Forward Ollama Port 11434 for Online Access: Complete Guide
Updated on Sep 18, 2025 · 5 mins read
Running AI models locally with Ollama gives you complete control over your data and inference, but what happens when you need to access these models remotely? Whether you’re working from different locations, collaborating with team members, or integrating AI into web applications, forwarding Ollama’s default port 11434 is the key to unlocking remote access to your local AI models.
This comprehensive guide will show you exactly how to forward Ollama’s port 11434 to make your local AI models accessible online using secure tunneling. You’ll learn the most effective methods to expose your Ollama API without compromising security or performance.
Summary
Start Ollama Server
- Ollama runs on port
11434by default:ollama serve
- Ollama runs on port
Forward Port 11434 with Pinggy
- Create secure tunnel for remote access:
ssh -p 443 -R0:localhost:11434 -t qr@free.pinggy.io "u:Host:localhost:11434"
- Create secure tunnel for remote access:
Get Public URL
- Access your Ollama API via generated URL (e.g.,
https://abc123.pinggy.link).
- Access your Ollama API via generated URL (e.g.,
Test Remote Access
- Verify API works remotely:
curl https://abc123.pinggy.link/api/tags
- Verify API works remotely:
Why Forward Ollama Port 11434?
Understanding Ollama’s Default Configuration
Ollama automatically binds to port 11434 on localhost, making it accessible only from your local machine. This default behavior ensures security but limits functionality when you need remote access. By forwarding port 11434, you can:
- Access models from anywhere with an internet connection
- Integrate AI into web applications running on different servers
- Share models with team members without complex VPN setups
- Test applications remotely before deploying to production
- Enable mobile app integration with your local AI models
Benefits of Port Forwarding vs Cloud Deployment
Unlike deploying to cloud services, forwarding port 11434 offers:
- Zero cloud costs - keep everything running locally
- Complete data privacy - your data never leaves your infrastructure
- Full model control - use any model without platform restrictions
- Instant deployment - no complex cloud configurations required
Prerequisites for Forwarding Ollama Port 11434
Install and Configure Ollama
First, ensure Ollama is properly installed and configured:
- Download Ollama: Visit ollama.com and install for your operating system
- Verify Installation:
ollama --version
Download Your First Model
Before forwarding the port, download a model to test with:
ollama run qwen:0.5b

For more powerful models, try:
ollama run llama3:8b
# or for multimodal capabilities
ollama run llava:13b
Step-by-Step Guide: Forward Ollama Port 11434
Step 1: Start Ollama Server
Ensure Ollama is running on its default port:
ollama serve
Keep this terminal window open - Ollama needs to stay running to handle API requests.
Step 2: Create Secure Tunnel for Port 11434
Use Pinggy to create a secure tunnel that forwards port 11434:
ssh -p 443 -R0:localhost:11434 -t qr@free.pinggy.io "u:Host:localhost:11434"
Understanding the Command:
-p 443: Uses HTTPS port for better firewall compatibility-R0:localhost:11434: Forwards your local port 11434 to a random remote portqr@free.pinggy.io: Pinggy’s tunneling server with QR code supportu:Host:localhost:11434: Maps the tunnel to your Ollama server

Step 3: Get Your Public URL
After running the command, Pinggy will provide a public HTTPS URL like https://abc123.pinggy.link. This URL now forwards all requests to your local Ollama server on port 11434.
