USA, Europe, or China - Who has the best AI Models?
Updated on Jan 10, 2026 · 7 mins read
The AI world in 2026 has shifted dramatically. What was once a clear American lead has transformed into a fierce, high-stakes battle for supremacy. The gap has not just narrowed; in some areas, it has vanished completely.
The US remains the powerhouse of pure scale and multimodal integration, but 2026 has arguably been the year of China’s “efficiency revolution,” with models that rival the best from Silicon Valley at a fraction of the compute cost. Meanwhile, Europe has cemented its position as the global conscience of AI, shipping powerful open-weight models that prioritize privacy and compliance without sacrificing raw capability.
This isn’t just a race for higher numbers anymore it’s a clash of philosophies: American maximization, Chinese efficiency, and European sovereignty.
Summary
The global AI race in 2026 has new leaders and shocking upsets:
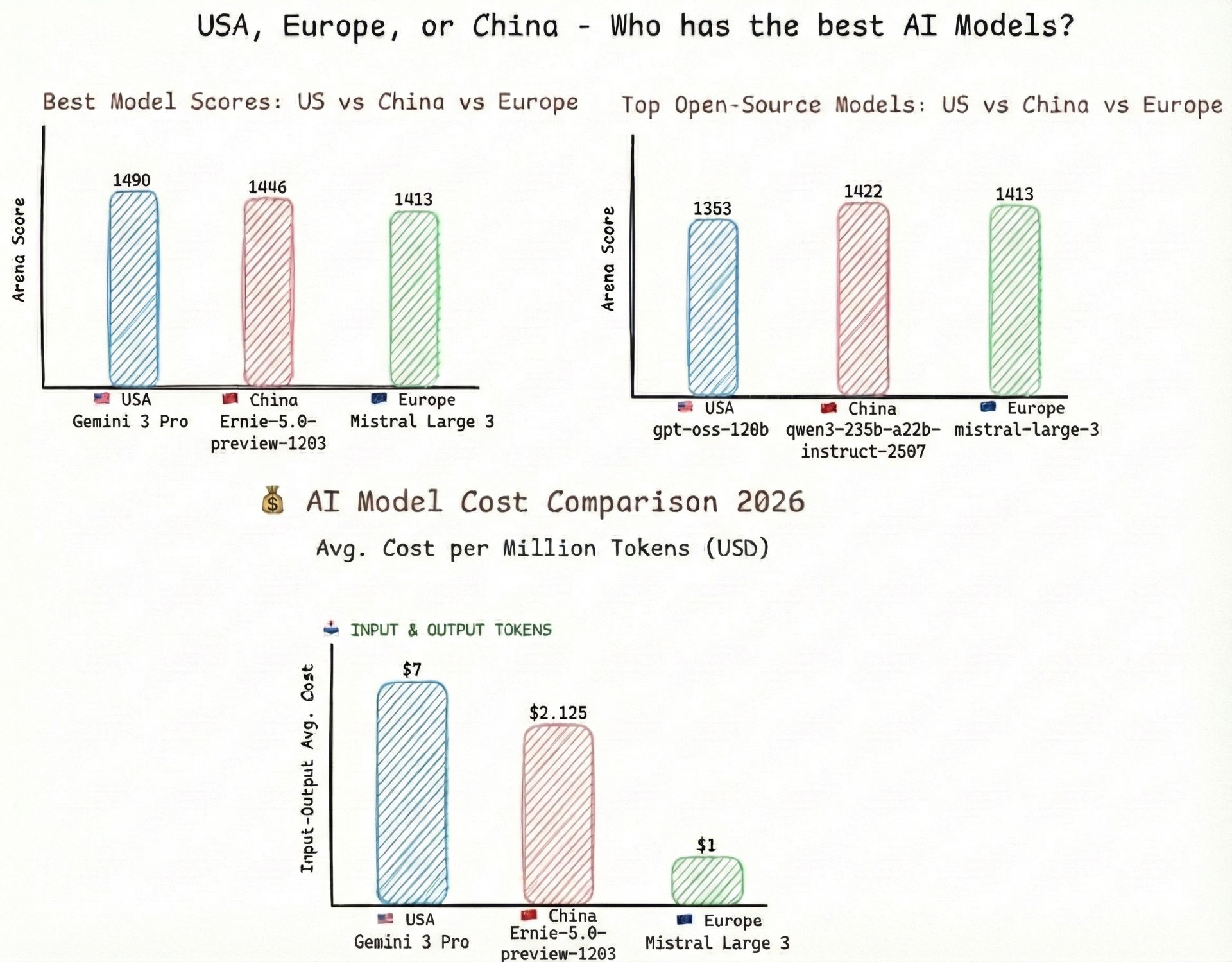
USA leads on the leaderboard with Gemini 3 Pro (1490 Arena score) taking the crown, followed closely by xAI’s Grok-4.1-Thinking (1477) and Claude Opus 4.5 (1469). GPT-5.1-high (1457) remains top-tier but faces stiff competition.
