What is 'Mixture of Experts' in LLM Models?
Updated on Oct 14, 2025 · 13 mins read

Mixture of Experts (MoE) has become one of the most important architectural innovations in modern large language models, enabling massive scale while keeping computational costs manageable. If you’ve wondered how cutting-edge 2025 models like OpenAI's GPT-5 and GPT-OSS-120B, Moonshot's trillion-parameter Kimi K2, or DeepSeek's V3.1 can have hundreds of billions or even trillions of parameters while still being practical to run, MoE is the secret sauce behind their efficiency.
Understanding MoE architecture is crucial for developers working with AI models, whether you’re choosing between different model architectures, optimizing inference costs, or building applications that need to scale efficiently. This guide breaks down exactly how Mixture of Experts works, why it matters, and which models are using it to push the boundaries of what’s possible in AI.
Summary
What is Mixture of Experts (MoE)?
- Architecture: Uses multiple specialized “expert” networks instead of one monolithic model
- Sparse Activation: Only activates a subset of experts for each input, not the entire model
- Routing: A gating network decides which experts to use for each token/input
- Efficiency: Achieves larger model capacity with similar computational cost to smaller dense models
Key Benefits:
- Scalability - Can scale to trillions of parameters efficiently
- Cost Efficiency - Lower inference costs compared to equivalent dense models
- Specialization - Different experts can specialize in different domains/tasks
- Performance - Often outperforms dense models of similar computational cost
State-of-the-Art 2025 MoE Models:
- GPT-5 - OpenAI’s flagship with specialized expert routing and multimodal capabilities
- GPT-OSS-120B - OpenAI’s first open-source MoE (117B total, 5.1B active)
- Qwen3-235B-A22B - Alibaba’s flagship with hybrid reasoning (235B total, 22B active)
- Kimi K2 - Moonshot AI’s trillion-parameter model (1T total, 32B active)
- DeepSeek R1 - Reasoning-optimized MoE (671B total, 37B active)
- DeepSeek V3.1 - Hybrid thinking mode MoE (671B total, 37B active)
- OLMoE-1B-7B - Efficiency-focused model (7B total, 1B active)
When to Use MoE:
- Need large model capacity with controlled costs
- Building domain-specific applications that benefit from specialization
- Scaling inference across multiple tasks efficiently
- Working with limited computational budgets
Understanding the Core Concept
The Problem with Dense Models
Traditional neural networks, including most early language models, are “dense” - meaning every parameter is activated for every input. When you send a prompt to a dense model like GPT-3, all 175 billion parameters spring into action to process your request. This works fine for smaller models, but as we scale to hundreds of billions or trillions of parameters, the computational requirements become astronomical.
Think of it like having a massive factory where every single worker has to participate in making every product, regardless of whether their specific skills are needed. It’s incredibly wasteful and expensive, especially when you only need a fraction of those specialized skills for any given task.
The MoE Solution
Mixture of Experts flips this approach on its head. Instead of one massive monolithic model, MoE creates multiple smaller “expert” networks, each specializing in different aspects of the task. For any given input, only a subset of these experts are activated - typically just 2-4 experts out of dozens or hundreds available.
This is like having a smart factory manager who looks at each incoming order and only assigns the workers whose specific skills are needed for that particular product. The result? You can have a much larger total workforce (more parameters) while only paying for the workers you actually use (active parameters).
How MoE Architecture Works
The Three Key Components
1. Expert Networks Each expert is essentially a smaller neural network, often just a few feed-forward layers. These experts can specialize in different domains - one might become really good at handling code, another at creative writing, another at mathematical reasoning. The specialization happens naturally during training as different experts learn to handle different types of inputs.
2. Gating Network (Router) This is the “brain” that decides which experts to activate for each input token. The gating network looks at the input and produces a probability distribution over all available experts. It then selects the top-k experts (usually k=1 or k=2) to actually process the input. This routing decision happens for every single token in your input.