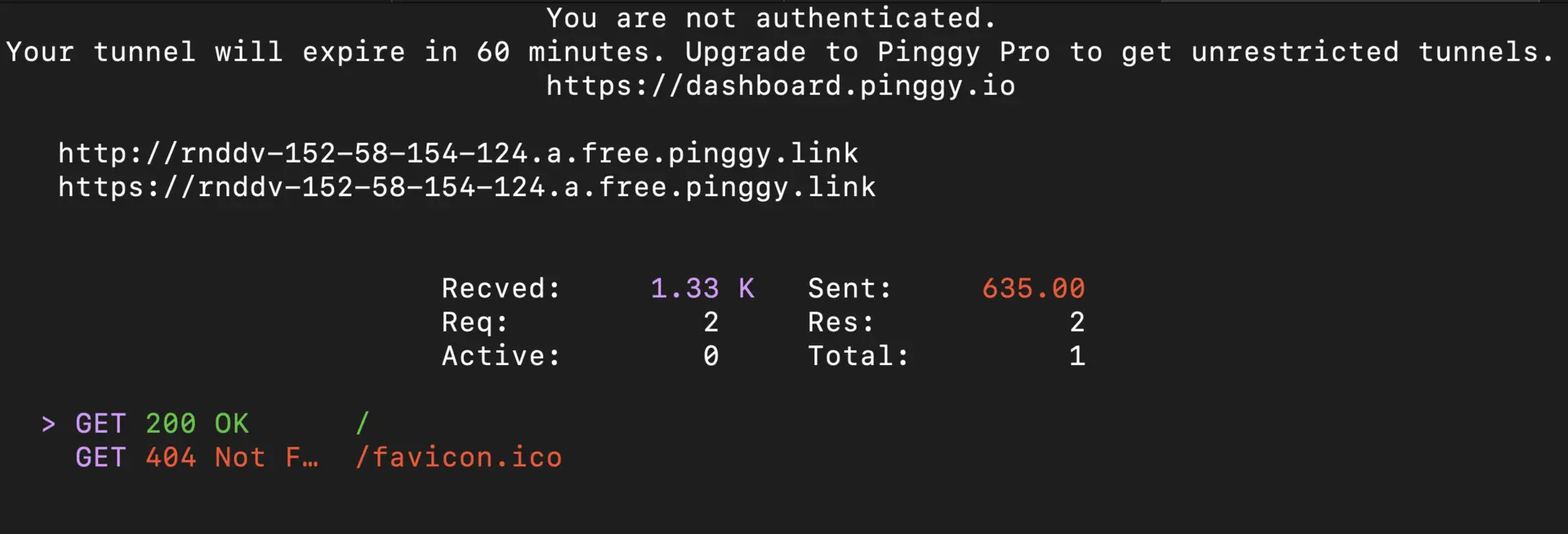
Testing Your Forwarded Ollama Port 11434
Verify Ollama is Running Remotely
Once your tunnel is established, you can verify that Ollama is accessible through your forwarded port:
Browser Verification: Open your browser and navigate to the public URL provided by Pinggy (e.g.,
https://abc123.pinggy.link). You should see Ollama running and responding, confirming that port11434is successfully forwarded.
Command Line Testing: Test the API endpoints using curl commands:
# Check if Ollama is responding curl https://abc123.pinggy.link/api/version # List available models curl https://abc123.pinggy.link/api/tagsTest Model Inference: Once you confirm Ollama is accessible, test actual model inference:
curl -X POST https://abc123.pinggy.link/api/generate \ -H "Content-Type: application/json" \ -d '{"model": "qwen:0.5b", "prompt": "Hello, world!", "stream": false}'
Integration Testing
To test the forwarded Ollama API in your applications, follow these steps:
- Clone the test repository: RunOllamaApi
- Install dependencies:
npm install - Update the API URL: Replace the localhost URL in the code with your Pinggy URL (e.g.,
https://abc123.pinggy.link) - Run the test:
node main.js
This repository provides complete examples of how to integrate and test your forwarded Ollama API with JavaScript applications.
Adding Open WebUI to Your Forwarded Ollama Setup
Now that you have Ollama’s port 11434 forwarded and accessible online, you can enhance the experience by adding Open WebUI for a ChatGPT-like interface:
Quick Open WebUI Setup:
- Install Open WebUI:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main - Forward WebUI Port:
ssh -p 443 -R0:localhost:3000 free.pinggy.io - Access WebUI: Use the generated URL to access your ChatGPT-like interface
- Connect to Ollama: Configure WebUI to use your forwarded Ollama API URL
Why Add Open WebUI:
- User-Friendly Interface: ChatGPT-like chat interface for your models
- Document Upload: RAG capabilities for document-based conversations
- Model Management: Easy switching between different Ollama models
- Collaboration: Share the WebUI URL with team members for easy access
Complete Setup:
For detailed instructions on setting up both Ollama API and Open WebUI together, check out our comprehensive guide: How to Easily Share Ollama API and Open WebUI Online.
This combination gives you both programmatic API access (via forwarded port 11434) and a user-friendly web interface for interacting with your local AI models.
Conclusion
Forwarding Ollama’s port 11434 opens up a world of possibilities for remote AI model access. Whether you’re building applications, collaborating with team members, or simply need access to your models from different locations, this approach provides a secure and efficient solution.
The combination of Ollama’s powerful local inference capabilities with Pinggy’s secure tunneling creates an ideal setup for developers who want the benefits of cloud accessibility without sacrificing data privacy or incurring cloud costs.
Remember to always implement proper security measures when exposing your local services online, and consider upgrading to professional tunneling solutions for production use cases.