The difference between a flashy demo and a reliable product is usually not the model. It is the harness and infrastructure around it. A 2026 estimate says about 88% of AI agent projects never make it to production, mostly because the harness is too fragile.
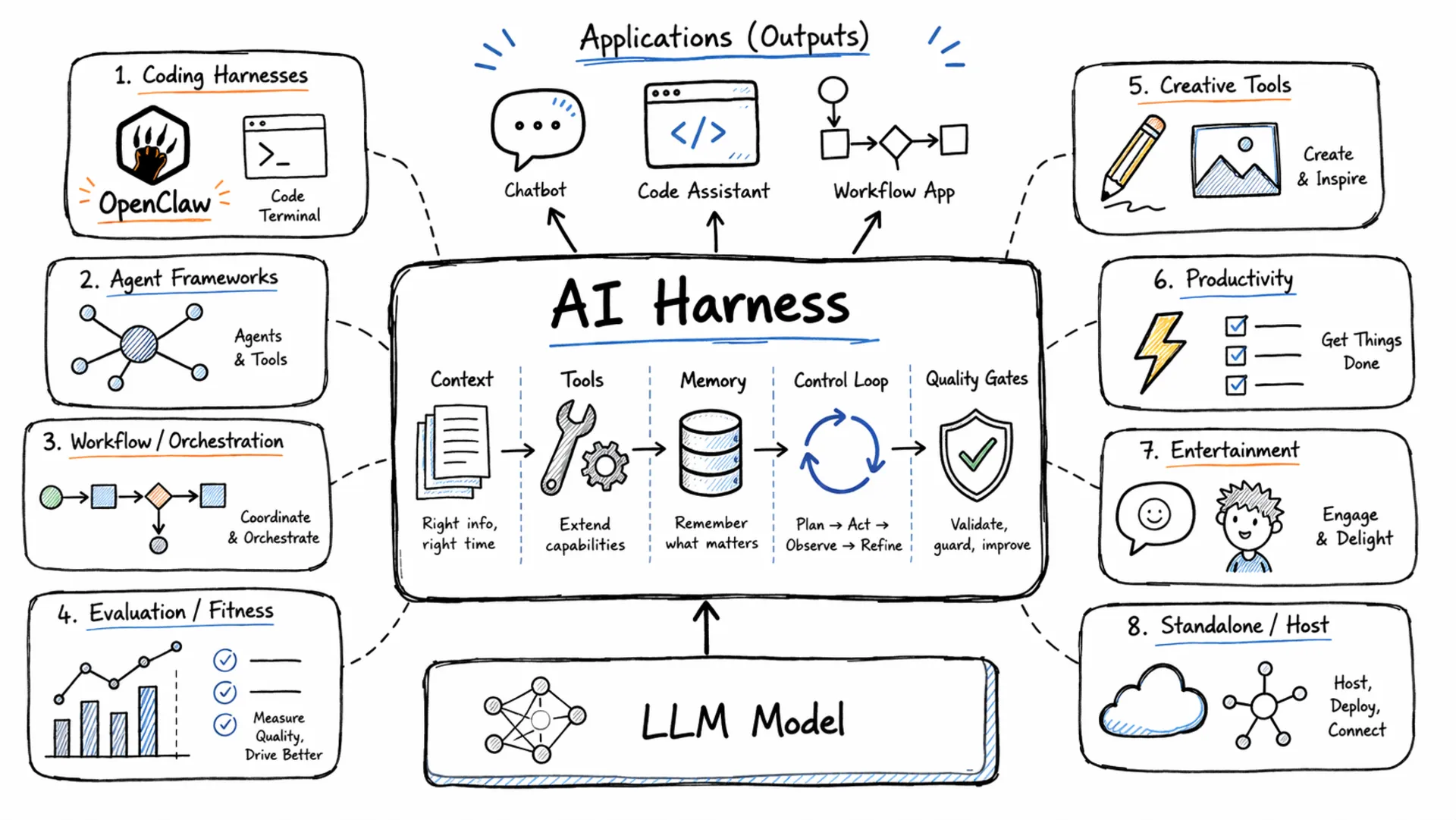
An AI harness is the operating layer around a language model. It determines how context is assembled, which tools are available, how memory persists across turns, how the control loop runs, and which quality gates output must pass before reaching a user. Two teams can run the same model and get very different outcomes because of harness design. Benchmarks reported by several AI engineering teams in 2025 show that improving the harness on the same model can outperform switching to a more capable model.
