professional production | Gemini Advanced ($19.99/mo) | Native 4K & character consistency |
| Runway Gen-4.5 | Creative control & film production | From $12/mo | Motion brushes & scene consistency |
| Kling 2.6 | Short-form & social content | Free tier / Paid plans | Simultaneous audio-visual generation |
| Luma Ray3 | Photorealistic motion | From $7.99/mo | Hi-Fi 4K HDR & natural physics |
| Pika 2.5 | Quick social videos & effects | From $8/mo | Pikaswaps & special effects |
| Wan2.2 (Open Source) | Local generation & customization | Free (open-source) | MoE architecture & consumer GPU support |
| LTX-2 (Open Source) | 4K with audio & commercial use | Free (Apache 2.0) | Native 4K 50fps with synchronized audio |
| HunyuanVideo 1.5 | Efficient local generation | Free (open-source) | 13.6GB VRAM for 720p & fast inference |
Summary
Top Proprietary AI Video Models:
- Sora 2: Cinematic physics, synchronized audio, Disney characters | $20/mo (Plus) or $200/mo (Pro)
- Google Veo 3.1: Native 4K, character consistency, vertical video support | $19.99/mo (Gemini Advanced)
- Runway Gen-4.5: #1 benchmark score, motion brushes, scene consistency | From $12/mo
- Kling 2.6: Simultaneous audio-visual, up to 2 min videos | Free tier available
- Luma Ray3: Hi-Fi 4K HDR, superior physics simulation | From $7.99/mo
- Pika 2.5: Pikaswaps, Pikaffects, fast 42s renders | From $8/mo
Top Open-Source Models:
- Wan2.2: MoE architecture, 8.19GB VRAM min, bilingual text in videos | Free
- LTX-2: Native 4K 50fps with audio, Apache 2.0, licensed training data | Free (<$10M ARR)
- HunyuanVideo 1.5: 8.3B params, 75s gen time on RTX 4090, 13.6GB VRAM | Free
Why AI Video Generation Matters in 2026
The video generation landscape has matured significantly over the past year. What started as experimental technology producing inconsistent results has become a reliable production tool. The improvements span multiple dimensions: resolution has jumped from 720p to native 4K, video length has extended from 3-5 seconds to 20+ seconds, and perhaps most importantly, the physics simulation now produces believable real-world interactions.
One of the most transformative changes is native audio generation. Models like Sora 2, Veo 3.1, and Kling 2.6 can now generate synchronized sound effects, ambient audio, and even dialogue that matches the visual content. This eliminates a significant post-production step and makes AI video generation viable for end-to-end content creation.
For developers, the availability of production-ready APIs opens new possibilities for video-powered applications. Whether you’re building automated content pipelines, interactive experiences, or creative tools, these APIs provide programmatic access to state-of-the-art video generation. Open-source models like LTX-2 and Wan2.2 further democratize access by enabling local deployment on consumer hardware.