3. Sparse Activation Only the selected experts are activated and contribute to the final output. The rest remain dormant, saving massive amounts of computation. This sparse activation is what makes MoE so efficient - you get the capacity of a huge model with the computational cost of a much smaller one.
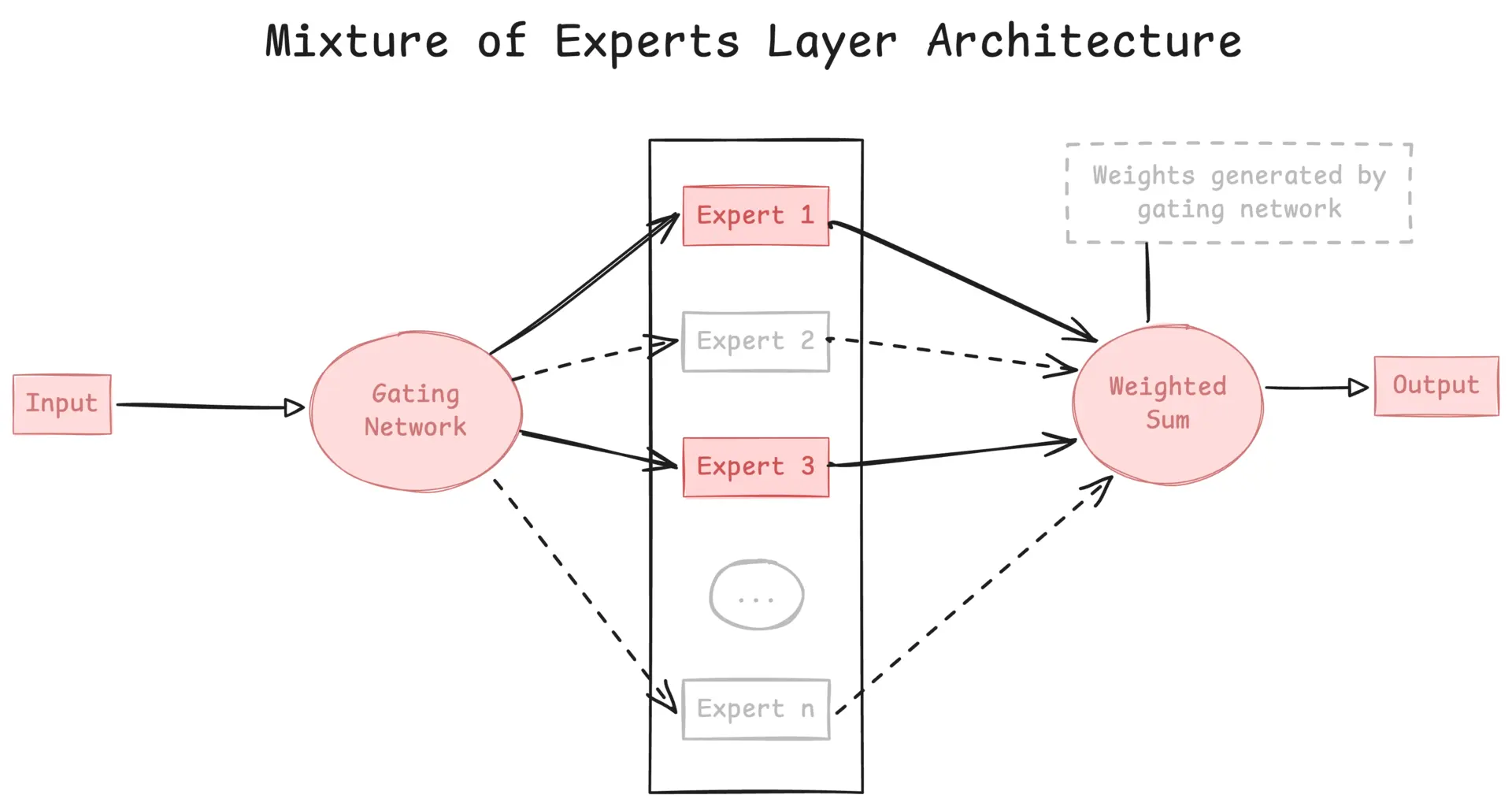
This diagram illustrates MoE’s core efficiency principle: input flows through a gating network that selectively activates only specific experts while keeping others dormant. The activated experts process the input in parallel, and their outputs are combined using weights determined by the gating network. This sparse activation pattern allows models like Kimi K2 to have trillion-parameter capacity while only using 32B parameters per inference.
