The gap between proprietary and open source AI models for coding is narrowing fast. A year ago, self-hosting an LLM for development meant settling for significantly worse performance than cloud-based alternatives like GPT-4 or Claude. In 2026, the best open source models are closing in on proprietary leaders across benchmarks like
LiveBench, and some even outperform them on specific tasks like code generation and completion.
Whether you’re a solo developer who wants to keep code off third-party servers, a startup looking to cut API costs, or an enterprise with strict data compliance requirements, self-hosted open source LLMs have become a genuinely viable option for professional software development. In this guide, we’ll cover the best open source models you can self-host for coding, the tools to deploy them, and the hardware you need to get started.
Summary
Top Open Source LLMs for Coding (Self-Hostable):
- GLM-5 - 744B MoE, 90% HumanEval, MIT license - Get GLM-5
- Kimi K2.5 - 1T MoE with agent swarm, 99% HumanEval, 85% LiveCodeBench - Get Kimi K2.5
- DeepSeek V3.2 - 671B MoE, 75.69 LiveBench Coding Avg, MIT license - Get DeepSeek V3.2
- Devstral 2 - 123B model, 72.2% SWE-bench Verified (self-reported), 256K context - Get Devstral 2
- Qwen3-Coder - 480B MoE, agentic coding model with CLI tool - Get Qwen3-Coder
- Devstral Small 2 - 24B model, 68% SWE-bench Verified (self-reported), runs on consumer GPU - Get Devstral Small 2
- Qwen 2.5 Coder 32B - Best mid-range coding model, Apache 2.0 - Get Qwen 2.5 Coder
Best Self-Hosting Tools:
- Ollama - Easiest way to get started locally
- vLLM - Best for production serving
- LM Studio - Best GUI for desktop users
Open Source vs Proprietary: How Close Is the Gap?
Before diving into individual models, it’s worth understanding where open source stands relative to the proprietary options you might already be using.
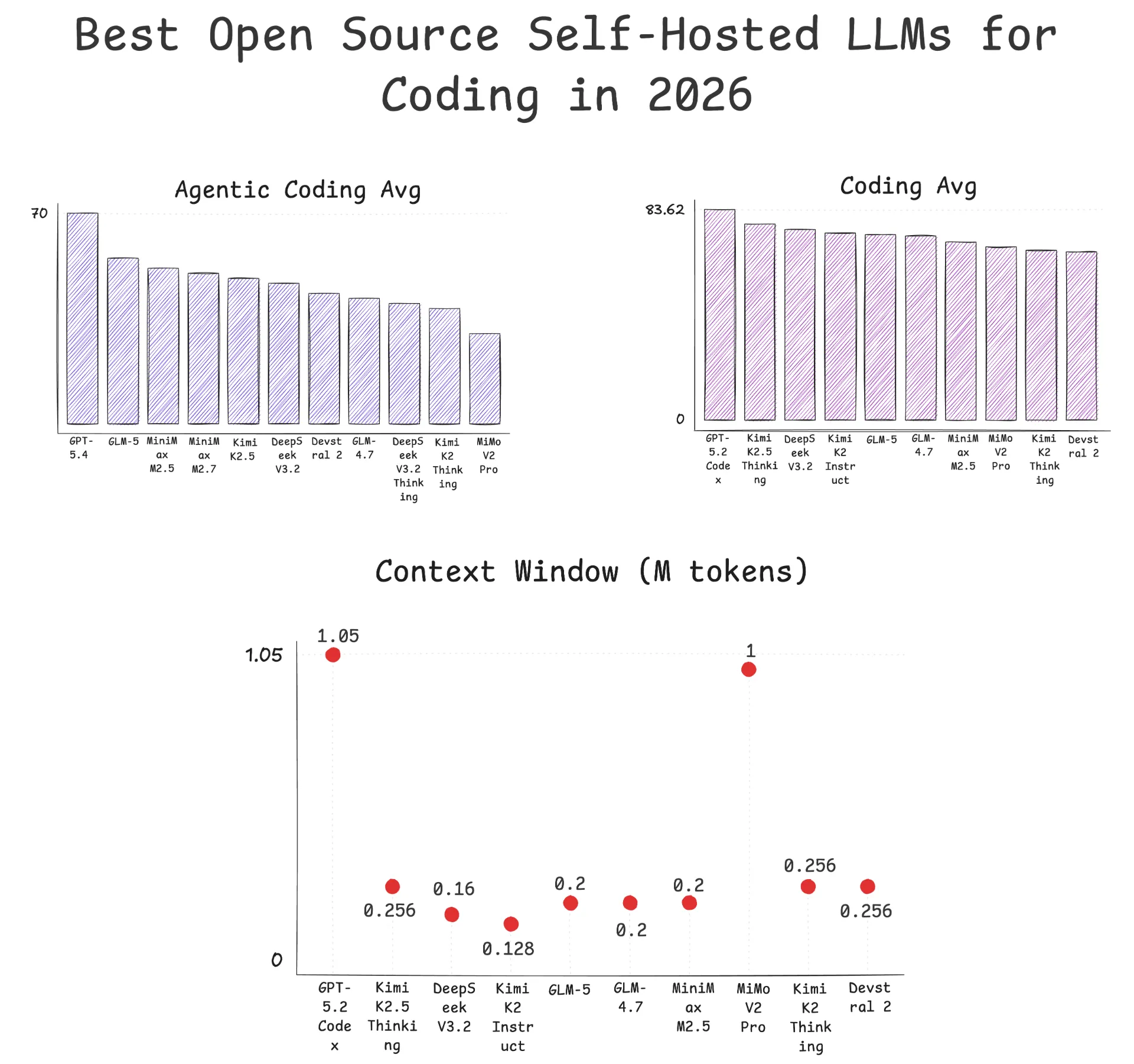
LiveBench is a contamination-free benchmark with 23 diverse tasks spanning Coding, Agentic Coding, Data Analysis, Language, Instruction Following, Math, and Reasoning. Questions refresh regularly and are delay-released to minimize training contamination, making it one of the most reliable benchmarks available. The scores below are sourced from LiveBench (March 2026 snapshot).