If you’ve read our piece on why benchmark-only model comparisons miss the point, this article fills in the system layer that benchmarks can’t capture: the infrastructure that decides whether a model is reliable or erratic in real workloads.
Summary
An AI harness is the operating layer around a model handling context, tools, memory, the control loop, and quality gates. There are eight practical categories in this guide:
- Coding harnesses agent loops with repo access and test feedback: Claude Code, OpenAI Codex CLI, OpenClaw, Hermes Agent
- Agent frameworks composable primitives for building LLM apps: LangChain, LlamaIndex, CrewAI, LangGraph
- Workflow/orchestration harnesses process control for business automation: n8n, Prefect
- Standalone/host harnesses unified runtime across model backends: OpenRouter (with practical app-layer harnesses at OpenRouter Apps)
- Evaluation and fitness harnesses quality gates and regression tracking: Promptfoo, DeepEval, LangSmith, Braintrust
- Creative harnesses media and creator workflows: Descript, VidMuse, novelcrafter, CoffeeCat AI Image Generator
- Productivity harnesses assistant and workflow acceleration: OpenClaw, Hermes Agent, Mira, extra.email
- Entertainment harnesses roleplay and interactive chat experiences: Janitor AI, ISEKAI ZERO, SillyTavern, HammerAI
The practical starting stack for most teams: one agent framework (for building) + one coding or workflow harness (for task execution) + one fitness harness (for evaluation and CI gates).
What Is an AI Harness?
The simplest mental model in current production AI engineering is:
Agent = Model + Harness
The model generates tokens. The harness decides what the model sees, what tools it can call, when to retry, what to log, and what constitutes an acceptable result. The model provides intelligence. The harness provides control, reliability, and safety.
This framing matters because frontier model capabilities from multiple providers are now close enough that the choice of model matters less than it did two years ago. What differentiates a reliable production agent from an unpredictable demo is almost always the harness design. Anthropic’s engineering documentation, OpenAI’s Codex writeups, and LangChain’s production reports all make the same observation: harness quality is the primary lever for reliability, safety, and output quality in deployed systems.
What Every Harness Handles
A harness is not a single thing but a collection of concerns. Regardless of type or implementation, most production harnesses cover the same six domains.
Context assembly is the most fundamental. The model cannot act on information it cannot see, and a context window is never large enough to hold everything relevant. The harness decides what to include, what to compress, what to retrieve from external sources, and in what order all before the model processes a single token.
Tool connectors give the model access to the world beyond its training data: file systems, APIs, search indexes, code execution environments, and external services. Without tools, a model can only reason. With tools, it can act and observe results.
Memory and state persistence let an agent accumulate knowledge beyond the current context window. This includes in-context working memory, external databases and vector stores, and procedural memory of learned patterns and user preferences.
The control loop is what makes an agent different from a one-shot completion. The harness runs the model, observes the result, checks whether a goal condition is met or a tool call is needed, and either acts or terminates. Simple harnesses run sequential loops; more sophisticated ones support branching, parallelism, and multi-agent handoffs.
Guardrails and policy enforcement wrap the loop with safety constraints input filters, output validators, permission boundaries on tool use, and rate controls. These are the harness components that determine whether an agent can be trusted in production without continuous human supervision.
Telemetry and evaluation close the loop between deployment and improvement. Traces, latency metrics, pass rates, and LLM-as-judge evaluations let teams measure whether the harness is producing correct outputs and catch regressions before users do.
The Eight Harness Categories at a Glance
| Category | Main Purpose | Representative Tools |
|---|---|---|
| Coding | Build and modify software with agent loops | Claude Code, Codex CLI, OpenClaw, Hermes Agent |
| Agent Frameworks | Composable primitives for building LLM applications | LangChain, LlamaIndex, CrewAI, LangGraph, Smolagents |
| Workflow/Orchestration | Automate business and application workflows | n8n, Prefect, Airflow |
| Standalone/Host | Unified runtime across multiple model backends | OpenRouter |
| Evaluation/Fitness | Quality gates, regression tracking, CI integration | Promptfoo, DeepEval, LangSmith, Braintrust |
| Creative | Creative generation and media production workflows | Descript, VidMuse, novelcrafter, CoffeeCat AI Image Generator |
| Productivity | Task execution and daily assistant workflows | OpenClaw, Hermes Agent, Mira, extra.email |
| Entertainment | Roleplay and interactive conversational experiences | Janitor AI, ISEKAI ZERO, SillyTavern, HammerAI |
Coding Harnesses: Claude Code, OpenAI Codex CLI, OpenClaw, and Hermes Agent
Coding harnesses are what most developers encounter first, and their architecture is consistent across implementations regardless of the underlying model. The harness reads the repository, understands the task, applies file edits, runs checks such as tests, linters, or type checkers, reads the output, and loops until constraints pass or a stop condition is hit.