When selecting an AI video generator, consider your specific requirements. For cinematic quality and realistic physics, Sora 2 and Runway Gen-4.5 lead the field. For maximum flexibility and privacy, open-source options like Wan2.2 and LTX-2 provide full control over the generation process. For rapid iteration and social media content, Pika 2.5 and Kling offer fast, accessible workflows.
Best AI Video Generation Models in 2026
Let’s examine the top video generation models available in 2026, exploring their capabilities, ideal use cases, and pricing structures.
1. Sora 2 (OpenAI)
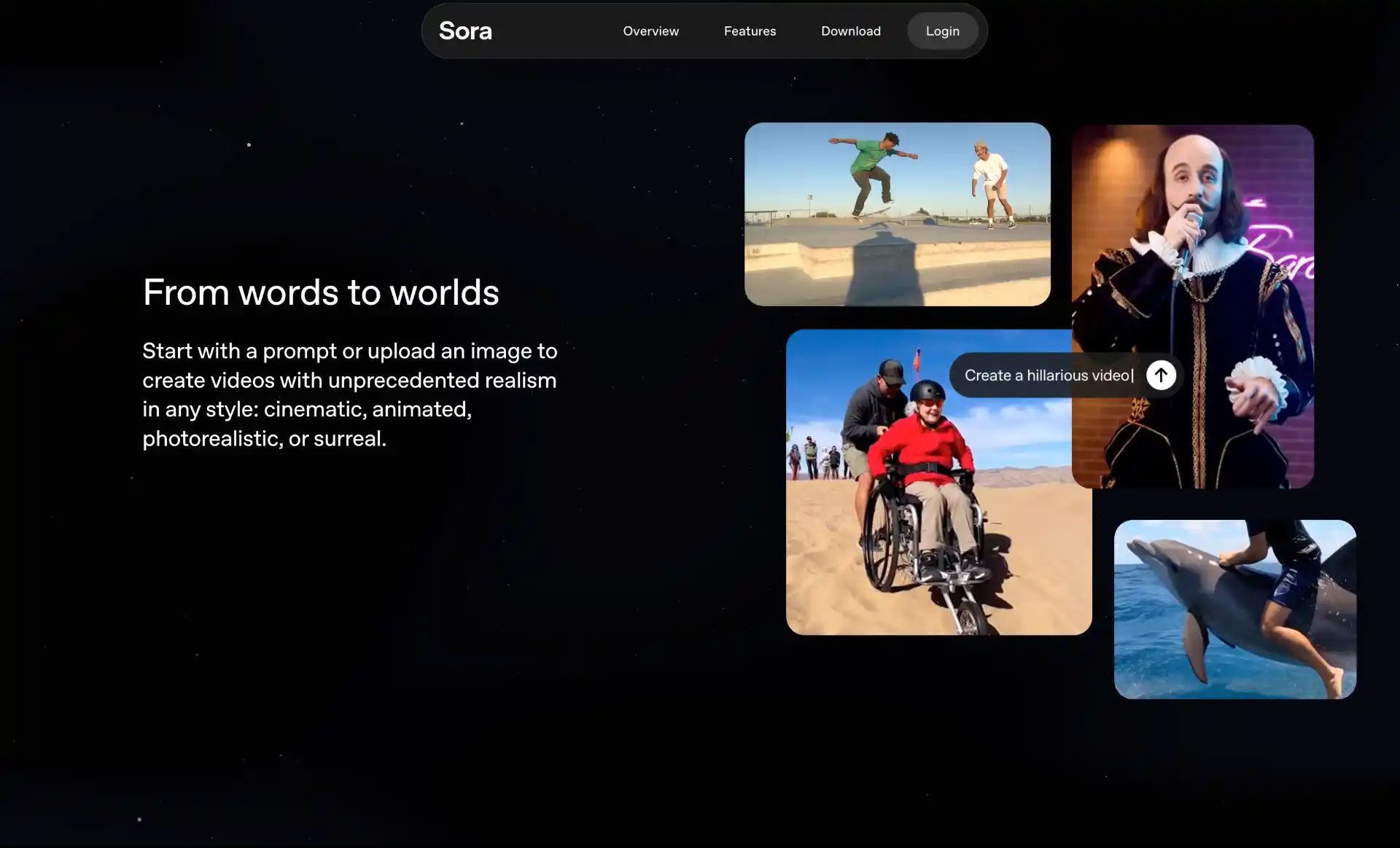
Sora 2 represents OpenAI’s most advanced video generation model, released in September 2025 and continuously improved since. The model excels at producing cinematic-quality videos with realistic physics, synchronized audio, and remarkable prompt adherence. Where previous video models struggled with physical accuracy, Sora 2 demonstrates understanding of cause-and-effect relationships: if a basketball player misses a shot, the ball rebounds realistically off the backboard.
What distinguishes Sora 2 from competitors is its ability to handle complex motion scenarios that were previously impossible for AI. The model can generate Olympic gymnastics routines, accurate backflips on paddleboards with realistic buoyancy dynamics, and figure skating triple axels with proper physics. This physical understanding extends to subtle details like fabric movement, light interactions, and object permanence across frames.
OpenAI has also launched a social iOS app powered by Sora 2, allowing users to create, remix, and share generations. The “characters” feature lets you capture your likeness through a video recording and drop yourself into any Sora scene with remarkable fidelity. A landmark Disney partnership announced in early 2026 allows fans to generate videos featuring over 200 Disney, Marvel, Pixar, and Star Wars characters.
Key Features of Sora 2:
- Cinematic physics - Realistic simulation of complex motions including gymnastics, water dynamics, and fabric behavior
- Synchronized audio - Native dialogue and sound effects generation matching visual content
- Character cameos - Create and reuse consistent characters across generations
- Multiple variants - sora-2 for rapid iteration, sora-2-pro for production quality
- 25-second videos - Pro users can generate extended content with storyboard support
- Disney characters - Licensed access to 200+ characters from Disney’s brands
- Social features - Create, remix, and share videos within the Sora app ecosystem
Sora 2 Pricing:
Sora 2 is available through ChatGPT Plus at $20/month with standard access, or ChatGPT Pro at $200/month for unlimited access and sora-2-pro quality. All users can generate 15-second videos, while Pro users get 25-second capability.