LiveBench Agentic Coding Average (March 2026)
| Model | Organization | Type | Agentic Coding Avg | Context Window |
|---|
| GPT-5.4 Thinking xHigh Effort | OpenAI | Proprietary | 70.00 | 1.05M |
| GPT-5.3 Codex xHigh | OpenAI | Proprietary | 66.67 | 400K |
| GLM-5 | Z.AI | Open Source | 55.00 | 200K |
| MiniMax M2.5 | MiniMax | Open Source | 51.67 | 200K |
| MiniMax M2.7 | MiniMax | Open Source | 50.00 | 205K |
| Kimi K2.5 Thinking | Moonshot AI | Open Source | 48.33 | 256K |
| DeepSeek V3.2 | DeepSeek | Open Source | 46.67 | 160K |
| Devstral 2 | Mistral | Open Source | 43.33 | 256K |
| GLM-4.7 | Z.AI | Open Source | 41.67 | 200K |
| DeepSeek V3.2 Thinking | DeepSeek | Open Source | 40.00 | 160K |
| Kimi K2 Thinking | Moonshot AI | Open Source | 38.33 | 256K |
| MiMo V2 Pro | Xiaomi | Open Source | 30.00 | 1M |
LiveBench Coding Average (March 2026)
| Model | Organization | Type | Coding Avg | Context Window |
|---|
| GPT-5.2 Codex | OpenAI | Proprietary | 83.62 | 1.05M |
| GPT-5.1 Codex Max | OpenAI | Proprietary | 81.38 | 1.05M |
| Kimi K2.5 Thinking | Moonshot AI | Open Source | 77.86 | 256K |
| DeepSeek V3.2 | DeepSeek | Open Source | 75.69 | 160K |
| Kimi K2 Instruct | Moonshot AI | Open Source | 74.28 | 128K |
| GLM-5 | Z.AI | Open Source | 73.64 | 200K |
| GLM-4.7 | Z.AI | Open Source | 73.13 | 200K |
| MiniMax M2.5 | MiniMax | Open Source | 70.70 | 200K |
| MiMo V2 Pro | Xiaomi | Open Source | 68.85 | 1M |
| Kimi K2 Thinking | Moonshot AI | Open Source | 67.44 | 256K |
| Devstral 2 | Mistral | Open Source | 66.79 | 256K |
The LiveBench data shows that on agentic coding tasks, GLM-5 leads the open source pack at 55.00, followed by MiniMax M2.5 (51.67) and Kimi K2.5 Thinking (48.33). Proprietary models still hold a lead, with GPT-5.4 Thinking at 70.00. On standard coding tasks, the gap is much smaller. Kimi K2.5 Thinking scores 77.86 compared to GPT-5.1 Codex Max’s 81.38, and several open source models cluster in the 70-78 range alongside proprietary options.
For the latest scores and full model list, visit the
LiveBench leaderboard directly.
Best Open Source LLMs for Coding
1. GLM-5 (Zhipu AI) - #1 Agentic Coding (55.00)