 Claude Code runs in the terminal and integrates with IDEs, CI/CD pipelines, and Anthropic’s desktop app. It uses a context-gathering phase followed by a tool-use loop where the model issues structured calls for file reads, writes, shell execution, and search. The harness enforces permission boundaries so the agent cannot take actions the operator has not authorized a design that makes it deployable in CI environments without manual oversight on each step.
Claude Code runs in the terminal and integrates with IDEs, CI/CD pipelines, and Anthropic’s desktop app. It uses a context-gathering phase followed by a tool-use loop where the model issues structured calls for file reads, writes, shell execution, and search. The harness enforces permission boundaries so the agent cannot take actions the operator has not authorized a design that makes it deployable in CI environments without manual oversight on each step.
OpenAI Codex CLI follows the same architecture with models trained specifically for long-running agentic tasks. OpenAI documented a case study in 2026 where a three-engineer team generated roughly one million lines of code over five months approximately 3.5 pull requests per engineer per day using the Codex agent loop. The numbers are not about the model generating perfect code; they are about the harness making the iteration loop fast enough that engineers could review and merge at that pace.

OpenClaw and Hermes Agent follow the same core pattern: scoped tool access, iterative edit-and-run loops, and guardrails around execution. They are practical coding harness options when you want fast iteration with controlled actions.
Across these coding harnesses, the value is not the model alone. It is the harness that provides repository context, the control loop that retries on test failure, and the safety layer that gates which system commands can run. A coding harness without good test feedback is a fast way to produce untested code. With deterministic checks in the loop, the agent can self-correct before any human reviews the output. See best AI tools for coding and self-hosted coding LLMs for the model layer that sits inside these harnesses.
Agent Frameworks: Building Blocks for LLM Applications
Agent frameworks provide composable primitives prompt templates, tool definitions, memory abstractions, and orchestration logic so teams do not need to build the harness layer from scratch. These are the most directly practical harness category for developers building new LLM-powered applications.
 LangChain is the most adopted framework in this space, with over 100,000 GitHub stars and 34 million monthly downloads. Its strength is breadth: hundreds of integrations, extensive documentation, and a large community that has solved most common edge cases. LangChain makes sense as the default starting point when you need to move fast and expect to connect many different services. Its companion project,
LangGraph, reached v1.0 in October 2025 and provides graph-based stateful orchestration for more complex agent workflows. LangGraph is already deployed in production at Klarna, Replit, and Elastic, and it has over 400 companies that ran it during its beta period.
LangChain is the most adopted framework in this space, with over 100,000 GitHub stars and 34 million monthly downloads. Its strength is breadth: hundreds of integrations, extensive documentation, and a large community that has solved most common edge cases. LangChain makes sense as the default starting point when you need to move fast and expect to connect many different services. Its companion project,
LangGraph, reached v1.0 in October 2025 and provides graph-based stateful orchestration for more complex agent workflows. LangGraph is already deployed in production at Klarna, Replit, and Elastic, and it has over 400 companies that ran it during its beta period.
 LlamaIndex specializes in retrieval-augmented generation. If the primary challenge is connecting a model to documents, databases, or structured knowledge bases and doing it with high retrieval quality LlamaIndex is the more focused choice. It handles semantic indexing, context organization, and persistent memory better than general-purpose frameworks and is worth preferring over LangChain when RAG quality is the core product requirement.
LlamaIndex specializes in retrieval-augmented generation. If the primary challenge is connecting a model to documents, databases, or structured knowledge bases and doing it with high retrieval quality LlamaIndex is the more focused choice. It handles semantic indexing, context organization, and persistent memory better than general-purpose frameworks and is worth preferring over LangChain when RAG quality is the core product requirement.