2. Google Veo 3.1
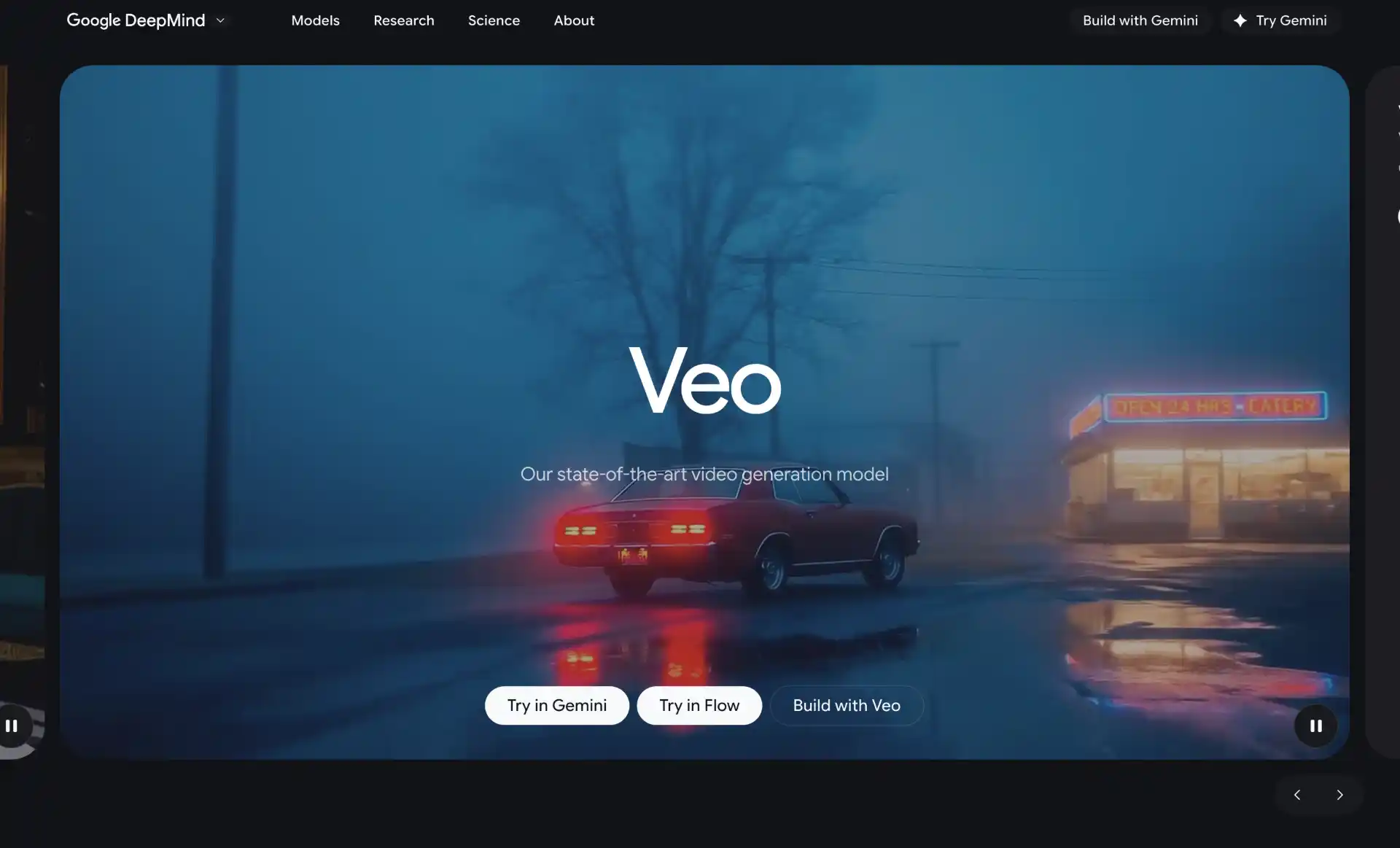
Google Veo 3.1, released in January 2026, brings professional-grade video generation to Google’s ecosystem with native 4K resolution, vertical video support for platforms like YouTube Shorts, and significantly improved character consistency. The update addresses one of the most persistent challenges in AI video: maintaining coherent facial features and identity across scene changes.
Veo 3.1’s “Ingredients to Video” feature allows creators to provide up to four reference images per generation, enabling precise control over subjects, styles, and compositions. Character identity now stays consistent across scene changes, and even with brief prompts, expressions and movements appear natural. The model also introduced native vertical video support optimized for mobile-first platforms.
The integration with Google’s ecosystem is seamless. Veo 3.1 is accessible through the Gemini app, YouTube Shorts, Flow, the Gemini API, and Vertex AI. For developers, this means straightforward integration with existing Google Cloud workflows. All videos generated with Veo include SynthID watermarking for AI content identification.
Key Features of Veo 3.1:
- Native 4K resolution - Professional-grade output quality with upscaling support
- Vertical video - Optimized for YouTube Shorts and mobile platforms
- Character consistency - Maintains identity across scene changes and camera angles
- Multi-image reference - Up to four reference images per generation
- Native audio - Sound effects, ambient noise, and dialogue generation
- Google ecosystem - Available across Gemini, YouTube, Vertex AI, and API
- SynthID watermarking - Automatic AI content identification for safety
Veo 3.1 Pricing:
Veo 3.1 is available through Gemini Advanced at $19.99/month for consumer access. Professional and enterprise access through Google Cloud and Vertex AI follows usage-based pricing. The maximum duration is 8 seconds per generation, requiring stitching for longer content.