GLM-5 from Zhipu AI ranks #1 among open source models on LiveBench Agentic Coding with a score of 55.00, and scores 73.64 on LiveBench Coding Average. Released in February 2026, it uses a Mixture of Experts architecture with 744 billion total parameters but only 40 billion active per token, spread across 256 experts with 8 active at any given time. It was trained on 28.5 trillion tokens and supports a 200K token context window.
What makes GLM-5 particularly noteworthy is its training infrastructure. The entire model was trained on 100,000 Huawei Ascend 910B chips rather than NVIDIA GPUs, making it a significant milestone for non-NVIDIA AI hardware. Zhipu also introduced a novel reinforcement learning infrastructure called “Slime” that reduced hallucination rates from 90% to 34%.
On coding benchmarks, GLM-5 scores 90% on HumanEval and 77.8% on SWE-bench Verified according to Zhipu AI’s official reports. Its 200K context window is generous enough to handle analysis of large codebases in a single session.
Key Specs
- Architecture: MoE, 744B total / 40B active parameters
- Context Window: 200K tokens
- License: MIT (free commercial use)
- LiveBench Agentic Coding Avg: 55.00 (#1 open source)
- LiveBench Coding Avg: 73.64
- SWE-bench Verified: 77.8% (self-reported by Zhipu AI)
- HumanEval: 90%
- Self-hosting: Supported via vLLM and SGLang; weights available on Hugging Face and ModelScope
2. Kimi K2.5 (Moonshot AI) - #1 Coding (77.86)
Kimi K2.5 from Moonshot AI ranks #1 among open source models on LiveBench Coding Average with a score of 77.86, and scores 48.33 on Agentic Coding. It builds on the already impressive Kimi K2 foundation. The original K2, released in July 2025, was a 1 trillion parameter MoE model with 32B active parameters that scored 65.8% on SWE-bench Verified and pioneered the use of the MuonClip optimizer during training on 15.5 trillion tokens.
K2.5, released in January 2026, takes this further by adding native multimodal capabilities (text, vision, and video) trained on an additional 15 trillion multimodal tokens. Its standout feature is Agent Swarm, a capability that lets the model self-direct up to 100 sub-agents across 1,500 coordinated steps using Parallel-Agent Reinforcement Learning (PARL). This makes K2.5 uniquely powerful for complex agentic coding workflows where the model needs to plan, execute, and verify changes across an entire codebase.