China surpasses major milestones with Ernie-5.0-preview (1446 Arena score) leading the regional pack, while deepseek-v3.2-exp (1423) offers incredible efficiency.
Europe closes the performance gap with Mistral Large 3 (1413 Arena score), offering near-GPT-5 performance in a privacy-compliant package.
Image generation remains a stronghold for the USA with DALL-E 3 and Midjourney v6.1, though China’s Kling AI and Europe’s Flux.1 Pro are gaining ground.
Video generation is a toss-up, with China’s Kling Video challenging OpenAI’s Sora on duration and consistency.
How the Global AI Race Actually Works in 2026
The narrative has shifted from “who is biggest” to “who is smartest per FLOP.”
America is still pushing the “thinking” models systems that pause to reason before answering to new heights. Google and xAI have invested heavily here, resulting in models that excel at complex scientific reasoning.
China, however, has perfected the art of architectural efficiency. DeepSeek and Alibaba have demonstrated that you don’t need infinite compute to build world class AI; you just need better math. Their “Speciale” and “Max” variants are now outperforming American models that cost ten times as much to train.
Europe continues to carve out the “enterprise-safe” niche. As the AI Act becomes fully enforceable, European models like Mistral are becoming the default choice for regulated industries worldwide.
USA: The Titans Clash
The American landscape in 2026 has expanded beyond the traditional “Big Three” (OpenAI, Google, Anthropic) to include a formidable fourth player: xAI. The competition is brutal, and for the first time, OpenAI is playing catch-up on the leaderboard.
The American Powerhouses
Arena scores typically track the updated LMArena leaderboard (Elo rating), reflecting millions of user votes.
| Model | Company | Arena Score | Key Strength | Best Use Case |
|---|---|---|---|---|
| Gemini 3 Pro | 1490 | Unmatched Reasoning | Scientific discovery & Multimodal | |
| Grok-4.1-Thinking | xAI | 1477 | Real-time knowledge | Live data analysis |
| Claude Opus 4.5 | Anthropic | 1469 | Nuanced Writing | Creative & Technical Coding |
| GPT-5.1-high | OpenAI | 1457 | Reliability | General purpose tasks |
Gemini 3 Pro has defined 2026 so far. Google’s massive infrastructure advantage finally paid off, delivering a model that doesn’t just “know” things but can actively “think” through complex problems better than any human expert in many fields.
The surprise entry is Grok-4.1. xAI’s access to real-time data and massive compute clusters has propelled them to the #2 spot, creating a model that feels more “live” and responsive to the current world state than its competitors.
Claude Opus 4.5 continues to be the developer’s darling. Its “thinking” variant (1469) performs exceptionally well on coding tasks, maintaining the safety and steerability Anthropic is known for.
China: Surpassing Expectations
2026 is the year the “China lag” myth died. Chinese models aren’t just “good enough” cheap alternatives anymore; they are legitimately challenging the absolute state-of-the-art. DeepSeek’s latest release sent shockwaves through the industry by outperforming GPT-5 on several key reasoning benchmarks.
Top Chinese Language Models
| Model | Company | Arena Score | Key Innovation |
|---|---|---|---|
| Ernie-5.0-preview-1203 | Baidu | 1446 | Mathematics & Coding |
| GLM-4.7 | Zhipu AI | 1443 | Academic Research | deepseek-v3.2-exp | DeepSeek | 1423 | Reasoning Efficiency |
Ernie-5.0-preview now leads the Chinese market with a score of 1446, showcasing Baidu’s relentless focus on mathematical reasoning. Meanwhile, deepseek-v3.2-exp (1423) proves that you don’t need the highest raw score to be a favorite for production environments where cost-efficiency is king.
GLM-4.7 (1443) continues to bridge the gap between academic research and industrial application, remaining a strong contender.
Europe: The “Sovereign” Alternative
Europe’s strategy remains focused on quality, privacy, and sovereignty. While they may not hold the #1 spot on the absolute leaderboard, their models are often the #1 choice for businesses that value data security and cost-predictability.
European AI Leaders
| Model | Company | Arena Score | Focus Area |
|---|---|---|---|
| Mistral Large 3 | Mistral AI | 1413 | Production-grade Enterprise |
| falcon-180b-chat | TII | 1148 | Open Source Scale |
Mistral Large 3 is a marvel of engineering. With an arena score of 1413, it sits comfortably in the upper echelon of improved LLMs, offering competitive performance for a fraction of the cost, all while being fully GDPR compliant and deployable on-premise.