The Training Process
Training MoE models is trickier than dense models because you need to ensure all experts get used and specialized properly. The gating network needs to learn good routing decisions while avoiding the problem where all inputs get routed to just a few “favorite” experts, leaving others unused.
Modern MoE implementations use techniques like load balancing losses and expert capacity limits to ensure training stability and proper expert utilization. The goal is to have each expert develop its own specialty while maintaining overall model performance.
State-of-the-Art 2025 MoE Models
The year 2025 has been revolutionary for MoE architectures, with several groundbreaking models pushing the boundaries of what’s possible with sparse activation. These models demonstrate that MoE has evolved from an experimental technique to the dominant architecture for state-of-the-art language models.
OpenAI GPT-5 (2025)
GPT-5 represents OpenAI’s most significant architectural shift, moving from dense transformer models to a sophisticated Mixture of Experts design. Rather than relying on a single monolithic neural network, GPT-5 employs multiple specialized “expert” sub-models, each trained to master specific types of tasks like coding, conversation, mathematics, or multimodal analysis.
The genius of GPT-5’s MoE architecture lies in its selective activation: only the most relevant experts activate based on your query. Ask it to debug code, and the “code expert” engages; request image interpretation, and the visual reasoning expert takes charge. This approach delivers incredible efficiency - instead of activating the entire model, GPT-5 uses just what’s needed for each specific task.
Key innovations include expert specialization (different experts for different domains), dynamic routing (intelligent selection of which experts to activate), and multimodal integration (seamless handling of text, images, and other data types). This makes GPT-5 not just larger, but fundamentally smarter in how it allocates computational resources.
OpenAI GPT-OSS Series (2025)
In a surprising move, OpenAI released their first fully open-source models in August 2025 with the GPT-OSS series. GPT-OSS-120B features 117 billion total parameters with only 5.1 billion active per token, using approximately 23 experts with top-k routing. This represents only 4-5% of the model’s weights being used for any given token, drastically reducing compute compared to a dense 120B model.
The model introduces a revolutionary “dual mode” capability - users can toggle between a “thinking” mode for complex reasoning and a fast response mode for straightforward queries. This allows the model to balance latency versus accuracy on demand. Despite its sparse activation, GPT-OSS-120B achieves approximately 90% on MMLU (Massive Multitask Language Understanding), nearly matching OpenAI’s proprietary GPT-4 models.
GPT-OSS-20B, the smaller variant with 21 billion total parameters and 3.6 billion active, can run on a single 16GB GPU while delivering mid-80s MMLU performance. Both models support 128K context windows and are released under the Apache 2.0 license, making them fully open-source for commercial use.
Alibaba Qwen3-235B-A22B (2025)
Qwen3-235B-A22B represents Alibaba’s flagship MoE model, unveiled in April 2025. With 235 billion total parameters and 22 billion active per token, it uses 128 experts with top-8 routing across 94 transformer layers. The model was trained on an unprecedented 36 trillion tokens and supports 119+ languages.
The standout feature is its “hybrid reasoning” capability - Qwen3 can switch between thinking mode (with internal multi-step reasoning and self-consistency checks) and non-thinking mode for quick responses. This gives users control over the computational “budget” per query. The model achieves 87-88% on MMLU and demonstrates strong coding ability with ~70% pass@1 on code challenges, often outperforming OpenAI’s models on math competitions like AIME.