3. Runway Gen-4.5
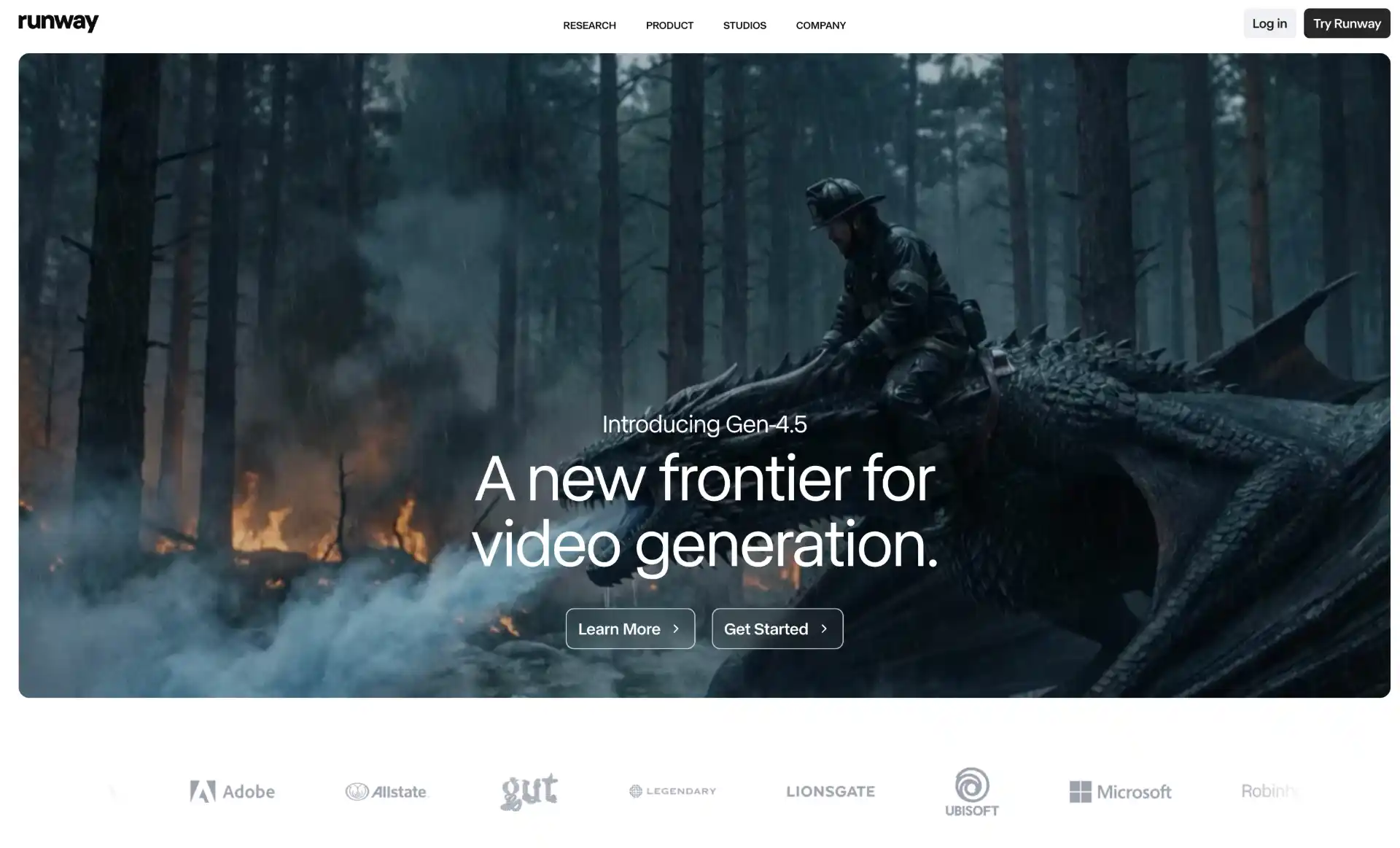
Runway Gen-4.5 currently holds the top position on the Artificial Analysis Text to Video benchmark with 1,247 Elo points, outperforming offerings from OpenAI and Google in independent testing. The model demonstrates superior understanding of physics, human motion, camera movement, and cause-and-effect relationships compared to earlier generations.
What makes Runway particularly valuable for creators is its precise control mechanisms. Motion brushes allow you to specify exactly which parts of an image should move and how, giving granular control that text prompts alone cannot achieve. The model can generate consistent characters, locations, and objects across scenes using just a single reference image, making it ideal for long-form narrative content.
Gen-4.5 adopts a hybrid architecture combining diffusion models with neural rendering technologies. Scene understanding modules analyze spatial relationships and object properties, while physics engine simulators predict material dynamics under different environmental conditions. Gen-4 Turbo offers a faster variant for brainstorming, generating full videos in about 30 seconds at half the credit cost.
Key Features of Runway Gen-4.5:
- Top benchmark performance - Highest-rated model on Artificial Analysis leaderboard
- Motion brushes - Precise control over which elements move and how
- Scene consistency - Maintain characters, objects, and locations across scenes
- Physics simulation - Accurate prediction of material dynamics and interactions
- Gen-4 Turbo - Fast, cost-efficient variant for rapid iteration
- Single reference generation - Create consistent content from one reference image
- Professional integration - Designed for film production and creative workflows
Runway Gen-4.5 Pricing:
Runway Gen-4.5 requires a paid subscription, starting with the Standard plan at $12/month. Gen-4 Turbo uses half the credits per second compared to standard Gen-4, making it ideal for experimentation and concepting.