On benchmarks, Moonshot AI reports K2.5 delivers 76.8% on SWE-bench Verified, 99% on HumanEval, and 85% on LiveCodeBench. The 99% HumanEval score is the highest among any open source model, demonstrating exceptional raw code generation ability.
Key Specs
- Architecture: MoE, ~1T total / 32B active parameters
- Context Window: 128K (256K with updates)
- License: Modified MIT (commercial use allowed)
- LiveBench Coding Avg: 77.86 (#1 open source)
- LiveBench Agentic Coding Avg: 48.33
- SWE-bench Verified: 76.8% (self-reported by Moonshot AI)
- HumanEval: 99%
- Self-hosting: Recommended via vLLM or SGLang; production requires 2x H100 80GB or 4x A100 80GB, 512GB RAM
3. DeepSeek V3.2 - Coding 75.69, Agentic 46.67
DeepSeek has consistently pushed the boundaries of what open source models can achieve for coding. The V3.2 release scores 75.69 on LiveBench Coding Average and 46.67 on Agentic Coding, placing it among the top open source contenders. It features 671 billion total parameters with 37 billion active, using a Mixture of Experts architecture and a 160K context window. It’s released under the MIT license.
DeepSeek’s lineage in code-specific models runs deep. The original DeepSeek Coder series (1B to 33B) was trained on 2 trillion tokens composed of 87% code and 13% natural language. DeepSeek Coder V2 expanded to support 338 programming languages. V3.2 combines these strengths into a general model that excels at coding, scoring 73.1% on SWE-bench Verified.
The model’s API pricing is remarkably low at roughly $0.27 to $0.55 per million tokens, making it one of the most cost-effective options even before considering self-hosting. For local deployment, the smaller DeepSeek Coder models (6.7B) run comfortably on consumer hardware through Ollama or LM Studio, while the full V3.2 requires enterprise-grade infrastructure.
Key Specs
- Architecture: MoE, 671B total / 37B active parameters
- Context Window: 160K tokens
- License: MIT
- LiveBench Coding Avg: 75.69
- LiveBench Agentic Coding Avg: 46.67
- SWE-bench Verified: 73.1% (self-reported by DeepSeek)
- Self-hosting: Full model requires multi-GPU setup; smaller Coder variants run on consumer GPUs via Ollama
4. Devstral 2 (Mistral AI) - Coding 66.79, Agentic 43.33
Devstral 2 from Mistral AI is a 123 billion parameter model specifically designed for agentic software engineering. It scores 66.79 on LiveBench Coding Average and 43.33 on Agentic Coding. Released in December 2025, it scores 72.2% on SWE-bench Verified with a 256K context window, making it one of the most capable code-focused models available. Mistral describes it as 7x more cost-efficient than Claude Sonnet and 5x smaller than DeepSeek V3.2 while remaining competitive in benchmarks.
What makes the Devstral family compelling for self-hosting is the smaller sibling, Devstral Small 2 (24B parameters), which scores an impressive 68% on SWE-bench Verified. That’s remarkable for a model that runs on a single RTX 4090 or a Mac with 32GB of RAM. It also supports image inputs and comes with Apache 2.0 licensing, making it one of the most permissive options available.
Mistral also offers Vibe CLI, an open source terminal coding assistant powered by Devstral, giving you a ready-made development workflow out of the box.
Key Specs (Devstral 2)
- Parameters: 123B
- Context Window: 256K tokens
- License: Modified MIT
- LiveBench Coding Avg: 66.79
- LiveBench Agentic Coding Avg: 43.33
- SWE-bench Verified: 72.2% (self-reported by Mistral AI)
- Self-hosting: Multi-GPU recommended for full model
Key Specs (Devstral Small 2)
- Parameters: 24B
- Context Window: 128K tokens
- License: Apache 2.0
- SWE-bench Verified: 68.0% (self-reported by Mistral AI)
- Self-hosting: Single RTX 4090 or Mac with 32GB RAM
The
Qwen3-Coder family from Alibaba represents one of the most comprehensive open source coding model lineups available. The flagship model features 480 billion parameters with a Mixture of Experts design, and Alibaba describes it as “our most agentic code model to date.” There’s also a smaller 30B variant (3B active) for resource-constrained environments.