 CrewAI takes a role-based approach to multi-agent systems. Each agent in a “crew” has a defined role, backstory, and set of tools, which produces pipelines that are readable and easy for non-engineers to reason about. CrewAI raised $18 million in 2025 and reports powering agents used by sixty percent of Fortune 500 companies. It is well-suited for teams that want composable multi-agent pipelines without building the orchestration layer themselves.
CrewAI takes a role-based approach to multi-agent systems. Each agent in a “crew” has a defined role, backstory, and set of tools, which produces pipelines that are readable and easy for non-engineers to reason about. CrewAI raised $18 million in 2025 and reports powering agents used by sixty percent of Fortune 500 companies. It is well-suited for teams that want composable multi-agent pipelines without building the orchestration layer themselves.
Workflow and Automation Harnesses
Workflow harnesses prioritize process control over agent reasoning. The model is one node in a larger graph of steps, branching conditions, retries, and external service calls rather than the central decision-maker in a free-running loop.
 n8n is the most developer-oriented option in this category. With over 1,100 connectors, built-in LangChain nodes, MCP support, AI agent builder capabilities, and human-in-the-loop approval steps, it has evolved from a generic automation tool into a first-class AI workflow platform. Around 75% of n8n’s customers are now using its AI features, and the self-hosted version keeps data within your own infrastructure.
n8n is the most developer-oriented option in this category. With over 1,100 connectors, built-in LangChain nodes, MCP support, AI agent builder capabilities, and human-in-the-loop approval steps, it has evolved from a generic automation tool into a first-class AI workflow platform. Around 75% of n8n’s customers are now using its AI features, and the self-hosted version keeps data within your own infrastructure.
 Prefect and Apache Airflow serve data engineering teams that need Python-native workflow definitions with production-grade scheduling, retry logic, and observability. These are better choices when your workflow is fundamentally a data pipeline that happens to call an LLM, rather than a workflow that is primarily about LLM orchestration.
Prefect and Apache Airflow serve data engineering teams that need Python-native workflow definitions with production-grade scheduling, retry logic, and observability. These are better choices when your workflow is fundamentally a data pipeline that happens to call an LLM, rather than a workflow that is primarily about LLM orchestration.
The practical distinction between workflow harnesses and agent frameworks: if the process logic is the core product, use n8n or Prefect. If the agent’s reasoning is the core product and you need graph-based state management around it, LangGraph sits at the boundary between the two categories and may serve both needs.
Standalone and Host Harnesses
Standalone and host harnesses give you a stable control plane across many model providers so your application can route, fail over, and enforce policy without rewriting your app for each provider.
 OpenRouter is a strong example in this category because it provides one runtime layer above multiple models, so teams can standardize integration logic while still switching providers as quality, cost, or latency changes.
OpenRouter is a strong example in this category because it provides one runtime layer above multiple models, so teams can standardize integration logic while still switching providers as quality, cost, or latency changes.
OpenRouter Apps is the practical app-layer extension of that host model. As of May 5, 2026, top coding harnesses include OpenClaw and Hermes Agent.
Evaluation and Fitness Harnesses
Evaluation harnesses are not the runtime. They are the quality layer around it tools that measure whether your agent produces correct outputs, catch regressions between releases, and gate deployments in CI. Adding evaluation infrastructure early is the highest-leverage change most teams can make after getting a working agent loop.
 Promptfoo is a CLI-first eval framework with a YAML configuration model. It supports prompt matrices, LLM-as-judge evaluators, red-team security checks, and CI integration. Both Anthropic and OpenAI use it internally, which provides reasonable signal for teams building on those APIs.
Promptfoo is a CLI-first eval framework with a YAML configuration model. It supports prompt matrices, LLM-as-judge evaluators, red-team security checks, and CI integration. Both Anthropic and OpenAI use it internally, which provides reasonable signal for teams building on those APIs.
 DeepEval from Confident AI takes a pytest-style approach: you write LLM tests using standard Python test patterns and run them in your existing test suite. It is the most natural fit for teams that already run pytest and want LLM quality checks to look and behave like regular unit tests.
DeepEval from Confident AI takes a pytest-style approach: you write LLM tests using standard Python test patterns and run them in your existing test suite. It is the most natural fit for teams that already run pytest and want LLM quality checks to look and behave like regular unit tests.