4. Kling 2.6 (Kuaishou)
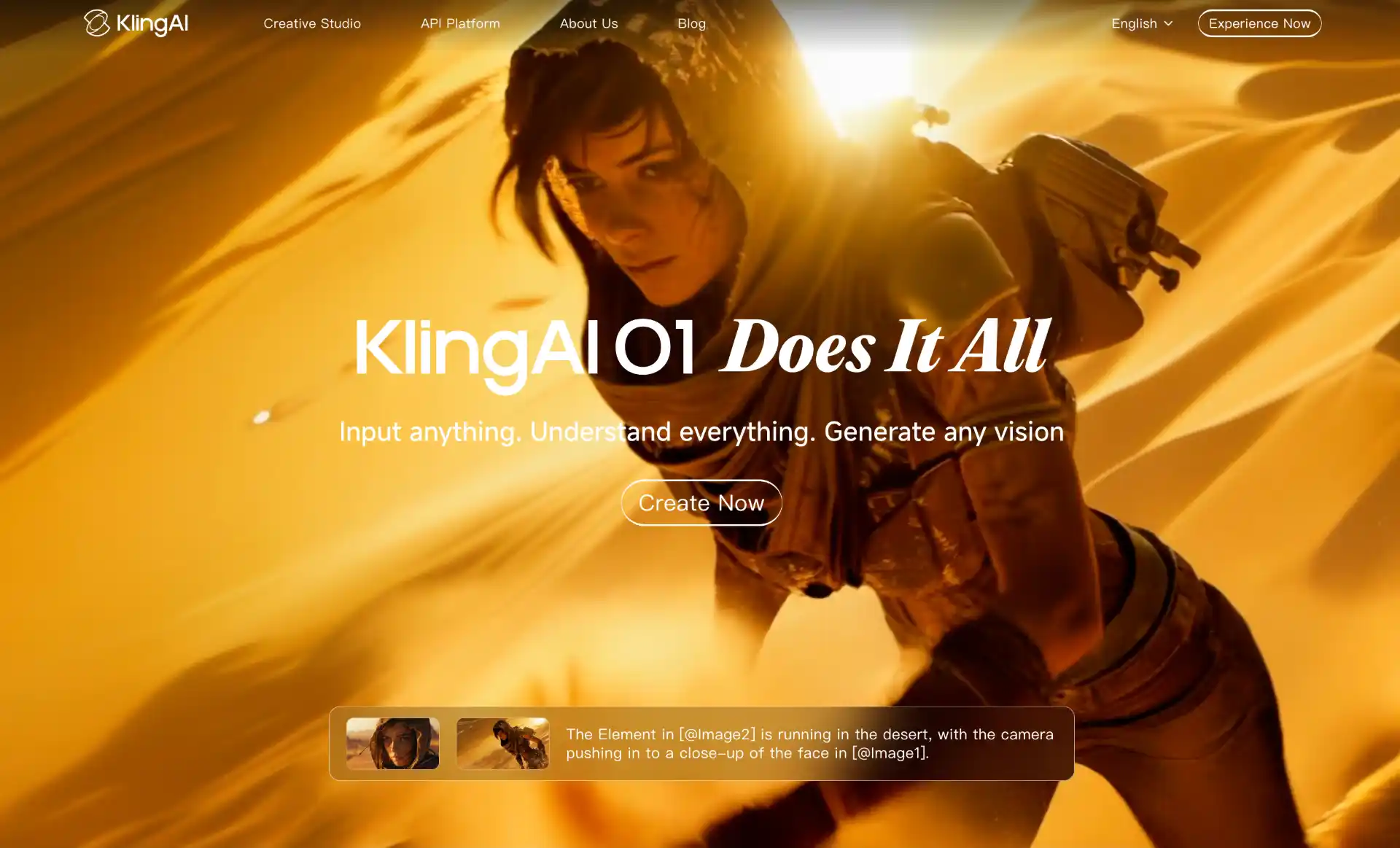
Kling 2.6, released in December 2025 by Chinese tech company Kuaishou, introduces a milestone capability for “simultaneous audio-visual generation” that fundamentally transforms the AI video production workflow. Rather than generating video and audio separately, Kling 2.6 creates visuals, natural voiceovers, sound effects, and ambient atmosphere in a single pass.
The model uses a diffusion-based transformer architecture (DiT) enhanced with Kuaishou’s proprietary 3D variational autoencoder (VAE) network. It can generate videos up to two minutes long at 1080p resolution with 30fps, supporting various aspect ratios. Since its launch, Kling has produced over 10 million videos, establishing itself as one of the most widely adopted models in the short-form video space.
Kuaishou’s pivot to AI has been commercially successful, with shares surging 88% over the past year driven by Kling’s global potential. The model excels at realistic visuals with smooth, natural motion, making it particularly suited for social media content and short-form video production.
Key Features of Kling 2.6:
- Simultaneous audio-visual - Generate video and synchronized audio in one pass
- Up to 2 minutes - Extended video length compared to most competitors
- 1080p at 30fps - High-quality output suitable for professional use
- DiT architecture - Advanced diffusion transformer with 3D VAE
- Text and image-to-video - Multiple input modes for flexibility
- Proven scale - Over 10 million videos generated globally
- Multiple aspect ratios - Support for various platform requirements
Kling 2.6 Pricing:
Kling offers a free tier with limited generations. Paid plans provide additional generation capacity and priority processing. The model is available through Kuaishou’s video editing app KuaiYing and web platform.