Moonshot AI Kimi K2 (2025)
Kimi K2 pushes MoE to unprecedented scale with 1 trillion total parameters and 32 billion active per token. Using 384 experts with top-8 routing, it represents one of the largest open-source models ever created. Each expert sub-network contains approximately 4 billion parameters, with only 2% of total weights used at inference time.
Kimi K2 is specifically tuned for “agentic intelligence” - excelling at multi-step tasks involving tool use and external actions. It achieves 85.7% pass@1 on MultiPL-E (multilingual coding) and 89-93% on MMLU, rivaling closed models. The model uses a custom MuonClip optimizer to stabilize training of such an ultra-large MoE and features 128K context support.
DeepSeek R1 (2025)
DeepSeek R1 is a reasoning-optimized MoE model released in January 2025, building on DeepSeek’s V3 architecture with 671 billion total parameters and 37 billion active per token. What makes R1 unique is its training approach - it was primarily trained through reinforcement learning to excel at step-by-step logical reasoning, with minimal supervised fine-tuning.
This RL-first approach taught R1 to effectively generate and verify chains of thought, making it exceptionally capable at complex problem solving. The results are remarkable: 97.3% on the MATH benchmark, ~80% on AIME competition problems, and a Codeforces Elo rating of 2029 (expert programmer level). R1 essentially matches GPT-4’s performance on knowledge assessments while being fully open-source under MIT license.
DeepSeek V3.1 (2025)
DeepSeek V3.1, released in August 2025, represents the evolution of MoE into a truly hybrid system. Using the same 671B total/37B active architecture as R1, V3.1 introduces “hybrid thinking mode” - it can toggle between fast, direct responses and deep reasoning within a single model.
This is achieved through sophisticated prompt formatting and API flags that control whether the model enters “think mode” (producing chain-of-thought for complex tasks) or operates in fast mode for casual queries. V3.1 matches R1’s reasoning capabilities while significantly reducing latency through “chain-of-thought compression” - internalizing reasoning steps to solve problems with fewer output tokens.
The model excels at tool use and agent-based tasks, outperforming both its predecessors on evaluations requiring smart API invocation or web search integration. It supports 128K context natively and uses multi-head latent attention for efficient long-context handling.
OLMoE-1B-7B (2025)
OLMoE-1B-7B proves that MoE efficiency works at smaller scales. Developed collaboratively by HuggingFace and Allen Institute for AI, this model has 7 billion total parameters but only activates 1 billion per token - achieving 13B-level performance at 1B computational cost.
Using 7 experts with top-1 routing, OLMoE was trained on 5 trillion tokens (massive for its size) and outperforms much larger dense models like LLaMA2-13B on many benchmarks. The project is notable for complete transparency - releasing not just weights but all training data, code, and logs under permissive licenses.
The model demonstrates clear expert specialization, with each expert focusing on distinct topics or styles, providing valuable insights into how MoE routing naturally develops specialized capabilities.
2025 MoE Models Comparison
| Model | Total Params | Active Params | Key Features | MMLU Score | License |
|---|---|---|---|---|---|
| GPT-5 | - | - | Multimodal, expert specialization | - | Proprietary |
| GPT-OSS-120B | 117B | 5.1B | Dual thinking mode, 128K context | ~90% | Apache 2.0 |
| GPT-OSS-20B | 21B | 3.6B | Edge-optimized, runs on 16GB GPU | ~85% | Apache 2.0 |
| Qwen3-235B-A22B | 235B | 22B | Hybrid reasoning, 119+ languages | ~87% | Apache 2.0 |
| Kimi K2 | 1T | 32B | Agentic AI, tool use specialist | ~90% | Modified MIT |
| DeepSeek R1 | 671B | 37B | Reasoning-optimized via RL | ~91% | MIT |
| DeepSeek V3.1 | 671B | 37B | Hybrid think/no-think modes | ~89% | MIT |
| OLMoE-1B-7B | 7B | 1B | Ultra-efficient, full transparency | ~55% | Apache 2.0 |
These 2025 models demonstrate several key trends in MoE evolution:
Reasoning Integration: Models like GPT-OSS, Qwen3, and DeepSeek V3.1 can dynamically switch between fast responses and deep reasoning, giving users control over the compute-accuracy tradeoff.