LangSmith is LangChain’s managed evaluation and tracing platform. If you are already in the LangChain ecosystem, it provides the most integrated experience for capturing traces, running offline evaluations, and building datasets from production traffic.
 Braintrust covers the full evaluation lifecycle: pre-deployment testing, production monitoring, team collaboration on evaluation datasets, and automated release enforcement. It is the strongest independent option for teams that are not LangChain-native but want a mature eval platform with CI integration built in.
Braintrust covers the full evaluation lifecycle: pre-deployment testing, production monitoring, team collaboration on evaluation datasets, and automated release enforcement. It is the strongest independent option for teams that are not LangChain-native but want a mature eval platform with CI integration built in.
Other Harnesses: Creative, Productivity, and Entertainment
Some harnesses are domain-specific and optimized for creator workflows, assistant-style productivity, or interactive chat experiences.
 For creative workflows, top harnesses include
Descript,
VidMuse,
novelcrafter, and
CoffeeCat AI Image Generator.
For creative workflows, top harnesses include
Descript,
VidMuse,
novelcrafter, and
CoffeeCat AI Image Generator.
 For productivity workflows, top harnesses include
OpenClaw,
Hermes Agent,
Mira, and
extra.email.
For productivity workflows, top harnesses include
OpenClaw,
Hermes Agent,
Mira, and
extra.email.
 For entertainment workflows, top harnesses include
Janitor AI,
ISEKAI ZERO,
SillyTavern, and
HammerAI.
For entertainment workflows, top harnesses include
Janitor AI,
ISEKAI ZERO,
SillyTavern, and
HammerAI.
Runnable Harness Example
The snippet below is dependency-free and runs with Python 3.7 or later. It demonstrates the core harness loop: feed a dataset, call the model, score pass rate and latency, and block on a regression gate.
from dataclasses import dataclass
from time import perf_counter
from typing import Callable, Dict, List
@dataclass
class EvalCase:
# Each case represents one user-like request and a minimum expected signal.
name: str
prompt: str
must_include: str
class LLMHarness:
def __init__(self, llm: Callable[[str], str]) -> None:
# llm is any callable so this harness can wrap mocks, SDK clients, or gateways.
self.llm = llm
def run(self, cases: List[EvalCase]) -> Dict[str, float]:
if not cases:
raise ValueError("cases must not be empty")
passed = 0
latencies_ms: List[float] = []
for case in cases:
# Measure end-to-end latency for each case.
start = perf_counter()
output = self.llm(case.prompt)
latencies_ms.append((perf_counter() - start) * 1000)
# Basic quality check: expected token/phrase appears in model output.
if case.must_include.lower() in output.lower():
passed += 1
# Pass rate is the simplest regression signal to gate releases.
pass_rate = passed / len(cases)
sorted_lat = sorted(latencies_ms)
# Approximate p95 to capture tail latency instead of only averages.
p95_index = max(0, int(len(sorted_lat) * 0.95) - 1)
p95_ms = sorted_lat[p95_index]
return {"pass_rate": pass_rate, "p95_ms": p95_ms}
def fake_llm(prompt: str) -> str:
# Deterministic local stub used for harness logic testing.
db = {
"capital of france": "The capital of France is Paris.",
"2 + 2": "2 + 2 equals 4.",
"hello": "Hello!"
}
return db.get(prompt.strip().lower(), "I do not know.")
if __name__ == "__main__":
# Small seed dataset; replace with real, versioned production-like prompts.
cases = [
EvalCase("geo", "capital of france", "Paris"),
EvalCase("math", "2 + 2", "4"),
EvalCase("greeting", "hello", "hello")
]
# Swap fake_llm with your provider call wrapper when integrating for real.
harness = LLMHarness(fake_llm)
metrics = harness.run(cases)
print(f"pass_rate={metrics['pass_rate']:.2f}")
print(f"p95_ms={metrics['p95_ms']:.3f}")