The more recent Qwen3-Coder-Next (80B total, 3B active) pushes the envelope further with hybrid attention combined with MoE, trained with large-scale reinforcement learning specifically for agentic tasks. It scores 70.6% on SWE-bench Verified, an impressive result for a model with only 3B active parameters.
Alibaba also provides
Qwen Code, an open source terminal coding agent optimized for Qwen3-Coder models. This gives developers a Claude Code or Aider-like experience powered entirely by open source infrastructure.
The broader Qwen ecosystem also includes Qwen 2.5 Coder (available in sizes from 0.5B to 32B), which remains one of the best mid-range options. The 32B Instruct variant scores 73.7 on the Aider benchmark (comparable to GPT-4o) and is readily available through Ollama.
Key Specs
- Architecture: MoE, up to 480B total parameters
- License: Apache 2.0
- SWE-bench Verified: 70.6% (Qwen3-Coder-Next, self-reported by Alibaba)
- Self-hosting: Qwen 2.5 Coder 32B runs on consumer hardware via Ollama; larger variants require multi-GPU
6. Llama 4 (Meta) - Largest Context Window (10M)
Llama 4 from Meta continues to be the most widely deployed open source model family, with over 650 million total downloads and roughly 9% of enterprise production workloads running on Llama variants. The Llama 4 family released in April 2025 includes Scout (109B total, 17B active, 10M context window), Maverick (400B total, 17B active, 1M context), and the announced but unreleased Behemoth (~2T total, 288B active).
While Llama 4 isn’t specifically a coding model, its massive context windows and multimodal capabilities (text and image input across 12 languages) make it highly versatile for development workflows. The code-specific Llama 4 Coder variant brings improved code generation, debugging, and completion accuracy.
The main caveat is licensing: Llama’s license does not meet the OSI Open Source Definition and includes restrictions for companies with very large user bases. For most developers and smaller organizations, this is a non-issue, but it’s worth noting compared to the MIT or Apache 2.0 licenses of other models on this list.
Key Specs
- Architecture: MoE, up to 400B total / 17B active (Maverick)
- Context Window: Up to 10M tokens (Scout)
- License: Llama Community License (restrictions for very large companies)
- Self-hosting: Scout and Maverick available via Ollama, vLLM; smaller variants run on consumer hardware
7. StarCoder 2 (BigCode / Hugging Face) - Most Auditable Training Data
StarCoder 2 is a collaboration between Hugging Face and ServiceNow under the BigCode project. Available in 3B, 7B, and 15B sizes, it was trained on 3.3 to 4.3 trillion tokens from The Stack v2, covering 619 programming languages. It uses Grouped Query Attention with a 16K context window.
StarCoder 2’s standout quality is its data transparency. Every training data source is documented with Software Heritage Identifiers (SWHIDs), making it the most auditable coding model available. This matters for enterprises concerned about IP and licensing compliance. The 15B model matches or outperforms CodeLlama 34B (a model twice its size), demonstrating strong efficiency.
While it doesn’t compete with the larger MoE models on raw benchmarks, StarCoder 2 remains an excellent choice for teams that need a lightweight, well-documented coding model they can run on modest hardware.
Key Specs
- Sizes: 3B, 7B, 15B
- Context Window: 16K tokens
- License: OpenRAIL (fully transparent training data)
- Self-hosting: Runs on consumer hardware via Ollama; 3B variant works on laptops
Honorable Mentions
Several other open source models deserve recognition for specific strengths:
- IBM Granite Code - Available from 350M to 34B parameters under Apache 2.0, trained on 116 programming languages with license-permissible data. Granite 4.0 introduces hybrid Mamba-2/transformer architecture using 70% less memory. Best choice for enterprise compliance.