Massive Scale: Kimi K2’s trillion parameters prove that MoE can scale to previously unimaginable sizes while remaining practical to run.
Open Source Dominance: All major 2025 MoE advances are open-source, democratizing access to state-of-the-art AI capabilities.
Specialized Training: DeepSeek R1’s RL-first approach and OLMoE’s transparency show how training methodology innovations are as important as architectural ones.
Benefits and Trade-offs
The Advantages
Computational Efficiency: MoE models can achieve the performance of much larger dense models while using significantly less computation per inference. This translates directly to lower costs and faster response times.
Scalability: You can scale MoE models to enormous sizes that would be impractical with dense architectures. Models with trillions of parameters become feasible when you’re only activating a small fraction at a time.
Specialization: Different experts naturally develop specializations during training, potentially leading to better performance on diverse tasks compared to a single dense model trying to handle everything.
The Challenges
Memory Requirements: While computation is sparse, you still need to store all the expert parameters in memory. A model with 8 experts of 7B parameters each still requires memory for all 56B parameters, even though you’re only using 13B at a time.
Routing Overhead: The gating network adds some computational overhead, and routing decisions need to be made for every token. For very small models or simple tasks, this overhead might outweigh the benefits.
Training Complexity: MoE models are significantly more complex to train than dense models. Load balancing, expert utilization, and routing stability all require careful tuning and monitoring.
Communication Costs: In distributed settings, routing tokens to different experts across different machines can create communication bottlenecks that don’t exist with dense models. This is particularly relevant for distributed training scenarios.
When Should You Use MoE Models?
Perfect Use Cases
Large-Scale Applications: If you’re building applications that need the capabilities of very large models but have computational budget constraints, MoE models offer an excellent efficiency trade-off. Models like Kimi K2 prove you can access trillion-parameter capabilities at 32B computational cost.
Multi-Domain Tasks: Applications that need to handle diverse types of content (code, creative writing, technical documentation, etc.) can benefit from MoE’s natural specialization. The 2025 models show clear expert specialization across different domains.
Cost-Sensitive Deployments: When inference costs are a major concern but you still need high-quality outputs, MoE models can provide better performance per dollar than dense alternatives. OLMoE-1B-7B demonstrates this at smaller scales.
Reasoning-Heavy Applications: With models like DeepSeek R1 and V3.1, MoE now excels at complex reasoning tasks while maintaining efficiency. The hybrid thinking modes let you choose when to invest in deep reasoning.
Agentic AI Systems: Models like Kimi K2 and DeepSeek V3.1 are specifically optimized for tool use and multi-step agent workflows, making them ideal for autonomous AI applications.
When Dense Models Might Be Better
Simple Tasks: For straightforward tasks that don’t require massive model capacity, the overhead of MoE routing might not be worth it.
Memory-Constrained Environments: If you have strict memory limits, a smaller dense model might be more practical than a larger MoE model.
Latency-Critical Applications: The routing decisions in MoE can add some latency, so ultra-low-latency applications might prefer optimized dense models.
Conclusion
2025 has established Mixture of Experts as the dominant architecture for state-of-the-art language models. With breakthrough models like OpenAI's GPT-5 and GPT-OSS series, Moonshot's trillion-parameter Kimi K2, and DeepSeek's reasoning-optimized models, MoE has proven to be the key to scaling AI capabilities efficiently.
Key 2025 innovations include hybrid reasoning modes, trillion-parameter scale at practical costs, and complete model transparency. For developers building AI applications today, MoE offers the optimal balance of performance, efficiency, and accessibility - making it the clear choice for next-generation AI systems.