# CI-style release gate: fail the run if quality drops below target.
assert metrics["pass_rate"] >= 0.95, "Regression gate failed"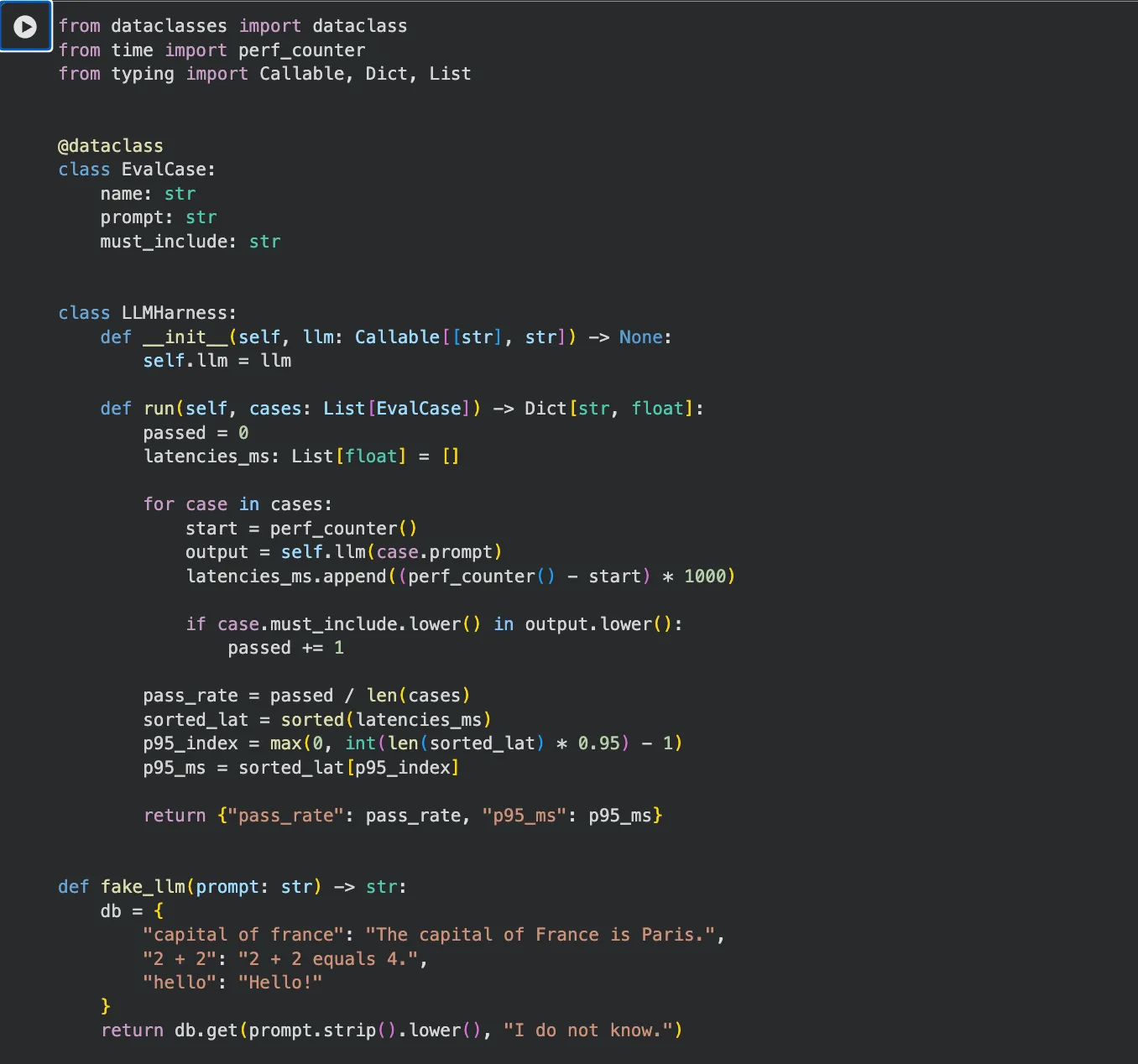
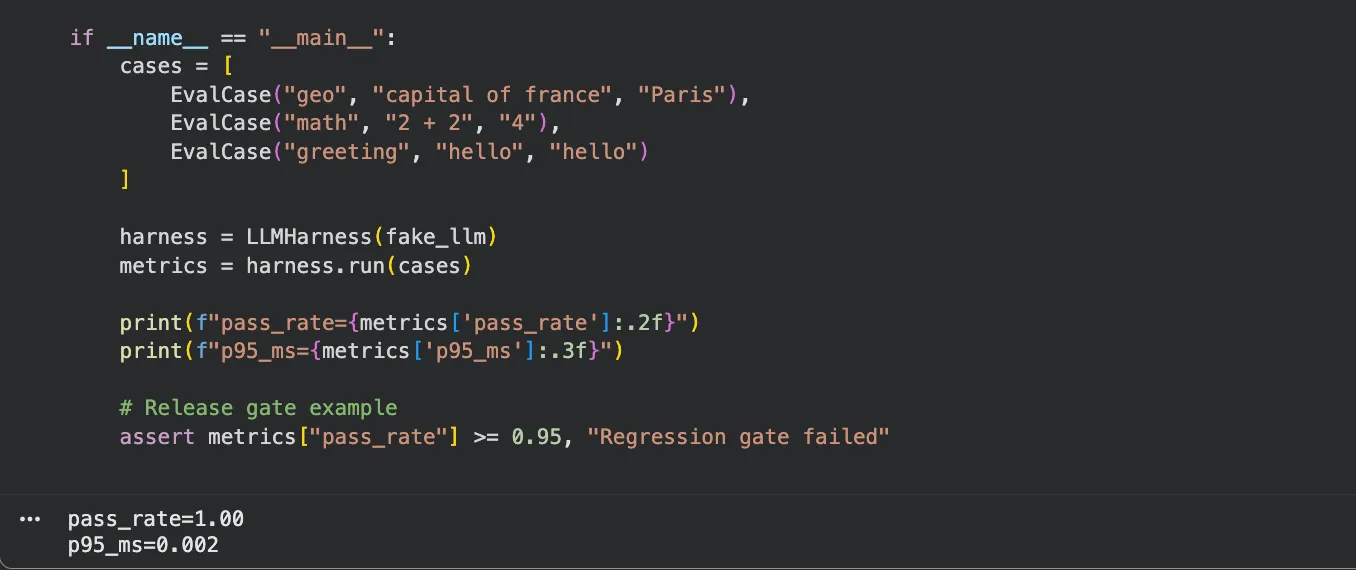
Save the file and run python harness.py. You will get pass_rate=1.00 and a sub-millisecond p95 since the stub LLM is synchronous. Swap fake_llm for any real API call and wire the assert into your CI pipeline to block deployments when quality drops.
In a coding harness, this same pattern is extended with repository operations and shell execution. The evaluation cases become test suite results, and the gate condition becomes a minimum test pass rate rather than a keyword match. For broader setup context, see best AI tools for coding and self-hosted coding LLMs.
How to Choose the Right Harness
The decision is simpler than the number of tools suggests. Start by identifying the primary task, then layer quality measurement on top regardless of what you choose for the task layer.
If you are building software features and shipping code, start with a coding harness. Claude Code and Codex CLI both work today without significant setup and produce visible results quickly. Connect them to your existing test suite and the harness loop closes automatically the agent runs tests, reads failures, and retries.
If you are building an LLM-powered application a chatbot, a retrieval system, a multi-step agent, a customer service workflow pick an agent framework first. LangChain is the safe default due to ecosystem size and documentation coverage. LlamaIndex is the better choice if RAG quality is central to your product. CrewAI is worth evaluating if your application has naturally distinct agent roles that benefit from explicit role definitions. Smolagents reduces friction if you want something lightweight and fast to set up.
If you are automating business processes ticket routing, CRM updates, approval pipelines, ETL tasks a workflow harness is the right tool. Use n8n for visual-first teams that need many service integrations; use Prefect or Airflow for Python-native data engineering teams.
In all cases, add an evaluation harness before you scale. Promptfoo integrates with almost any stack in a day. DeepEval adds minimal overhead for teams already using pytest. The cost of skipping evaluation at early scale is high: you will not know when your harness regresses, and you will find out from users rather than from your CI pipeline.
Conclusion
AI harnesses are not a single category of tool. They are a design choice that spans five different concerns: how the model acts on tasks, how you build LLM applications around it, how you automate business processes, how you route between model backends, and how you measure output quality over time. The models themselves are increasingly capable and increasingly interchangeable. What separates teams that ship reliable AI products from teams still debugging demos is almost always the infrastructure layer that connects model outputs to real-world feedback.
Pick harnesses based on your current problem, not a hypothetical future architecture. One agent framework plus one evaluation harness is enough to start building something shippable. Add routing, workflow orchestration, and domain-specific layers when your application actually demands them not before.