- NVIDIA Nemotron-Cascade 2 - A 30B MoE with only 3B active parameters that achieves Gold Medal-level performance on competitive programming benchmarks (IMO, IOI, ICPC) with 20x fewer parameters than comparable models. Remarkable efficiency.

- Yi-Coder - From 01.AI, available in 1.5B and 9B sizes with 128K context and Apache 2.0 license. Yi-Coder 9B scores 85.4% on HumanEval, on par with DeepSeek Coder 33B at a fraction of the size.
- Qwen 3.5 - Released February 2026 with a 397B MoE model, featuring unified vision-language capabilities and support for 201 languages. One of the top-ranked open-weight models across multiple benchmarks.
How to Use These Models with a Coding Agent
If you want a Claude Code or Aider-style workflow with self-hosted models, one of the easiest setups is OpenCode +
Ollama. This combination gives you a local coding agent with a simple terminal workflow and no cloud dependency.
Easiest Setup: OpenCode + Ollama
If you’re using Ollama’s built-in Applications flow, the setup is even simpler. The current
Qwen 3.5 Ollama page lists a direct OpenCode launch command.
- Install Ollama
curl -fsSL https://ollama.com/install.sh | sh

- Install Opencode
curl -fsSL https://opencode.ai/install | bash
- Launch OpenCode directly through Ollama Applications
ollama launch opencode --model qwen3.5
- Open your project and start working
Once OpenCode starts, point it at your repository and use it like any other terminal coding agent for explaining code, refactoring files, writing tests, or implementing features.
If you want a smaller local footprint, Ollama also provides smaller Qwen 3.5 tags such as qwen3.5:4b, qwen3.5:9b, and qwen3.5:27b.
Why This Setup Works Well
- Fastest setup path because Ollama can launch OpenCode directly as an application
- Runs fully local with no separate model gateway to configure
- Easy to scale up or down by swapping the Ollama model tag based on your hardware
How to Self-Host These Models Locally
Once you’ve picked a model, you need the right tools and hardware to run it. We’ve covered this extensively in our previous guides:
Quick Decision Guide
| Your Need | Recommended Model | Why |
|---|
| Best overall coding | GLM-5 or Kimi K2.5 | Highest SWE-bench scores among open source |
| Best on consumer hardware | Devstral Small 2 or Qwen 2.5 Coder 32B | Strong performance on single GPU |
| Best tiny model (<10B) | Yi-Coder 9B or StarCoder2-3B | Runs on laptops, punches above weight |
| Best for agentic workflows | Kimi K2.5 or Qwen3-Coder-Next | Built-in agent orchestration |
| Best for enterprise compliance | IBM Granite Code | Apache 2.0, ethics-vetted training data |
| Best efficiency per parameter | NVIDIA Nemotron-Cascade 2 | Gold-medal competitive programming at 3B active params |
Conclusion
The open source LLM landscape for coding has matured dramatically. Models like GLM-5 and Kimi K2.5 are closing in on proprietary leaders, while smaller models like Devstral Small 2 and Qwen 2.5 Coder 32B bring genuinely useful coding assistance to consumer hardware. The tooling ecosystem around Ollama, vLLM, and llama.cpp has made self-hosting accessible to anyone with a decent GPU.
For most developers, the practical recommendation is to start with Ollama and Qwen 2.5 Coder 32B if you have 24GB of VRAM, or Devstral Small 2 if you have less. These will handle the vast majority of code completion, generation, debugging, and refactoring tasks. If you need the absolute best performance and have access to enterprise hardware, GLM-5 or Kimi K2.5 will get you within a few percentage points of the best proprietary models while keeping your code entirely on your own infrastructure.
The 44% of organizations that cite data privacy as their top concern with LLM adoption now have no reason to hold back. Self-hosted open source models are production-ready for coding, and the gap with proprietary alternatives continues to shrink with each new release.