5. Luma Ray3

Luma Ray3 represents Luma AI’s latest advancement in photorealistic video generation, building on the success of Ray2 with significantly improved realism, physics, and character consistency. The model features new Hi-Fi Diffusion technology that “masters” the best shots into production-ready high-fidelity 4K HDR footage.
Ray3 packs considerably more detail into the same resolution compared to Ray2, producing crisp high-fidelity outputs with superior instruction following. The model uses large-scale video training to understand natural motion patterns including how dust settles, fabric moves, and objects interact with gravity. This results in motion that feels fluid, intentional, and natural rather than AI-generated.
For creators transitioning from Ray2, the improvements are immediately noticeable. Quality enhancements include lifelike textures, smooth camera work, and realistic lighting with physically accurate interactions between objects and characters. The coherent motion and logical event sequences significantly increase the success rate of usable generations.
Key Features of Luma Ray3:
- Hi-Fi 4K HDR - Production-ready high-fidelity output quality
- Superior physics - Accurate simulation of materials, gravity, and interactions
- Character consistency - Maintained identity and features across scenes
- Natural motion - Fluid, intentional movement trained on large-scale video data
- Instruction following - Improved prompt adherence and creative control
- 1080p standard - High-quality output with 4K mastering available
- Dream Machine integration - Seamless access through Luma’s platform
Luma Ray3 Pricing:
Luma’s Dream Machine offers a free tier with 720p generations. Paid plans start at $7.99/month (Lite) for 1080p, Plus at $20.99/month, Unlimited at $66.49/month, and Enterprise at $1,672.92/year. Ray2 remains available at $0.50 per 5 seconds.
6. Pika 2.5
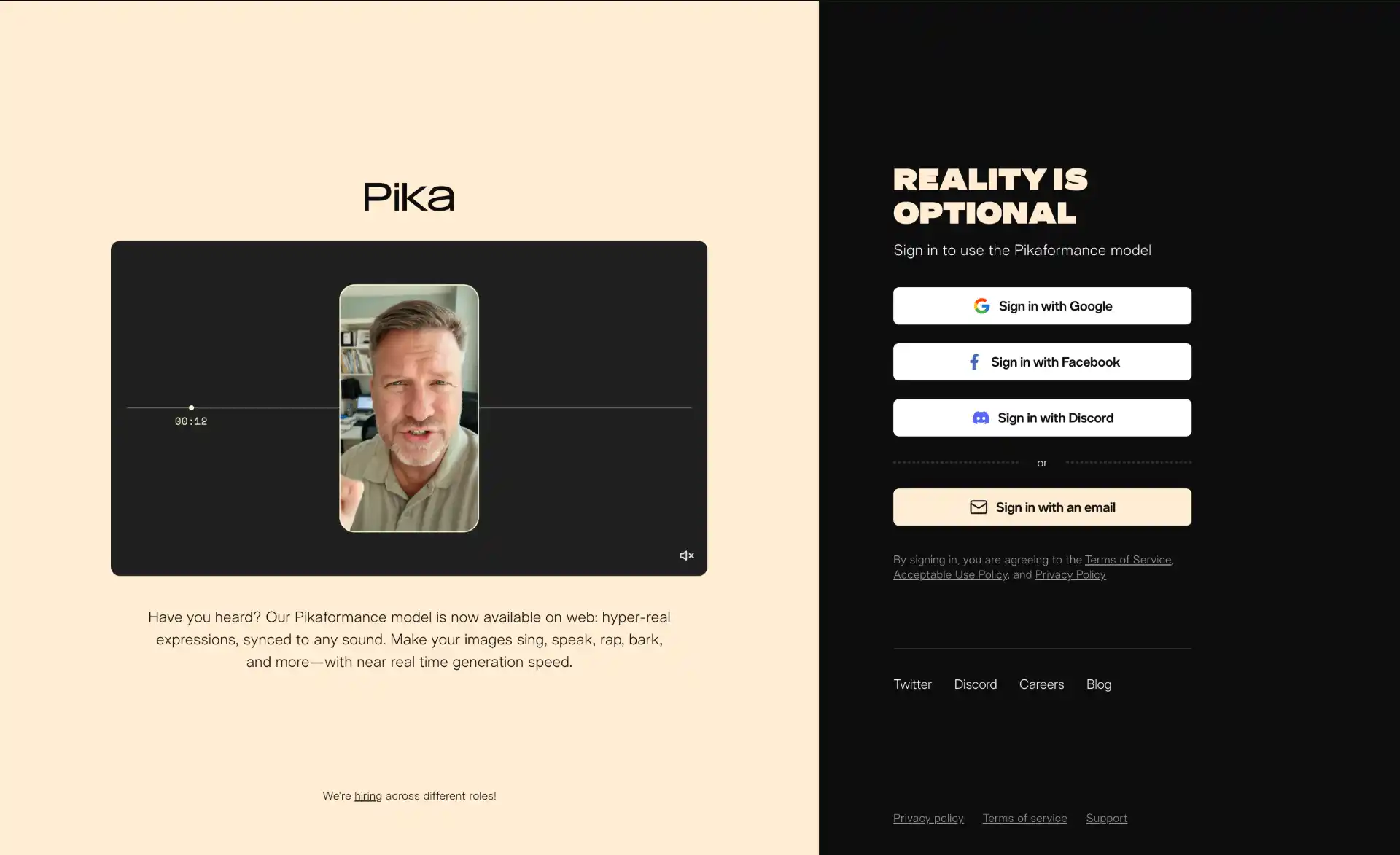
Pika 2.5 has evolved beyond its reputation as a “fun meme generator” into a legitimate creative studio for short-form video production. The update delivers sharper motion, better camera control, stronger character and style consistency, and deeper image integration allowing creators to guide scenes with reference images rather than text alone.