The Open-Source Battlefield
While proprietary models grab the headlines, the real revolution is happening in open-weight models, where you can download and run state-of-the-art AI on your own hardware. 2026 has been the year where open-source finally caught up to closed-source.
Top Open-Source/Open-Weight Models
| Model | Region | Arena Score | Context Window | Best For |
|---|---|---|---|---|
| gpt-oss-120b | 🇺🇸 USA | 1353 | 1M | General Purpose & Multimodal |
| qwen3-235b-a22b-instruct-2507 | 🇨🇳 China | 1422 | 1M | Coding & Hard Logic |
| mistral-large-3 | 🇪🇺 Europe | 1413 | 128k | Efficiency & Edge Deployment |
USA (gpt-oss): The release of gpt-oss-120b (1353) marks a confusing but significant moment. While not the top scorer, its ecosystem integration is unmatched, though many developers are still debating its true “open” nature.
- China (Qwen3): Alibaba has stunned the research community. qwen3-235b-instruct (1422) isn’t just “good for open source”—it is actively contending with proprietary models. It is currently the highest-performing open-weights model in the world.
- Europe (Mistral): Mistral continues to dominate the “efficiency” metric. mistral-large-3 (1413) punches way above its weight class, outperforming many larger models on coding benchmarks like DevQualityEval.
This shift has created a “barbell” in the market: developers are either flocking to the absolute smartest API models (Gemini 3 Pro) or running highly capable open-weight models (Qwen/Mistral) locally. The middle ground—proprietary models that aren’t SOTA—is rapidly disappearing as open-source alternatives eat their lunch.
Image & Video: The Creative Frontier
The battle for creative AI is just as heated.
Global Image Generation Leaders
| Model | City/Region | Company | Specialty |
|---|---|---|---|
| GPT Image 1.5 | San Francisco, USA | OpenAI | Prompt Adherence & Text |
| Midjourney v7 | San Francisco, USA | Midjourney | Artistic Aesthetics |
| Flux 2 Max | Freiburg, Germany | Black Forest Labs | Photorealism & Speed |
| Kling AI Image | Beijing, China | Kuaishou | Cultural Context |
| Nano Banana Pro | Mountain View, USA | Consistency & Stock Photos |
Global Video Generation Leaders
| Model | City/Region | Company | Max Length | Innovation |
|---|---|---|---|---|
| Sora 2 | San Francisco, USA | OpenAI | 2+ minutes | Physics simulation & Audio |
| Runway Gen-4.5 | New York, USA | Runway ML | 30 seconds | Camera Control & Brushes |
| Kling 2.6 | Beijing, China | Kuaishou | 3 minutes | Cinematic Realism |
| Veo 3.1 | Mountain View, USA | 1 minute+ | Synchronized Audio | |
| Hailuo 2.3 | Shanghai, China | MiniMax | Variable | Physics & Motion |
San Francisco’s Sora 2 continues to revolutionize the field with physics-aware videos, simulating complex interactions like fluid dynamics and cloth physics with uncanny realism. Meanwhile, New York’s Runway Gen-4.5 has carved out a niche for professional filmmakers, offering granular controls like camera brushes and directors’ modes that allow for precise storytelling rather than just random generation.
On the other side of the Pacific, Beijing’s Kling Video has stunned the industry by beating Sora on pure duration, generating up to 3 minutes of coherent footage in a single shot. This “brute force” scaling approach from China complements the more specialized, tool-focused approach of American startups, while Google’s Veo 3.1 bridges the gap with its unmatched native audio synchronization.
The Benchmark Reality Check (2026 Edition)
| Metric | USA | China | Europe | Winner |
|---|---|---|---|---|
| Top Arena Score | 1490 (Gemini 3 Pro) | 1446 (Ernie-5.0) | 1413 (Mistral Large 3) | 🇺🇸 USA |
| Reasoning (Math/Code) | Extreme | Very High | High | 🇺🇸 USA |
| Cost Efficiency | Expensive | Very Cheap | Balanced | 🇨🇳 China |
| Privacy & Safety | Variable | Low | Strict | 🇪🇺 Europe |
Conclusion
The 2026 AI landscape is no longer a monopoly. It is a diverse ecosystem. If you need the absolute smartest “brain” on the planet, Gemini 3 Pro (USA) is your choice. If you need 99% of that intelligence at 10% of the cost, Ernie-5.0 and deepseek-v3.2 (China) are unbeatable. And if you need a reliable, compliant partner for sensitive European data, Mistral Large 3 (Europe) is the gold standard.
For readers who want to explore different AI tools categorized by use case whether for coding, images, or business applications resources like this directory of AI tools can be a good starting point.