Pika’s strength lies in its specialized tools. Pikaswaps enables creative transformations, Pikaffects adds stylized effects, and Pikaframes introduces keyframe transitions from 1 to 10 seconds for smoother, more cinematic animations. The Pikaformance Model brings still images to life with hyper-real facial expressions perfectly synced to any sound, turning photos or characters into dynamic talking or singing avatars.
With 30% of digital video ads using GenAI in 2024 and projections reaching 39% by 2026, Pika positions itself as an accessible entry point for the growing AI video market. The platform achieved 74% usable results in extensive testing, with an average render time of 42 seconds per video.
Key Features of Pika 2.5:
- Pikaswaps - Creative transformations and style transfers
- Pikaffects - Stylized effects and visual enhancements
- Pikaframes - Keyframe transitions up to 10 seconds
- Pikaformance - Lip-synced avatars from still images
- 1080p support - Upgraded resolution for professional output
- Reference image guidance - Control scenes with visual references
- Fast iteration - 42-second average render time
Pika 2.5 Pricing:
Pika offers a free basic tier. Paid plans start at $8/month, scaling through Pro and higher studio options. Each plan varies generation limits, rendering speed, and commercial-use flexibility.
Best Open-Source AI Video Generation Models
The open-source video generation ecosystem has matured significantly in 2026, offering viable alternatives to proprietary solutions for developers and creators who need local deployment, customization, or cost control.
1. Wan2.2 (Alibaba)
Wan2.2 stands as the leading open-source video generation model in 2026, introducing a Mixture-of-Experts (MoE) architecture into video diffusion models. The A14B model series uses a two-expert design tailored to the denoising process: a high-noise expert for early stages focusing on overall layout, and a low-noise expert for later stages refining video details.
Trained on an enormous dataset of 1.5 billion videos and 10 billion images, Wan2.2 consistently outperforms existing open-source models and competes with state-of-the-art commercial solutions across multiple benchmarks. It achieves a comprehensive VBench score of 84.7%+, excelling at handling complex dynamics, spatial relationships, and multi-object interactions.
The model suite is remarkably accessible. The T2V-1.3B variant requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. On an RTX 4090, it can generate a 5-second 480P video in about 4 minutes without optimization techniques. Wan2.2 is also the first video model capable of generating both Chinese and English text within videos.
Key Features of Wan2.2:
- MoE architecture - Specialized experts for different denoising stages
- 27B total parameters - With only 14B active per step for efficiency
- Consumer GPU support - 8.19GB VRAM minimum for T2V-1.3B model
- Multiple capabilities - Text-to-Video, Image-to-Video, Video Editing, Video-to-Audio
- Bilingual text generation - Chinese and English text rendering in videos
- VBench leading scores - 84.7%+ comprehensive benchmark performance
- Full open source - Code and weights freely available
Wan2.2 Pricing:
Completely free and open-source. Models available on GitHub and Hugging Face. The repository supports two Text-to-Video models (1.3B and 14B) and two resolutions (480P and 720P).
2. LTX-2 (Lightricks)
LTX-2, released by Lightricks in January 2026, is the first production-ready open-source model to combine truly open audio and video generation with native 4K output. With 19 billion parameters (14 billion for video, 5 billion for audio), it delivers synchronized expressive sound alongside high-quality visuals.
The model supports 4K resolution at 50 FPS with up to 20 seconds of video, running efficiently on consumer hardware at up to 50% lower cost than competing models. Complete model weights, training code, and documentation are released under Apache 2.0 license. Importantly, all training data is licensed from Getty Images and Shutterstock, eliminating copyright concerns for commercial applications.
LTX-2 is optimized for NVIDIA’s ecosystem through NVFP8 quantization, reducing model size by ~30% and improving performance by up to 2x. It runs efficiently across GeForce RTX GPUs, NVIDIA DGX Spark, and enterprise data center systems. For companies under $10 million annual recurring revenue, commercial use is free.
Key Features of LTX-2:
- Native 4K at 50fps - Professional-grade resolution and frame rate
- Synchronized audio - Joint audiovisual generation in one model
- 20-second videos - Extended duration compared to most models
- Apache 2.0 license - True open-source with commercial use rights
- Licensed training data - Getty Images and Shutterstock sources
- NVIDIA optimization - NVFP8 quantization for 2x performance
- Consumer hardware - Runs efficiently on RTX GPUs
LTX-2 Pricing:
Free for academic research and commercial use by companies under $10 million ARR. Tiered licensing for larger commercial applications. Available on GitHub and Hugging Face.
3. HunyuanVideo 1.5 (Tencent)

HunyuanVideo 1.5, released by Tencent in November 2025, achieves state-of-the-art visual quality and motion coherence with only 8.3 billion parameters. This efficiency enables practical inference on consumer-grade GPUs, with the 480p I2V step-distilled model generating videos within 75 seconds on an RTX 4090.
The model runs on a Diffusion Transformer fed by a 3D causal VAE that compresses video 16x smaller spatially and 4x smaller temporally. Professional evaluation results show HunyuanVideo outperforming previous state-of-the-art models including Runway Gen-3 and Luma 1.6, achieving 68.5% text alignment and 96.4% visual quality scores.
Tencent has released multiple variants including HunyuanVideo-I2V for image-to-video, HunyuanVideo-Avatar for audio-driven human animation, and HunyuanCustom for multimodal-driven customized video generation. The entire ecosystem is open-source and actively maintained.
Key Features of HunyuanVideo 1.5:
- 8.3B parameters - Efficient model size for consumer deployment
- 75-second generation - Fast inference on RTX 4090
- 13.6GB VRAM - 720p 121-frame videos with offloading
- Superior benchmarks - Outperforms Runway Gen-3 and Luma 1.6
- Multiple variants - T2V, I2V, Avatar, and Custom versions
- 3D causal VAE - Efficient spatiotemporal compression
- Active development - Continuous updates from Tencent
HunyuanVideo 1.5 Pricing:
Completely free and open-source. Available on GitHub and Hugging Face with full model weights and training code.
While the ten models above represent the leading options for AI video generation in 2026, several other tools deserve recognition for their unique capabilities:
 Synthesia - Specializes in AI avatar video generation for corporate communications, training, and marketing. Features over 230 AI avatars with support for 140+ languages, making it ideal for localized content at scale.
Synthesia - Specializes in AI avatar video generation for corporate communications, training, and marketing. Features over 230 AI avatars with support for 140+ languages, making it ideal for localized content at scale.
 Hedra - Focuses on character-driven video generation with particular strength in lip-syncing and emotional expression. Popular for creating talking head videos from audio inputs.
Hedra - Focuses on character-driven video generation with particular strength in lip-syncing and emotional expression. Popular for creating talking head videos from audio inputs.
 D-ID - Pioneers digital human video creation with real-time streaming avatars. Strong API support makes it popular for customer service and interactive applications.
D-ID - Pioneers digital human video creation with real-time streaming avatars. Strong API support makes it popular for customer service and interactive applications.
How to Integrate AI Video Generation into Your Workflow
Successfully incorporating AI video generation into creative and production workflows requires thoughtful integration strategies:
Define Your Output Requirements: Start by understanding exactly what you need. For social media content, Pika 2.5 and Kling offer fast iteration with effects tools. For cinematic quality, Sora 2 and Runway Gen-4.5 deliver the most polished results. For local deployment and privacy, Wan2.2 and LTX-2 provide full control.
Test Multiple Platforms: Most AI video generators offer free tiers or trials. Run the same prompts across several platforms to compare motion quality, prompt adherence, and output consistency. What works brilliantly on one model may produce inconsistent results on another due to different training approaches.
Consider Audio Requirements: If your project needs synchronized sound, prioritize models with native audio generation like Sora 2, Veo 3.1, Kling 2.6, or LTX-2. Adding audio in post-production is possible but adds complexity and may not match as naturally.
Build for Iteration: AI video generation rarely produces perfect results on the first attempt. Build workflows that support rapid iteration, using faster variants like Gen-4 Turbo or smaller open-source models for concepting before committing to higher-quality renders.
Plan for Stitching: Most models still limit generation to 8-25 seconds. For longer content, you’ll need to stitch multiple generations together. Tools like Runway provide storyboard features specifically for this purpose.
Respect Licensing and Attribution: Understand the licensing terms for each platform. Some require attribution, others restrict commercial use, and open-source models have varying requirements. LTX-2’s licensed training data and clear commercial terms make it particularly suitable for business applications.
Conclusion
AI video generation in 2026 offers unprecedented capabilities for creators, developers, and businesses. Proprietary models like Sora 2, Veo 3.1, and Runway Gen-4.5 deliver cinematic quality with sophisticated physics simulation and synchronized audio. Open-source alternatives like Wan2.2, LTX-2, and HunyuanVideo 1.5 provide powerful local generation on consumer hardware with full customization control.
The choice between platforms depends on your specific needs. For maximum quality and ease of use, proprietary solutions offer polished experiences with continuous improvements. For cost control, privacy, and customization, open-source models provide remarkable capabilities without subscription costs. Many professionals find value in combining both approaches, using proprietary models for final production and open-source tools for experimentation.
As the technology continues advancing, expect longer durations, higher resolutions, and even more realistic physics simulation. The gap between AI-generated and traditional video production continues to narrow, opening new creative possibilities for anyone with a compelling vision and well-crafted prompts.